As generative AI scales within the enterprise, giving developers access to multiple large language models (LLMs)—from frontier models to smaller, task-specific models—can quickly lead to infrastructure sprawl. Instead of managing dozens of isolated endpoints, platform engineering teams are moving toward a Model-as-a-Service (MaaS) approach. By using an AI gateway, you can provide a unified, secure, and easily consumable API for all your developers, which reduces GPU waste and simplifies application logic.
In this guide, you will build a unified entry point for AI inference that simplifies how developers interact with multiple models. You will learn how to:
- Adopt a MaaS pattern by serving both Qwen/Qwen3-0.6B and TinyLlama/TinyLlama-1.1B-Chat-v1.0 behind a single OpenAI-compatible endpoint.
- Build an intelligent routing infrastructure that dynamically inspects the request payload and directs traffic based on the specified
modelfield. - Deploy a future-ready architecture designed to scale to any number of models, which handles large models with tensor parallelism across multiple GPUs.
Why this matters: One endpoint for all models means simpler client code, unified authentication, and centralized monitoring—regardless of how many models you deploy.
While this guide walks through a manual deployment, these llm-d capabilities are natively integrated into Red Hat OpenShift AI. This integration reduces operational overhead and the risk of managing custom machine learning infrastructure by transforming this DIY architecture into a fully supported, enterprise-grade platform.
The components
This deployment builds on three open source projects:
- llm-d, a platform for deploying LLM inference on Kubernetes with intelligent scheduling
- Gateway API Inference Extension (GAIE), a Kubernetes SIG project that adds inference-aware routing to Gateway API
- agentgateway, a Rust-based data plane with native body-based routing
IThis guide uses Red Hat OpenShift as the enterprise Kubernetes distribution to demonstrate this architecture, but you can apply the core concepts to any standard Kubernetes environment. I show you how to reduce GPU underutilization and simplify application logic by routing traffic to the correct model behind a single endpoint.
Understanding the LLM routing traffic flow
The GAIE request flow defines a five-step process: the gateway selects a route, forwards the request to an InferencePool extension, the extension gathers metrics from the pool endpoints, selects the optimal pod, and the gateway delivers the request.
This guide adds a pre-routing step before that standard flow: an AgentgatewayPolicy parses the JSON request body, extracts the model field, and sets a routing header. This header conversion enables HTTPRoute matching, which connects each model name to its InferencePool.
