Application migration is a constrained graph traversal problem masquerading as a coding task. You're not just rewriting code—you're translating dependencies, reshaping architectural patterns, and maintaining behavioral equivalence across fundamentally different runtimes. This is why migrations often fail: developers treat them as glorified find-and-replace operations instead of multi-constraint optimization problems.
Coding agents (OpenCode, Claude, open source alternatives) can handle this kind of work, but not the way most people use them. Asking an AI to migrate a Spring Boot application to Quarkus without giving it context is like asking for directions without providing a map. The agent needs structure: a knowledge graph of your codebase, a constraint system for the target platform, and a task decomposition that maintains dependency order.
This post walks through how I built a group of skills and agents that combine graph analysis, automated planning, and parallel execution. I migrated a Spring Boot REST API to Quarkus, deployed it to OpenShift, and got it working in about 40 minutes—fully automated. Here's how it works. Although it should be possible to migrate almost any application, I demonstrate a classic Spring to Quarkus example.
The blog post describes the demo project MigIQ, which supports more than 30 languages, uses Graphify for knowledge and semantic graphs. The following diagram shows the overall orchestration flow. For our example we prompt:
/migiq migrate this appliction to QuarkusThe overall platform architecture and coordination between human inputs and automated components are illustrated in Figure 1.

This setup uses one agent and one orchestrator skill working together in a flow. Let's examine the problem space and how to solve it.
The migration problem space
Traditional migration approaches fail for three primary reasons.
First, they lack dependency awareness. You cannot migrate a controller before transforming its repository, meaning an agent must fully map the call graph to understand the order of cascading file changes.
Second, framework semantics are rarely transferable. Spring's @Autowired annotation is not just syntactic shorthand for CDI's @Inject; the underlying injection lifecycles, scoping rules, and transaction behaviors differ fundamentally. Without this context, an agent will generate code that compiles cleanly but crashes at runtime.
Finally, migrations suffer from a broken validation loop. Code generation itself is simple, but making that code work in a production environment requires continuous compile-test-fix cycles rather than one-shot transformations.
In this demo project, I address these challenges by breaking migration into five phases: analysis, requirements, planning, execution, and reporting. Each phase produces artifacts the next phase consumes. No human intervention is required unless something breaks. The automation engine segmentally addresses code transformations by breaking the migration lifecycle into distinct areas, as shown in Figure 2.

Phase 1: Code analysis with knowledge graphs
You might have heard this before, but it's important: knowledge is everything. To create meaningful outcomes, software teams must provide agents and large language models (LLMs) with structural context. This is exactly what we want to do with code bases. We need a source graph. For this process, we use a graph-based analysis tool built on the Graphify framework to extract three components:
- Entity graph: Classes, methods, fields, and their relationships
- Dependency graph: Who calls what, who imports what
- Community detection: Clusters of related code (often architectural layers)
For our Spring Boot demo application, the graph found 40 nodes (classes, methods, key concepts) and 35 edges. The community detection algorithm identified seven clusters—unsurprisingly, these mapped to layers: controllers, services, repositories, and models.
Hub Nodes (most connected):
Product - 9 edges (domain model)
ProductController - 6 edges (REST layer)
ProductService - 6 edges (business logic)
Application - 2 edges (entry point)The hub nodes tell you what code is most coupled. When migrating, these are your critical path—get Product wrong, and you break everything downstream.
The graph also flags betweenness centrality, which highlights nodes that bridge separate communities. ProductService scored 0.116, meaning it's the main connection between the controller layer and persistence layer. The agent knows to treat this file carefully—changes here ripple outward. Under the hood, Graphify uses TreeSitter and supports more than 30 languages. The initial structural analysis extracts a comprehensive layout map of semantic intersections and coupling edges, which you can see in Figure 3.
