Agentic coding tools help developers build software efficiently. Claude Code, Anthropic's terminal-based coding agent, improves productivity by letting you interact with your codebase through natural language—directly from the console.
One advantage of Claude Code is its flexibility. Rather than being locked to Anthropic's cloud models, you can connect it to any backend that uses the Anthropic Messages API.
This article explores how to integrate Claude Code with a local model served by Red Hat AI Inference Server (a downstream version of vLLM) on Red Hat OpenShift. This approach keeps the inference process private on your infrastructure while retaining the full Claude Code workflow. By doing so, you keep all prompts and responses within your environment while benefiting from Claude Code's developer-focused workflows.
Prerequisites
You will need:
- An OpenShift cluster with GPUs enabled and the NVIDIA Operator installed. For a local OpenShift installation, follow the steps in How to enable NVIDIA GPU acceleration in OpenShift Local.
- A Hugging Face account and active API token.
- Access to the Red Hat image registry.
Environment
I executed the steps in this article using an environment with the following specifications:
- Single-node OpenShift 4.21
- GPU: NVIDIA RTX 4060 Ti
- CPU: Intel Core i7-14700 × 28
- Host machine operating system: Fedora 43
Disclaimer
Because this testing machine is not part of a supported environment, this demo is for testing only and does not represent an official Red Hat support procedure.
Deploy the Red Hat AI Inference Server
The first step is to deploy Red Hat AI Inference Server. For this demo, I created a Helm chart to simplify the deployment in an OpenShift 4.21 environment. You can alternatively follow the manual deployment procedure.
Clone the project:
git clone https://github.com/alexbarbosa1989/rhai-helmSet the minimal required environment variables:
export HF_TOKEN=hf_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
export AUTHFILE=$XDG_RUNTIME_DIR/containers/auth.json
export STORAGECLASS=<ocp-storageclass>Alternatively, you can configure your own values in the rhai-helm/values.yaml file—for example, a different model from Hugging Face or a custom namespace.
Hint: Before setting AUTHFILE, verify whether auth.json already exists at the expected path. This file is created automatically when you authenticate using Podman in the terminal.
podman login registry.redhat.ioOnce you define the required environment variables, you can install the Helm chart. For example, to use the default rhai-helm/values.yaml, run:
helm install rhai-helm ./rhai-helm \
--create-namespace --namespace rhai-helm \
--set persistence.storageClass=$STORAGECLASS \
--set secrets.hfToken=$HF_TOKEN \
--set-file secrets.docker.dockercfg=$AUTHFILECheck the created resources:
oc get secrets
oc get pvc model-cache
oc get deployment
oc get svc
oc get routeFinally, check the running pod. This might take a few minutes, depending on hardware resources.
oc get podNAME READY STATUS RESTARTS AGE
qwen-coder-5f6668b767-hp585 1/1 Running 0 5m11sInstall and configure Claude Code
Configure this on your developer workstation. Follow the official installation instructions, or install it directly using the convenience script for Linux and macOS:
curl -fsSL https://claude.ai/install.sh | bashClaude Code uses environment variables for configuration. By overriding the default Anthropic settings, you can redirect requests to a local model served by vLLM. Use this example configuration:
ANTHROPIC_BASE_URL="<RHAI-Inference-exposed-route>" \
ANTHROPIC_API_KEY="vllm" \
ANTHROPIC_DEFAULT_OPUS_MODEL="qwen-coder" \
ANTHROPIC_DEFAULT_SONNET_MODEL="qwen-coder" \
ANTHROPIC_DEFAULT_HAIKU_MODEL="qwen-coder" \
CLAUDE_CODE_FILE_READ_MAX_OUTPUT_TOKENS="2000" \
CLAUDE_CODE_MAX_OUTPUT_TOKENS="4096" \
MAX_THINKING_TOKENS="0" \
claudeThe ANTHROPIC_BASE_URL environment variable must point to the exposed OpenShift route of the Red Hat AI inference service. This is the endpoint Claude Code uses for all requests.
Replace the example value with the route generated in your OpenShift cluster. Retrieve the route by running:
oc get route -n <namespace>Also, the values for CLAUDE_CODE_FILE_READ_MAX_OUTPUT_TOKENS and CLAUDE_CODE_MAX_OUTPUT_TOKENS should be tuned according the hardware capabilities to avoid exhausting the context window.