Figure 1 shows the full request path, including the AgentgatewayPolicy pre-routing step.
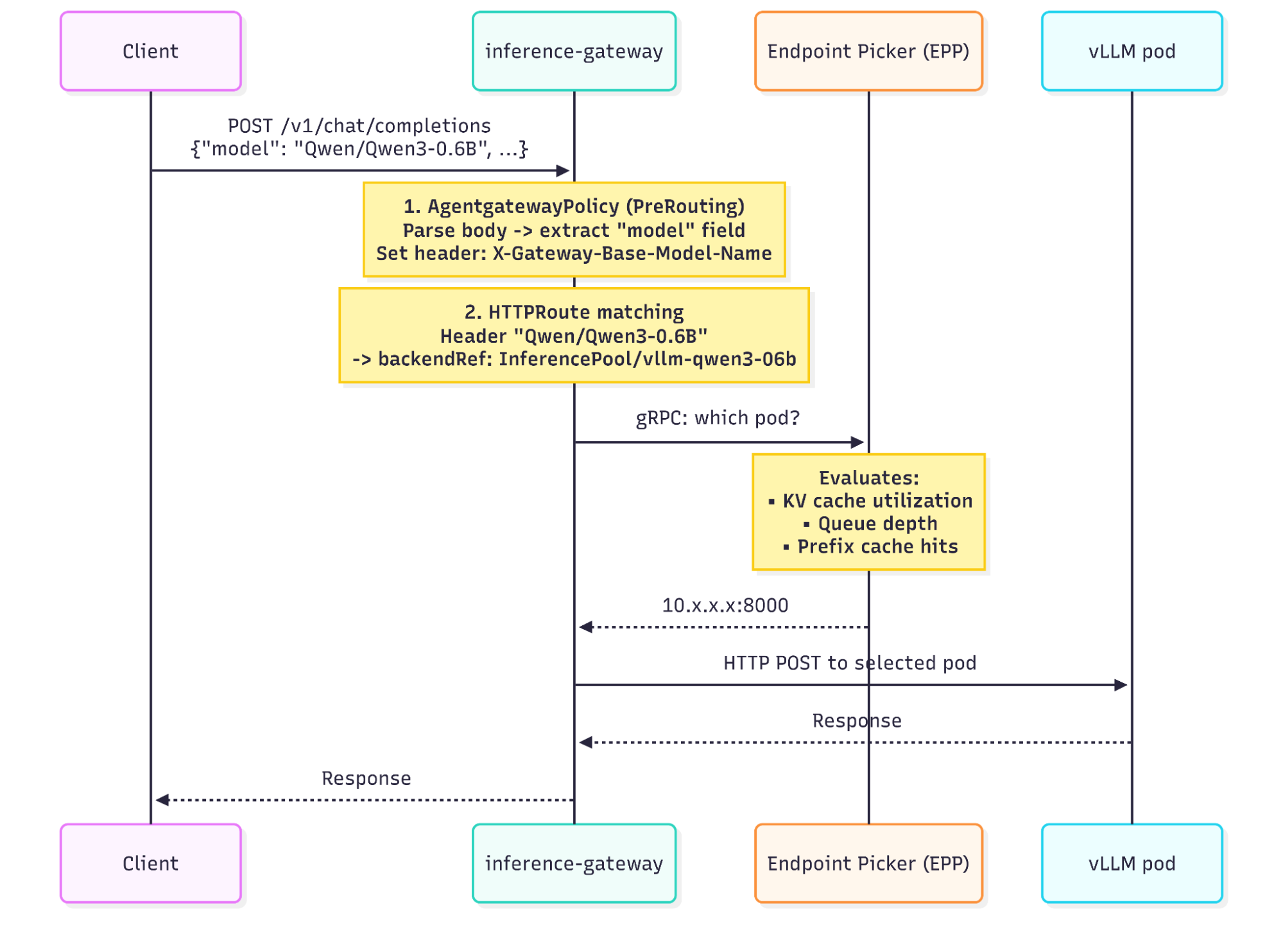
The following list describes the five stages in detail:
- AgentgatewayPolicy parses the JSON request body using a Common Expression Language (CEL) expression, extracts the
modelfield, and sets theX-Gateway-Base-Model-Nameheader. This happens in the pre-routing phase, before any route matching. - HTTPRoute matching: The gateway evaluates
HTTPRouteresources, each matching on theX-Gateway-Base-Model-Nameheader value. A match routes the request to the correspondingInferencePool. InferencePooland EPP: Unlike a standard Kubernetes Service that does round-robin,InferencePoolreferences an endpoint picker (EPP). The gateway calls the EPP over gRPC, and the EPP selects the optimal pod based on real-time inference metrics: KV cache utilization, queue depth, active requests, and prefix cache hit rate.- Forward to vLLM: T- the gateway sends the request directly to the selected vLLM pod on port 8000.
- Response: The response flows back through the gateway to the client.
Before you begin
Ensure that you have the following prerequisites:
- OpenShift cluster with GPU nodes
oc,helm,helmfile, andcurlcommand-line interface (CLI) tools- A Hugging Face token (if pulling gated models)
Clone the llm-d repository, which contains the prerequisite scripts used in this guide, and navigate to it:
git clone https://github.com/llm-d/llm-d.git && cd llm-dDeploying the stack
Complete the following steps to deploy the multi-model inference routing stack.
Step 1: Install CRDs and agentgateway
This step installs the required Custom Resource Definitions (CRDs) and the agentgateway control plane. The prerequisite scripts are located in the llm-d repository that you cloned earlier.
OpenShift 4.19 and later: The Ingress Operator manages Gateway API CRDs (gateway.networking.k8s.io) and protects them with a ValidatingAdmissionPolicy. Do not install or modify these CRDs manually. Install the GAIE CRDs, the agentgateway-specific CRDs (agentgateway.dev), and the agentgateway control plane:
# Install GAIE CRDs (InferencePool and related resources)
oc apply -k https://github.com/kubernetes-sigs/gateway-api-inference-extension/config/crd/?ref=v1.3.0
# Install agentgateway CRDs and control plane (does not touch gateway.networking.k8s.io)
helmfile apply -f guides/prereq/gateway-provider/agentgateway.helmfile.yamlOpenShift 4.18 and earlier: Gateway API CRDs are not pre-installed. Run the full installation script:
./guides/prereq/gateway-provider/install-gateway-provider-dependencies.sh
helmfile apply -f guides/prereq/gateway-provider/agentgateway.helmfile.yamlThe agentgateway chart (oci://ghcr.io/kgateway-dev/charts/agentgateway v2.2.0-beta.3) installs with inferenceExtension.enabled: true into the agentgateway-system namespace.