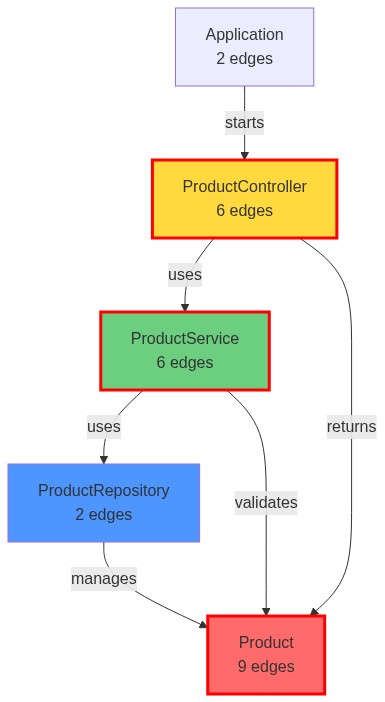
The analysis identified the critical path: Product → ProductRepository → ProductService → ProductController. The migration must follow this exact sequence.
Once this graph-based knowledge is generated, it assists with several subsequent tasks. The specific skills listed below use the output of mig-graphify to improve overall migration quality. Accuracy increases because the tool maps dependencies, services, and endpoints. This architectural context helps the agent and the LLM complete precise transformations.
mig-plan/: Task decomposition and dependency planningmig-execute/: Parallel execution enginemig-test-gen/: Generate Unit testsmig-containerize/: To containerize the applicationmig-deploy/: Deployment to OpenShiftmigiq/: Orchestration layer
Phase 2: Requirements gathering
The agent can't guess target platform constraints. In interactive mode, MigIQ's prompt builder interviews the user. In autonomous mode, it automatically extracts the context to create a prompt for other skills to use:
- Source technology: Spring Boot 2.7.0
- Target technology: Quarkus 3.10.0
- Deployment target: Red Hat OpenShift
- Migration strategy: Big Bang (full rewrite) versus Strangler Fig (incremental)
- Constraints: Must use Panache for persistence, must containerize with UBI images, must include health checks
This process produces a structured migration-prompt.md file that becomes the planning input. No more ambiguity about the target Quarkus version or the choice between Hibernate and Panache.
Phase 3: Task decomposition and dependency planning
Next, the agent builds a dependency graph of the migration itself instead of just listing tasks. It relies on the graph analysis from the first phase to make sure the migration plan stays aligned. The agent also recognizes that testing and deployment are critical parts of this migration.
Guiding principle: Don't leave the user in the middle of a project. Avoid a situation where you migrate an application but do not know what step to take next. Instead, the goal is to have the application running in OpenShift with its build configurations, config maps, secrets, and dependencies like Postgres, Redis, and Kafka.
For our Spring Boot to Quarkus migration, the automated planner generated six high-level user stories to map out major migration milestones. These milestones split into 23 logical task groups, which ultimately broke down into 115 individual subtasks containing clear acceptance criteria and tracking dependencies.
Each task includes:
- What to change: File paths, specific lines if known
- Why to change it: Framework differences explained
- Acceptance criteria: How to verify success
- Dependencies: What must complete first
Example task from the plan:
### Task 3.1: Convert ProductRepository to PanacheRepository
File: src/main/java/com/example/demo/repository/ProductRepository.java
Change from: interface extends JpaRepository
To: class implements PanacheRepository
Remove: import org.springframework.data.jpa.repository.JpaRepository;
Add: import io.quarkus.hibernate.orm.panache.PanacheRepository;
Add: @ApplicationScoped annotation
Acceptance: Repository compiles as Panache repository
Depends on: Task 2.1 (Product entity migration)The dependency structure makes sure the agent doesn't try to use PanacheRepository before updating the entity annotations. This is critical for parallel execution—independent tasks run concurrently, dependent tasks serialize.
User story breakdown
The 115 subtasks roll up into six user stories that represent major milestones in the migration. Each story has clear acceptance criteria and dependencies.
User story 1: Framework migration foundation
Replace Spring Boot dependencies and configurations with Quarkus equivalents. This is the foundation; nothing else can start until the BOM is swapped and dependencies resolve. This step includes migrating the JPA entity from javax.persistence to jakarta.persistence. Estimate: 15 minutes.
User story 2: Data access modernization
Convert Spring Data JPA repositories to Quarkus Panache. Transform ProductRepository from an interface extending JpaRepository to a class implementing PanacheRepository. Update the service layer to use CDI (@ApplicationScoped, @Inject) instead of Spring annotations (@Service, @Autowired). Panache eliminates boilerplate, removing the need for repository interfaces when you implement PanacheRepository directly. Estimate: 20 minutes.
