Brian Dellabetta's contributions

Article
LLM Compressor 0.9.0: Attention quantization, MXFP4 support, and more
Explore the latest release of LLM Compressor, featuring attention quantization, MXFP4 support, AutoRound quantization modifier, and more.
Article
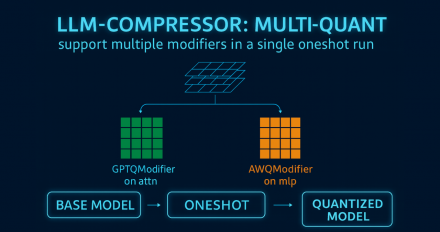
LLM Compressor 0.8.0: Extended support for Qwen3 and more
The LLM Compressor 0.8.0 release introduces quantization workflow enhancements, extended support for Qwen3 models, and improved accuracy recovery.

Article
LLM Compressor 0.7.0 release recap
LLM Compressor 0.7.0 brings Hadamard transforms for better accuracy, mixed-precision FP4/FP8, and calibration-free block quantization for efficient compression.
 Video
Video
Smarter compression: Tailoring AI with LLM Compressor in OpenShift AI
In this recording, we demonstrate how to compose model compression experiments, highlighting the benefits of advanced algorithms requiring custom data sets and how evaluation results and model artifacts can be shared with stakeholders.

Article
Optimize LLMs with LLM Compressor in Red Hat OpenShift AI
Optimize model inference and reduce costs with model compression techniques like quantization and pruning with LLM Compressor on Red Hat OpenShift AI.

LLM Compressor 0.9.0: Attention quantization, MXFP4 support, and more
Explore the latest release of LLM Compressor, featuring attention quantization, MXFP4 support, AutoRound quantization modifier, and more.

LLM Compressor 0.8.0: Extended support for Qwen3 and more
The LLM Compressor 0.8.0 release introduces quantization workflow enhancements, extended support for Qwen3 models, and improved accuracy recovery.

LLM Compressor 0.7.0 release recap
LLM Compressor 0.7.0 brings Hadamard transforms for better accuracy, mixed-precision FP4/FP8, and calibration-free block quantization for efficient compression.
Smarter compression: Tailoring AI with LLM Compressor in OpenShift AI
In this recording, we demonstrate how to compose model compression experiments, highlighting the benefits of advanced algorithms requiring custom data sets and how evaluation results and model artifacts can be shared with stakeholders.

Optimize LLMs with LLM Compressor in Red Hat OpenShift AI
Optimize model inference and reduce costs with model compression techniques like quantization and pruning with LLM Compressor on Red Hat OpenShift AI.