Verify the control plane is running:
oc get pods -n agentgateway-system
# NAME READY STATUS
# agentgateway-xxxxxxxxx-xxxxx 1/1 RunningStep 2: Create the gateway and SCC binding
Create a Gateway resource that accepts traffic from all namespaces:
oc apply -f - <<'EOF'
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: inference-gateway
namespace: agentgateway-system
spec:
gatewayClassName: agentgateway-v2
listeners:
- protocol: HTTP
port: 8080
name: http
allowedRoutes:
namespaces:
from: All
EOFThe gateway creates a data plane deployment to handle traffic. This deployment requires permissions beyond the default OpenShift security context constraints (SCCs). Apply an SCC binding:
oc apply -f - <<'EOF'
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: inference-gateway-scc
namespace: agentgateway-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:openshift:scc:nonroot-v2
subjects:
- kind: ServiceAccount
name: inference-gateway
namespace: agentgateway-system
EOFVerify both the control plane and data plane pods are running:
oc get pods -n agentgateway-system
# agentgateway-* 1/1 Running (control plane)
# inference-gateway-* 1/1 Running (data plane proxy)
oc get gateway -n agentgateway-system
# NAME CLASS PROGRAMMED
# inference-gateway agentgateway-v2 TrueStep 3: Configure body-based routing
The AgentgatewayPolicy is where the routing logic lives. It attaches to the Gateway and runs a CEL expression that parses the JSON request body, extracts the model field, and sets a header that HTTPRoute resources can match on:
oc apply -f - <<'EOF'
apiVersion: agentgateway.dev/v1alpha1
kind: AgentgatewayPolicy
metadata:
name: bbr
namespace: agentgateway-system
spec:
targetRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: inference-gateway
traffic:
phase: PreRouting
transformation:
request:
set:
- name: X-Gateway-Base-Model-Name
value: |
{
"Qwen/Qwen3-0.6B": "Qwen/Qwen3-0.6B",
"TinyLlama/TinyLlama-1.1B-Chat-v1.0": "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
}[json(request.body).model]
EOFThe JSON map defines which model names are recognized. The keys are what clients send in the "model" field; the values are the base model names used for routing. This same map structure also supports Low-Rank Adaptation (LoRA) adapters—to add an adapter, map its name to the base model it runs on.
Step 4: Deploy InferencePools
Each model gets its own InferencePool, which groups model-serving pods and provides an Endpoint Picker (EPP) for intelligent load balancing. The GAIE inferencepool chart creates the InferencePool, EPP Deployment, and an HTTPRoute with header matching.
export NAMESPACE=llm-d
export MODEL_SERVER=vllm
export IGW_CHART_VERSION=v1.3.0
oc create namespace ${NAMESPACE} || true
# Pool for Qwen/Qwen3-0.6B
helm upgrade --install ${MODEL_SERVER}-qwen3-06b \
--dependency-update \
--set inferencePool.modelServers.matchLabels.app=${MODEL_SERVER}-qwen3-06b \
--set provider.name=none \
--set inferencePool.modelServerType=${MODEL_SERVER} \
--set experimentalHttpRoute.enabled=true \
--set experimentalHttpRoute.baseModel="Qwen/Qwen3-0.6B" \
--version ${IGW_CHART_VERSION} \
--namespace ${NAMESPACE} \
oci://us-central1-docker.pkg.dev/k8s-staging-images/gateway-api-inference-extension/charts/inferencepool
# Pool for TinyLlama/TinyLlama-1.1B-Chat-v1.0
helm upgrade --install ${MODEL_SERVER}-tinyllama-11b \
--dependency-update \
--set inferencePool.modelServers.matchLabels.app=${MODEL_SERVER}-tinyllama-11b \
--set provider.name=none \
--set inferencePool.modelServerType=${MODEL_SERVER} \
--set experimentalHttpRoute.enabled=true \
--set experimentalHttpRoute.baseModel="TinyLlama/TinyLlama-1.1B-Chat-v1.0" \
--version ${IGW_CHART_VERSION} \
--namespace ${NAMESPACE} \
oci://us-central1-docker.pkg.dev/k8s-staging-images/gateway-api-inference-extension/charts/inferencepoolNote the following details about the deployment:
- The Helm release name (
${MODEL_SERVER}-qwen3-06b) becomes theInferencePoolname. - Kubernetes resource names must be valid DNS-1035 labels—no dots allowed. Use
qwen3-06binstead ofqwen3-0.6b. - The
experimentalHttpRoute.enabled=trueoption auto-creates anHTTPRoutethat matches on theX-Gateway-Base-Model-Nameheader and routes to theInferencePool.