User story 3: REST API modernization
Migrate Spring MVC controllers to JAX-RS resources. Replace @RestController with @Path, @GetMapping with @GET, and ResponseEntity with JAX-RS Response. This step maintains API contract compatibility so clients see no difference, but it uses standard Jakarta EE REST specifications instead of Spring's proprietary annotations. Estimate: 20 minutes.
User story 4: Quality assurance and testing
Generate comprehensive test coverage using the mig-test-gen skill. Create unit tests for entities, repositories, and services to target more than 80% coverage. Add integration tests for all REST endpoints using @QuarkusTest and RestAssured. Verify that mvn test passes 100% and the application starts in under two seconds. Estimate: 25 minutes.
User story 5: Cloud-native deployment to OpenShift
Containerize the application with the Red Hat Universal Base Image (UBI) 9 OpenJDK 17 base image. Deploy it to the OpenShift namespace migiq-examples with two replicas. Configure health probes at /q/health/live, /q/health/ready, set resource limits (256Mi-512Mi memory, 100m-500m CPU), and expose the application via an HTTPS route. Finally, validate the deployment with smoke tests to create, read, search, and delete a product via the REST API. Estimate: 40 minutes.
User story 6: Documentation and knowledge transfer
Create migration documentation (README updates, DEPLOYMENT.md, MIGRATION-NOTES.md), document all REST endpoints with curl examples, capture lessons learned and edge cases (like JAX-RS not needing @RequestBody), and provide troubleshooting tips for future maintainers. Estimate: 15 minutes.
Each user story blocks the next. You can't test what you haven't migrated, and you can't deploy what doesn't pass tests. Within each story, however, tasks parallelize. For example, in user story 2, repository migration and service migration can run concurrently since they don't directly depend on each other (both depend on user story 1, not each other). The planner decomposes the migration track into chronological blocks to expose concurrent development opportunities, depicted in Figure 4.
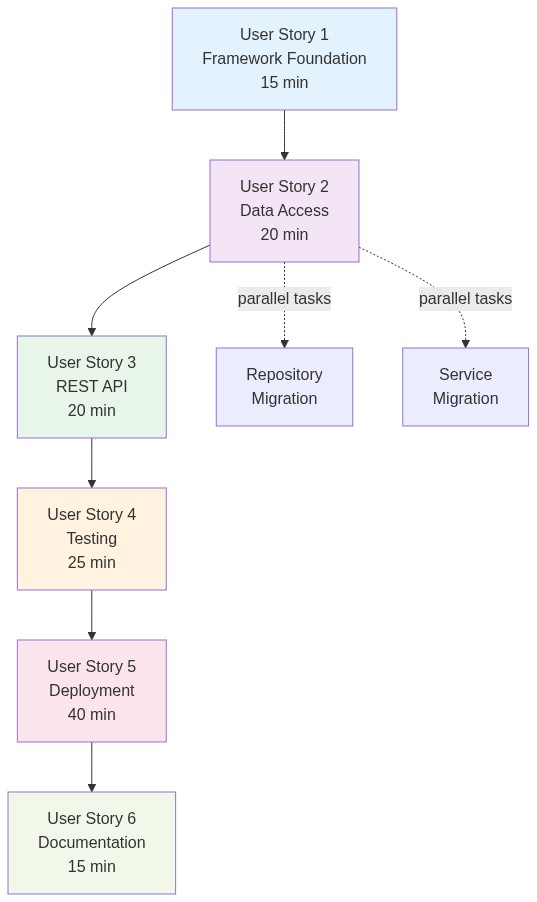
Total estimated time: 135 minutes (sequential). Actual execution time: 40 minutes (parallelized).
Phase 4: Autonomous execution
The execution engine spawns sub-agents for each task group. Each agent automatically reads its assigned task definition and locates the target files across the codebase. It then applies the necessary framework transformations, executes the local acceptance tests to validate the changes, and reports the final success or failure status back to the orchestrator.
The execution framework handles independent tasks across isolated concurrent workers, as visualized in the sequence model in Figure 5.
