Training Hub is an open source Python package that lets you fine-tune a pre-trained language model on a dataset of your choice, It is available as an open source package hosted on PyPI, and a downstream build is available on the Red Hat Python Index for use in Red Hat OpenShift AI workbenches as part of Red Hat AI 3.0. While language models are already powerful out of the box, fine-tuning a model on your dataset can improve its ability to handle specific tasks, making it more reliable for your business needs.
However, fine-tuning a model requires significantly more memory than inference. Launching fine-tuning experiments without planning can be a significant waste of GPU hours and team resources if they encounter an out-of-memory error. Using a GPU setup with more memory than necessary is also inefficient, in which case you might prefer to use smaller, more cost-effective GPUs that still support your fine-tuning process. A memory estimator can calculate the amount of memory required for a given fine-tuning experiment, helping you quickly find the most efficient GPU setup, training method, and hyperparameters.
Starting with Red Hat OpenShift AI 3.0, Training Hub includes memory_estimator.py, an API that allows you to estimate how much memory you can expect to be used for your given fine-tuning setup. With this information, you can train your model efficiently and avoid manual testing to determine whether your hardware can handle the workload.
This blog covers:
- How the estimator works and which training components to adjust.
- Suggestions for adjusting your training setup to fit specific GPU specifications.
- How to use the memory estimator in your code.
- Next steps for streamlining model fine-tuning, including runtime estimates and automated hyperparameter suggestions.
How to estimate memory usage
Note
Research into language model memory usage is still evolving. This information might change as we improve Training Hub's estimation tools and our understanding of memory allocation during fine-tuning.
You can approximate memory usage by looking at several components. By default, Training Hub stores data as Float32, which occupies 4 bytes.
Model memory is the amount of memory required to deploy the model on a GPU.
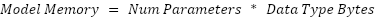
Gradient memory is the memory needed to store the neural network gradients during backpropagation.
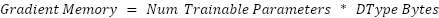
Optimizer memory is the memory needed to store optimizer states, which is based on the size of the gradient memory. AdamW, the most common optimizer for LLMs, uses two parameters.
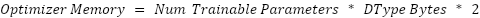
Activation memory is the memory needed for intermediate activations across each neural network layer. You can estimate it using this formula:
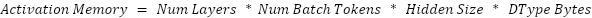
Note that some sources multiply this value by a constant K. For example, this article on calculating VRAM requirements suggests K should be 10-30. Other GPU memory estimation guides note that activation memory is proportional to the right side. In our testing, we found the best results by assuming the values are equal rather than proportional.
Output memory is the GPU memory required to store the network's final output. This is primarily constrained by the model’s vocabulary size.
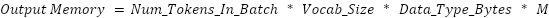
The constant M varies depending on the training method. It is typically a float between 1 and 3. For SFT, this value is set to 8/3 and for OSFT, this value is set to 7/3.
To account for any discrepancies in the final total, you can apply an Overhead multiplier to the subtotal to provide a range of values. Of course, tight bounds are ideal. In Training Hub, we consider an overhead of up to 1.3x.
Figure 1 shows the memory allocation during the first few steps of fine-tuning Granite 2B on SFT. The green area represents parameter memory. The yellow area is the optimizer memory, which is roughly twice the size of the parameter memory. The blue area is gradient memory, which is approximately the same size as the parameter memory. The slanted gray area is activation memory, and the brief gray spikes show output memory.

Supervised Fine-Tuning (SFT)
Standard SFT uses a simple formula that sums these components:
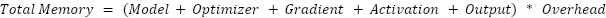
LoRA and QLoRA
LoRA and QLoRA are alternative fine-tuning methods that aim to be more memory efficient. Unlike SFT and OSFT, LoRA mostly stores data in Float16, which uses 2 bytes and takes a rank parameter, r. For each weight matrix of size W_in x W_out, LoRA forms two matrices of size W_in x r and r x W_Out to approximate the weight’s update.
Ab_params = 0for weight in model_weights: Lora_matrix_a_size = weight.dim[0] * r Lora_matrix_b_size = weight.dim[1] * r Ab_params += ((lora_matrix_a_size) + (lora_matrix_b_size))The rank r is a constant much lower than W_In and W_Out. For example, using a value of 16 results in much lower total memory usage. This changes the formulas to:
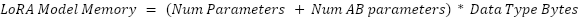
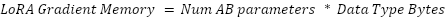
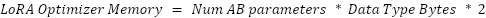
In LoRA, gradient and output allocations typically do not coexist. The maximum allocated memory is determined by whichever is larger: the gradient or the output memory size. The final formula is:
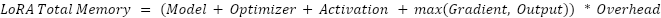
QLoRA is similar to LoRA, but the model is quantized to Float4 instead of Float16 to save more memory. However, you must place the unquantized model on the GPU before quantization. This can create a memory bottleneck for small r values.
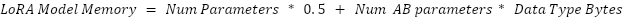
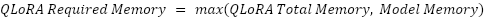
Orthogonal Subspace Fine-Tuning (OSFT)
Note
This information is not reflected in Training Hub 0.5.0 (part of Red Hat AI 3.3). The estimator will be updated in a future release.
OSFT is a method that creates models capable of multiple tasks by freezing model weights during training. Similar to LoRA, OSFT uses additional matrices to approximate weight matrices during computation. Each weight matrix is replaced by three matrices: U, S, and V. For a weight matrix of size M x N, U is size M x min(M, N), S is size min(M, N), and V is size min(M, N) x N:
OSFT_params = 0for weight in model_weights: low_dim = min(weight.dim[0], weight.dim[1]) U_size = weight.dim[0] * low_dim S_size = low_dim V_size = weight.dim[1] * low_dim OSFT_params += (U_size + S_size + V_size)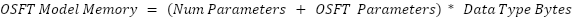
Liger kernels
When you are using a method that uses Liger kernels, such as OSFT, the expensive output tensors on the GPU, which instead gives you the formula of:
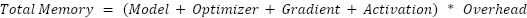
How to reduce memory usage
If your training setup exceeds your available VRAM, there are several strategies to lower memory requirements.