Verify that the resources are created:
oc get inferencepool -n ${NAMESPACE}
# NAME AGE
# vllm-qwen3-06b ...
# vllm-tinyllama-11b ...
oc get httproute -n ${NAMESPACE}
# NAME HOSTNAMES AGE
# vllm-qwen3-06b ...
# vllm-tinyllama-11b ...
oc get pods -n ${NAMESPACE} | grep epp
# vllm-qwen3-06b-epp-* 1/1 Running
# vllm-tinyllama-11b-epp-* 1/1 RunningStep 5: Deploy model servers
Deploy the vLLM model servers using the llm-d-modelservice Helm chart. Each model server needs a values file that specifies the model artifact and a label matching the InferencePool selector.
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo updateIf your models require authentication (for example, gated Hugging Face models), create a secret with your token:
oc create secret generic llm-d-hf-token \
--from-literal="HF_TOKEN=${HF_TOKEN}" \
--namespace ${NAMESPACE}The values files are minimal; only fields without defaults need to be set. Create them before running the Helm commands:
cat > ms-qwen-values.yaml <<'EOF'
modelArtifacts:
uri: "hf://Qwen/Qwen3-0.6B"
name: "Qwen/Qwen3-0.6B"
size: 10Gi
# authSecretName: "llm-d-hf-token" # Uncomment if the model requires authentication
labels:
app: "vllm-qwen3-06b" # Must match inferencePool.modelServers.matchLabels.app
routing:
servicePort: 8000
accelerator:
type: nvidia
EOFcat > ms-llama-values.yaml <<'EOF'
modelArtifacts:
uri: "hf://TinyLlama/TinyLlama-1.1B-Chat-v1.0"
name: "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
size: 10Gi
# authSecretName: "llm-d-hf-token" # Uncomment if the model requires authentication
labels:
app: "vllm-tinyllama-11b" # Must match inferencePool.modelServers.matchLabels.app
routing:
servicePort: 8000
accelerator:
type: nvidia
EOFThe critical link is modelArtifacts.labels.app. This label must exactly match the matchLabels.app in the InferencePool. This label matching is how the EPP discovers which pods belong to which pool.
Deploy both model servers:
helm upgrade --install ms-qwen llm-d-modelservice/llm-d-modelservice \
--namespace ${NAMESPACE} \
-f ms-qwen-values.yaml
helm upgrade --install ms-llama llm-d-modelservice/llm-d-modelservice \
--namespace ${NAMESPACE} \
-f ms-llama-values.yamlVerify pods have the correct labels:
oc get pods -n ${NAMESPACE} --show-labels | grep "app="
# ms-qwen-* 2/2 Running ... app=vllm-qwen3-06b,...
# ms-llama-* 2/2 Running ... app=vllm-tinyllama-11b,...Step 6: Attach HTTPRoutes to the gateway
The HTTPRoute resources created by the inferencepool chart live in the llm-d namespace. By default, their parentRefs do not specify the gateway's namespace. Patch the parentRefs to point to the gateway in the agentgateway-system namespace:
oc patch httproute vllm-qwen3-06b -n llm-d --type='json' \
-p='[{"op":"add","path":"/spec/parentRefs/0/namespace","value":"agentgateway-system"}]'
oc patch httproute vllm-tinyllama-11b -n llm-d --type='json' \
-p='[{"op":"add","path":"/spec/parentRefs/0/namespace","value":"agentgateway-system"}]'If you choose to deploy HTTPRoute and InferencePool resources in different namespaces, then you must create a ReferenceGrant in the target namespace.