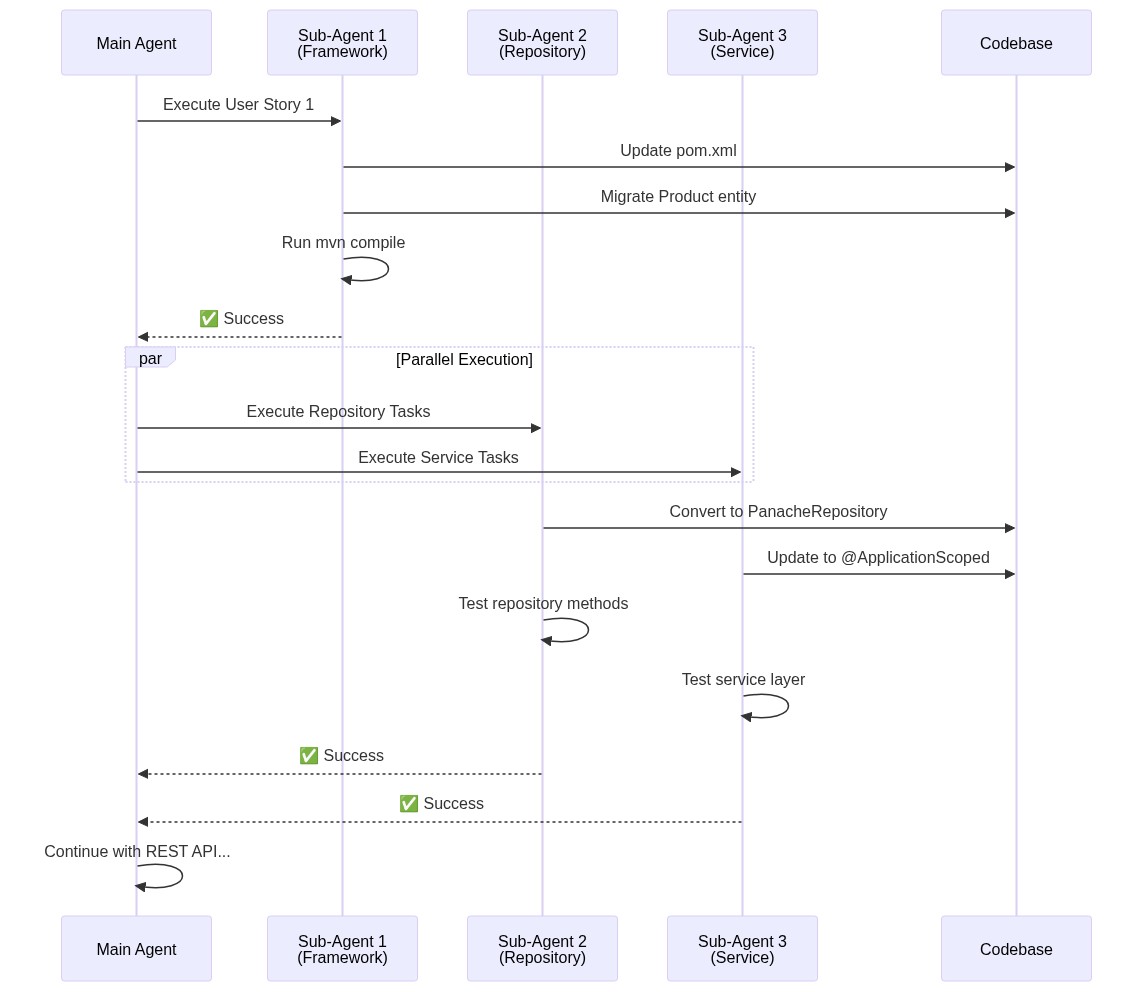
Here's what changed in our Spring Boot to Quarkus migration.