Once you set the environment variables, launching Claude Code prompts an interactive setup to initialize the workspace (Figure 1).
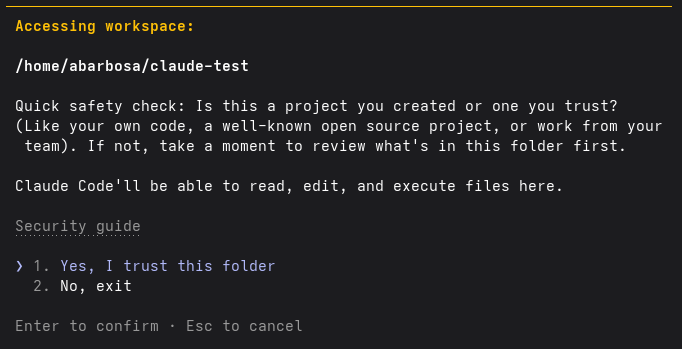
Select ❯ 1. Yes, I trust this folder. At this point, Claude Code is fully initialized and ready for use, as shown in Figure 2.
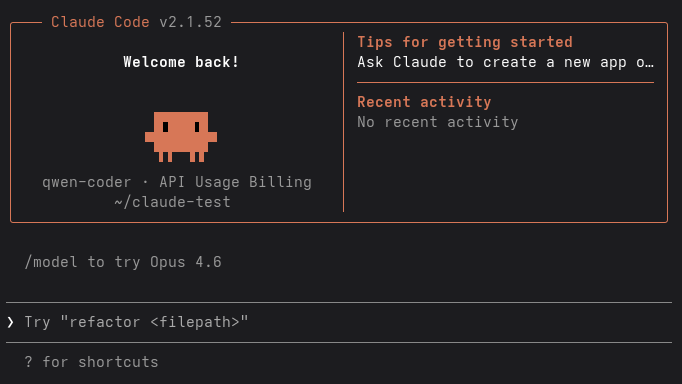
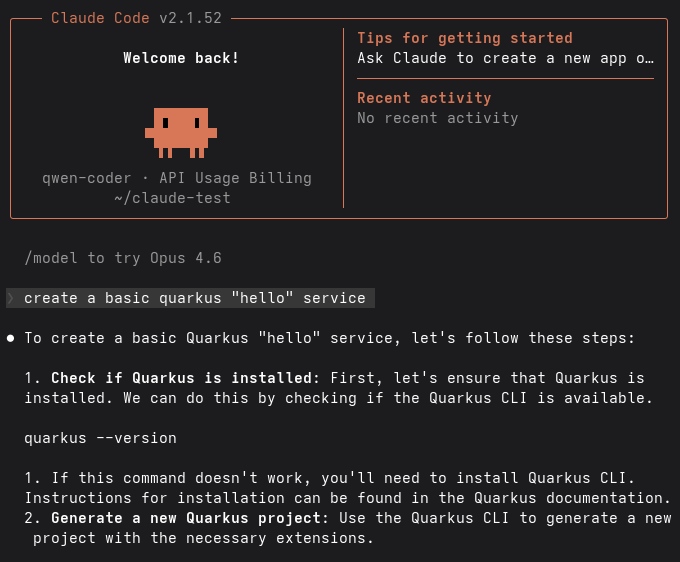
In this example, the following instruction was provided:
❯ create a basic quarkus "hello" serviceClaude Code immediately begins processing the request using the locally served model, as illustrated in Figure 3.
You can also verify the interaction directly from the vLLM backend pod in the OpenShift cluster. Successful requests appear in the logs as calls to the /v1/messages API endpoint:
(APIServer pid=1) INFO: 10.128.0.2:43662 - "POST /v1/messages?beta=true HTTP/1.1" 200 OK
(APIServer pid=1) INFO: 10.128.0.2:43664 - "POST /v1/messages?beta=true HTTP/1.1" 200 OKThis confirms that Claude Code successfully routes requests to the OpenShift-hosted inference service.
Key takeaways
By integrating Claude Code with a vLLM-based inference service on OpenShift, you gain access to effective AI-assisted coding workflows while keeping models, data, and inference under your control.
This demonstration uses a lightweight Qwen model. With specialized, higher-performance hardware, you can serve larger models that provide advanced coding and reasoning capabilities.
Overall, this approach combines the productivity of Claude Code with the security and scalability of OpenShift. It is a practical solution for organizations that need private, on-premises AI development environments.