Verify the gateway has picked up the routes:
oc get gateway inference-gateway -n agentgateway-system \
-o jsonpath='{.status.listeners[0].attachedRoutes}'
# Expected: 2Verify the deployment
Now that all components are deployed, you can verify the stack:
# Gateway namespace
oc get pods -n agentgateway-system
# agentgateway-* 1/1 Running
# inference-gateway-* 1/1 Running
# Model serving namespace
oc get pods -n llm-d
# ms-qwen-* 2/2 Running
# ms-llama-* 2/2 Running
# vllm-qwen3-06b-epp-* 1/1 Running
# vllm-tinyllama-11b-epp-* 1/1 Running
# Resources
oc get inferencepool -n llm-d
oc get httproute -n llm-d
oc get agentgatewaypolicy -n agentgateway-systemExpose the gateway with an OpenShift route
Create an OpenShift route to expose the gateway externally with TLS edge termination. The haproxy.router.openshift.io/timeout annotation ensures that streaming responses, such as those using stream: true, do not time out prematurely:
oc apply -f - <<'EOF'
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: inference-gateway
namespace: agentgateway-system
annotations:
haproxy.router.openshift.io/timeout: 300s
spec:
to:
kind: Service
name: inference-gateway
port:
targetPort: 8080
tls:
termination: edge
EOFRetrieve the Route hostname:
GATEWAY_URL=$(oc get route inference-gateway -n agentgateway-system -o jsonpath='{.spec.host}')Test the routing
Send requests to different models through the same endpoint:
# Request routed to Qwen pool
curl -s -X POST https://${GATEWAY_URL}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "Qwen/Qwen3-0.6B", "messages": [{"role": "user", "content": "Hello Qwen"}]}'
# Request routed to TinyLlama pool
curl -s -X POST https://${GATEWAY_URL}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0", "messages": [{"role": "user", "content": "Hello Llama"}]}'
# Unknown model - no matching HTTPRoute, request fails
curl -s -X POST https://${GATEWAY_URL}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "nonexistent", "messages": [{"role": "user", "content": "Should fail"}]}'The gateway routes each request to the correct model back end based solely on the model field in the request body.
Common issues
Use the following troubleshooting tips to resolve common errors and configuration issues encountered during the deployment process.
HTTPRoutes not attaching to the gateway
Verify that you patched the parentRefs namespace in Step 6. Run oc get httproute -n llm-d -o yaml and check that parentRefs[0].namespace is set to agentgateway-system.
Requests timing out
Check the OpenShift route timeout annotation. Streaming responses (stream: true) require longer timeouts than the default 30 seconds. Verify that haproxy.router.openshift.io/timeout: 300s is set.
Model not found errors
Verify that the model names in the AgentgatewayPolicy JSON map exactly match what clients send in the "model" field. The comparison is case-sensitive.
Pods not selected by EPP
Confirm that the modelArtifacts.labels.app value in the model server Helm values exactly matches the inferencePool.modelServers.matchLabels.app setting. Run oc get pods -n llm-d --show-labels to verify labels.
Add a new model
To extend this setup to serve additional models, follow these three steps:
- Add an entry to the
AgentgatewayPolicyJSON map with the new model name. - Deploy a new
InferencePoolusing the GAIE Helm chart withexperimentalHttpRoute.baseModelset to the new model name. - Deploy the model server via
llm-d-modelservicewithmodelArtifacts.labels.appmatching theInferencePoolselector.
What's next
You now have a multi-model inference gateway running on OpenShift. Requests to a single endpoint are automatically routed to the correct model based on the request payload.
To add more models, follow the three-step process described in the previous section. The same pattern works for any number of models—each one gets its own pool, and the Gateway routes requests based on the model field.
Alternative gateway providers
This guide uses agentgateway, which provides native body-based routing via AgentgatewayPolicy. Other Gateway API implementations, such as Kgateway, Istio, or Google Kubernetes Engine (GKE), can also serve as the data plane. These implementations require the body-based routing external processing filter to extract the model name from the request body. For installation and configuration details, refer to the GAIE guide for serving multiple inference pools.
Learn more
The llm-d documentation provides additional deployment patterns and configuration options for running LLM inference on Kubernetes.
The Gateway API Inference Extension site includes guides for advanced routing scenarios and alternative gateway providers.
For details on the gateway data plane implementation, see the agentgateway repository.
The llm-d-modelservice chart documentation covers additional model server configuration options.
You can try these integrated capabilities by starting a Red Hat OpenShift AI no-cost 60-day trial.