Before (Spring Boot controller):
@RestController
@RequestMapping("/api/products")
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/{id}")
public ResponseEntity getProduct(@PathVariable Long id) {
return productService.getProductById(id)
.map(ResponseEntity::ok)
.orElse(ResponseEntity.notFound().build());
}
}After (Quarkus JAX-RS resource):
@Path("/api/products")
@Produces(MediaType.APPLICATION_JSON)
@Consumes(MediaType.APPLICATION_JSON)
public class ProductController {
@Inject
ProductService productService;
@GET
@Path("/{id}")
public Response getProduct(@PathParam("id") Long id) {
return productService.getProductById(id)
.map(product -> Response.ok(product).build())
.orElse(Response.status(Response.Status.NOT_FOUND).build());
}
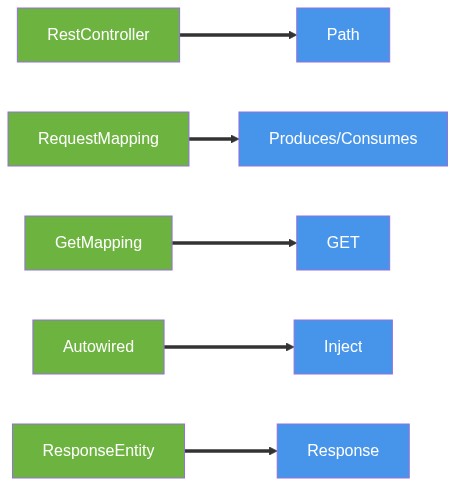
}What changed:
@RestControllerto@Path(JAX-RS resource)@RequestMappingto@Pathmethod annotations@Autowiredto@Inject(CDI)@GetMapping("/{id}")to@GET @Path("/{id}")@PathVariableto@PathParamResponseEntitytoResponse(JAX-RS)- Added
@Producesand@Consumesfor content negotiation
The agent did more than just rename annotations. It mapped Spring's annotation-driven model directly to JAX-RS resources with explicit MIME type declarations. This process shows semantic understanding instead of a basic text replacement. The transformation layer shifts underlying framework paradigms instead of executing crude text replacements, mapped out in Figure 6.
Repository layer transformation
This one's more complex because Spring Data JPA and Quarkus Panache have fundamentally different APIs.
Before (Spring Data):
@Repository
public interface ProductRepository extends JpaRepository {
List findByNameContaining(String name);
}After (Quarkus Panache):
@ApplicationScoped
public class ProductRepository implements PanacheRepository {
public List findByNameContaining(String name) {
return find("LOWER(name) LIKE LOWER(?1)", "%" + name + "%").list();
}
}What happened:
interfacetoclass(Panache uses composition, not inheritance)extends JpaRepositorytoimplements PanacheRepository- Magic method
findByNameContainingto explicit query implementation - Spring Data's derived query to Panache's query builder API
@Repositoryto@ApplicationScoped(CDI scoping)
The agent knew to convert the Spring Data method name convention to a Panache query. It didn't remove the method signature; instead, it added a body that implements the same logic using Panache's API. That requires understanding both frameworks' query semantics.
Build configuration
The most fragile part of any migration is the build. One wrong dependency version, and nothing compiles.
Before (Spring Boot pom.xml):
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.0</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
</dependencies>After (Quarkus pom.xml):
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.quarkus.platform</groupId>
<artifactId>quarkus-bom</artifactId>
<version>3.10.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-resteasy-reactive-jackson</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-hibernate-orm-panache</artifactId>
</dependency>
</dependencies>The agent removed the Spring Boot parent POM (which controls versions transitively) and replaced it with Quarkus BOM in dependencyManagement. It mapped spring-boot-starter-web to quarkus-resteasy-reactive-jackson (not just quarkus-resteasy, because the application uses Jackson for JSON).
This is where human migrations fail. You copy-paste a Quarkus guide, miss the Jackson dependency, and spend an hour debugging why JSON serialization doesn't work.
Phase 5: Verification and reporting
After execution, the agent runs:
- Compile check: Does
mvn clean compilesucceed? - Test run: Do existing tests pass after migration?
- Smoke test: Can we hit the REST endpoints and receive valid responses?
- Deployment check: Does the OpenShift deployment succeed and stay healthy?
To maintain application parity and check for downstream deployment health, the orchestration engine processes the safety loop shown in Figure 7.