Change your model
Choosing a model with fewer parameters reduces the memory requirements for most fine-tuning components. Note that the model's vocabulary size also affects memory usage, depending on whether you use Liger kernels.
Change your training method
Training Hub’s implementation of OSFT uses Liger kernels to reduce memory usage. These kernels prevent output tensors from being stored on the GPU, which lowers VRAM for larger models. LoRA also improves efficiency by using matrices that are smaller than the main model. To reduce LoRA’s memory usage further, decrease the rank size (lora-r) or use QLoRA. Your GPU must still be large enough to support the unquantized mode during the initial setup.
Adjust your hyperparameters
Reducing the number of tokens placed on the GPU is an effective way to lower memory usage, especially for models with large output memory allocations. You can do this by lowering the batch_size or max_tokens_per_gpu parameters.
Why not quantize your model?
Quantization is not recommended for SFT and OSFT. You will achieve better model performance by training without quantization and then quantizing the model for inference after fine-tuning. If you use LoRA, consider QLoRA, it quantizes the model during training to reduce memory requirements.
How to use the memory estimator
To get started with the memory estimator, use the editable example notebook, memory_estimator_example.ipynb (Figure 2). This notebook includes estimators for SFT and OSFT.

Each fine-tuning method has an associated estimator class: BasicEstimator (for SFT), OSFTEstimator, LoRAEstimator, and QLoRAEstimator. You can import these into your notebook to use them. You can create an instance of these classes and provide inputs such as:
num_gpus: The number of GPUs in the training setup.gpu_memory: The memory (in bytes) for each GPU.model_path: The path to the model being fine-tuned. This should be a Hugging Face repository link.- The highest number of tokens on each GPU. For SFT and OSFT, use the
max_tokens_per_gpuparameter. Alternatively, you can provide bothbatch_sizeandmax_seq_len. The memory estimator then calculates the maximum token count as the product of these values. verbose: Controls how much information the estimator prints.- OSFT and LoRA have method-specific hyperparameters that affect memory estimation, such as
lora_rfor LoRA andunfreeze_rank_ratiofor OSFT.
estimator = BasicEstimator(num_gpus=num_gpus, gpu_memory=gpu_memory, model_path=model_path, max_tokens_per_gpu=max_tokens_per_gpu, verbose=2)After creating the object, call the estimate method to perform the calculation.
low_bound, expected, high_bound = estimator.estimate()Alternatively, you can skip the object instantiation by using the estimate convenience function provided by memory_estimator.py. Provide your parameters and training method (as a string) to receive the estimated results.
low, expected, high = estimate(training_method="sft", num_gpus=num_gpus, gpu_memory=gpu_memory, model_path=model_path, max_tokens_per_gpu=max_tokens_per_gpu, verbose=2)When the estimation finishes, the output includes the lower bound, upper bound, and expected memory values. If you set the verbose value to 1 or 2, the printed output indicates whether the training setup works on your hardware (num_gpus and gpu_memory). For example, you receive the following output for verbose=2 when training Granite 3.3 2B on two 48 GB GPUs, such as L40s:
Estimations for ibm-granite/granite-3.3-2b-instruct:
Summary:
The expected amount of memory needed to run this model is about 55.8 GBThe lower and upper bounds are 50.8 - 66.0 GBIf you have 2 GPUs, you will need about 27.9 GB, with bounds of 25.4 - 33.0 GB per GPU
Component Breakdown:
Each GPU will need 4.7 GB to store the model parametersEach GPU will need 9.4 GB to store the optimizer statesEach GPU will need 4.7 GB to store the gradientsEach GPU will need 2.5 GB to store the intermediate activationsEach GPU will need 4.0 GB to store the outputsUp to 7.6 GB can be expected as overhead
Decision:
The proposed training setup should work for your hardware.What's next?
We are planning and developing several new features to further simplify the fine-tuning workflow and help you plan your resources more effectively.
Time estimations
Estimating model runtime is harder than estimating memory. Many factors determine how long a program runs, and the results are not always predictable. However, knowing this information is still very helpful for planning the number of hours you’ll need to use your GPUs.
We are exploring options for creating a fine-tuning time estimator. In the meantime, our wiki page provides guidelines on how long common fine-tuning processes should take.
Hyperparameter suggestions and hardware discovery
Because the estimator is a hard-coded algorithm and memory allocation depends on hyperparameter settings, we are developing a system that recommends a set of hyperparameters based on your hardware and model. We plan to include a hardware discovery feature that automatically detects your GPU configuration and determines if training is possible. We also plan to recommend model sizes and training methods based on your hardware and use case.
Conclusion
Fine-tuning is an effective way to create an inference model for a specific task, and Red Hat AI’s Training Hub provides a simple way to manage the process. If you have concerns about the memory required for fine-tuning, the memory estimator in Training Hub provides an estimate in advance so you can adjust your training or hardware setup.
To get started with the memory estimator, install the latest version of Training Hub and run the provided example notebooks.
Training Hub is versioned and supported on Red Hat AI through the Red Hat Python Index. It also integrates with Kubeflow Trainer for distributed training workloads.
Acknowledgements
Huge thanks to the Red Hat AI Innovation Team and other Training Hub members for their help developing this tool, including Mustafa Eyceoz, Oleg Silkin, and Aditi Saluja. I am also grateful to the reviewers who helped shape this blog.