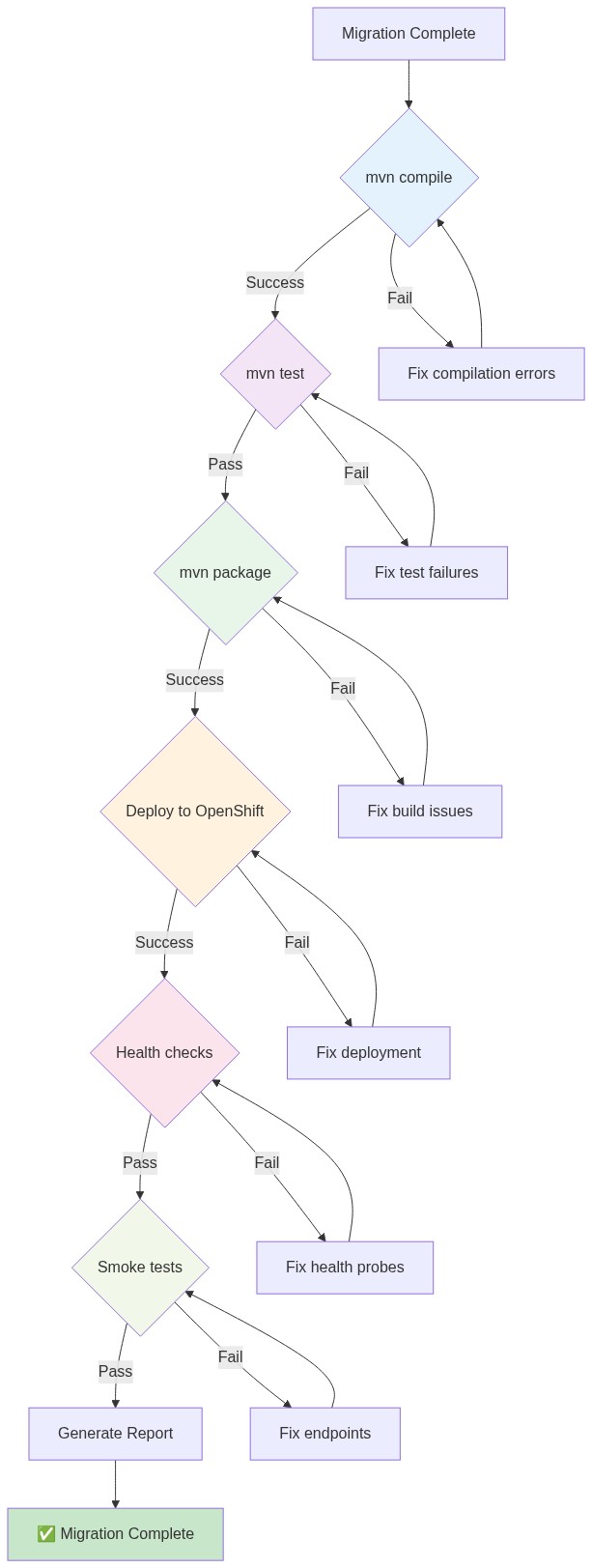
Our migration's final statistics:
Total User Stories: 6 ✅ Completed: 6 ❌ Failed: 0
Total Task Groups: 23 ✅ Completed: 23 ❌ Failed: 0
Total Subtasks: 115 ✅ Completed: 115 ❌ Failed: 0
Duration: ~40 minutes (end-to-end) The migration produces a complete artifact tree (Figure 8).

The actual execution time was about 40 minutes total. This is significantly faster than the conservative estimates in the user stories, which totaled approximately 135 minutes. This is due to:
- Parallel execution: Independent tasks ran concurrently across multiple sub-agents.
- No human wait time: Automated sub-agents eliminate context switching, no coffee breaks, no meetings.
- Optimized dependency resolution: Cached Maven dependencies avoid network delays.
What actually works (and what doesn't)
Works well:
- Annotation-driven migrations (90% of Spring to Quarkus)
- Dependency rewiring (once the graph is built)
- Build system transformations (Maven, Gradle)
- Containerization (Dockerfiles, Kubernetes YAML)
- Idiomatic code transformations, such as changing callbacks to async and await syntax
Still needs human help:
- Custom business logic (the agent doesn't know your domain)
- Performance tuning (it can migrate, but won't optimize unless told)
- Security reviews (generated code should always be audited)
- Complex query rewrites (ORM subtleties require validation)
Completely fails:
- Migrations where the target platform lacks equivalent features
- Code that relies on framework internals (reflection hacks, classloader tricks)
- Migrations without clear acceptance criteria, such as a vague request to "make it faster"
How to build your own agent-based migrations
You don't need MigIQ specifically. The pattern is reusable:
- Build a knowledge graph to extract the structure of your codebase. Useful tools include TreeSitter for parsing, NetworkX for graphs, or existing graph frameworks like Sourcetrail, Code2Flow, or Graphify.
- Define transformation rules that map source framework patterns to target framework patterns. For example, map
@RestControllerand@RequestMappingto@Path,@Autowiredto@Inject,ResponseEntitytoResponse, andJpaRepositorytoPanacheRepository. - Create a task dependency graph. Use topological sort to order tasks. Entities before repositories before services before controllers.
- Parallelize independent work. Because controllers do not depend on each other, you can spawn separate agents for each file.
- Verify at each step. Don't wait until the end to compile. Check after each task group.
- Generate diffs instead of full files so agents output minimal changes. Code review is easier when you see
- @Autowiredand+ @Injectrather than entire file rewrites.
The actual prompt (minimal example)
Here's a stripped-down version of what MigIQ generates for the planning phase:
You are migrating a Spring Boot 2.7.0 application to Quarkus 3.10.0.
Source analysis (from graph):
4 classes: Product, ProductRepository, ProductService, ProductController
Dependency order: Product → ProductRepository → ProductService → ProductController
Frameworks: Spring Web, Spring Data JPA, H2 database
Target requirements:
Quarkus 3.10.0 with Panache (not Hibernate directly)
RESTEasy Reactive (not Classic)
Deploy to OpenShift with health checks
Use Java 17
Generate a task list with:
Dependency changes (pom.xml)
Entity migration (javax → jakarta)
Repository migration (JpaRepository → PanacheRepository)
Service migration (@Service → @ApplicationScoped)
Controller migration (@RestController → @Path)
Configuration (application.properties)
Containerization (Dockerfile, OpenShift manifests)
For each task:
File path
What changes
Why it changes
Acceptance criteria
Dependencies (what must run first)The planning agent outputs a 115-task plan, which execution agents then read and implement.
What this means for development
Coding agents won't replace developers. They automate the boring parts: dependency updates, API surface rewrites, build system changes. The interesting parts—domain logic, architecture decisions, performance tuning—still need human judgment.
But migrations? Those are pattern matching at scale. Perfect for agents.
The Spring Boot to Quarkus migration took 40 minutes with zero human intervention. The same migration completed manually takes one to two days for a small application, or one to two weeks for a production system. The agent doesn't get tired, doesn't miss edge cases in the 47th file, and doesn't forget to update the deployment manifests.
If you're planning a migration, don't ask an agent to handle the entire process without guidance. Instead, ask it to perform specific tasks:
- Analyze your codebase (build the graph)
- Generate a migration plan (task decomposition)
- Execute the plan (with verification)
- Report what worked and what needs review
Treat the agent as a collaborator that excels at following detailed instructions but requires human supervision for business logic. This approach represents the current standard for automated workflows.
Try it yourself
MigIQ is the demo project and works with any coding agent that supports tool use. The complete example migration, which includes all generated artifacts, execution logs, and the deployed Quarkus application, is available in the examples/spring-boot-to-quarkus.tar.gz file.
You can install it and run migrations in your own projects:
npx @sshaaf/migiqThen enter the following command in your coding agent:
/migiq Migrate this [source tech] app to [target tech]The agent will walk through all five phases, generate the task plan, execute it, and hand you a deployable application.
The code is available in the GitHub repository. The repository includes the following core modules:
mig-graphify/: Code analysis and graph generationmig-plan/: Task decomposition and dependency planningmig-execute/: Parallel execution enginemig-test-gen/: Unit test generationmig-containerize/: Application containerizationmig-deploy/: Deployment to OpenShiftmigiq/: Orchestration layer
Ready for production migration?
If you're planning a Java migration to cloud-native platforms, Red Hat provides enterprise-grade tools that complement this approach.
Red Hat's migration toolkit for applications:
- Analyzes Java EE, Spring Boot, and legacy applications
- Identifies migration issues, effort estimation, and transformation patterns
- Generates detailed reports with line-by-line code recommendations
- Supports Java EE to Jakarta EE, Spring Boot to Quarkus, and WebLogic or WebSphere to Red Hat JBoss Enterprise Application Platform (JBoss EAP).
- Production Kubernetes platform with enterprise support
- Integrated CI/CD, monitoring, security-focused features, and compliance management
- Developer tools: Source-to-Image (S2I), Red Hat OpenShift Dev Spaces, Red Hat OpenShift Serverless
- Runs anywhere: on premise, AWS, Microsoft Azure, Google Cloud, and IBM Cloud