Following my introduction blog about why microservices should be event-driven, I’d like to take another few steps and blog about it. (Hopefully I saw you at jBCNconf and Red Hat Summit in San Francisco, where I spoke about some of these topics). Follow me on twitter @christianposta for updates on this project. In this article we discuss the first parts of carving up a monolith.
The monolith I’m exploring in depth for these articles will be from the Ticket Monster tutorial which for a long time has been the canonical example of how to build an awesome application with Java EE and Red Hat technologies. We are using Ticket Monster because it’s a well-written app that straddles the “non-trivial” and “too-complex for an example” line pretty well. It is perfect for illustrative purposes and we can point to it concretely and discuss the pros and cons of certain approaches with true example code. Please take a closer look at the domain and current architecture in light of the further discussions.
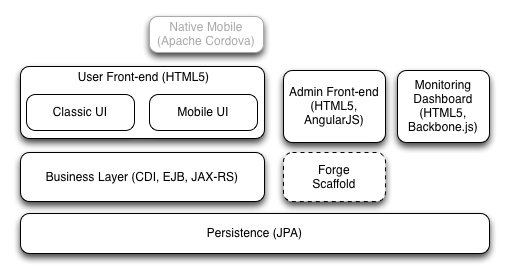
Looking at the current architecture above we can see things are nicely broken out already. We have the UI components, the business services, and the long-term persistence storage nicely separated and decoupled from each other yet packaged as a single deployable (a WAR file in this case). If we examine the source code, we see the code has a similar structure. If we were to deploy this, any changes to any of the components would dictate a build, test, and release of the entire deployable. One of the prerequisites to doing microservices is autonomy of components so they can be developed, tested, deployed in isolation without disrupting the rest of the system. So what if we just carve out the different layers here and deploy those independently? Then we can achieve some of that autonomy?
We’ve spent a lot of time in the past arguing for this type of architecture and it seems to make sense. We want to be able to scale out the individual components based on their needs. Scale out the web tier if we need to handle more web requests. Scale out the business services tier if those services start to become the bottleneck. Deal with and manage the database and the data-access layers independently from the rest of the application/services. “Decoupling” the UI logic from the middle tiers and the data access is a good guiding principle, but don’t confuse it with requiring layers.
What really happens in practice is that all of these “layered” architectural components, for all of its separation of concerns etc, succumbs quite easily to the whims of the data and the database. We can add all the CPUs we want, all the middle tiers and UI tiers we want, but no matter how fast our networks, compute, memory, etc have become, the bottleneck for this type of system typically is the competing domain models and ultimately the database. There’s a stress here on “domain models”… the internet companies practicing microservices may not have complex, ambiguous, and contradicting domain models like a FSI or insurance or retailer may have… for example, twitter has a simple domain … publish and display tweets… but that becomes complicated at such large scale… enterprises are starting to have both problems at the same time.. the domain model and its complexity is just as important as how to scale it (and often impedes the effort to scale). So now you just think “we’ll just use a NoSQL database like MongoDB so we can scale out our backends”… now you’ve got even more problems.
What about our teams? Another part of architecting a system like this is so we can have specialist teams independently work on these layers at different speeds, different locations, different tools, etc. They just need to share an interface between each other and they can work autonomously. This plays to conways law a little bit:
organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations
Unfortunately, I feel like it’s the reverse that’s true. It’s not that by doing this architecture we’re creating this opportunity for this specialization in teams and efficiency. It’s because of our organizational structure that forces us down this system architecture. Just like we have separate database teams, UI teams, security, operations, QA, build and release, etc,etc. This is how our organizations have been organized for decades. However, if you look at the success of the companies practicing microservices, there’s something quite a bit different about their organizational structure.
Let’s take a look at what happens. Taking the Ticket Monster app as an example, the business asks that we alter the way the administration of the website is handled. They ask us to add some extra fields related to tracking how often Concerts are added to and removed from the website because they want to add some predictive analysis about what may or may not be good events to add in the future based on time, location, weather, etc. This may involve the UI team if the business wants to display this predictive analysis to the administration users. It will certainly involve changing the business services layer of the app. And it will certainly impact changes to the database. We want to add some functionality to our app that forces ripple effects across all the layers and even more importantly, across all of the teams involved. Now we have to have project managers coordinating and tracking meetings with all of the teams involved. We need to create tickets to get the UI and DB teams to do anything not to mention QA, security, operations, etc to all be on board. All of this creates complex synchronization points between all of our teams and now we have to coordinate all of the changes, builds, and releases of our layers (and deploy everything together!). This is not the type of autonomy we desired. We cannot make changes independently of each other and in fact we’ve become quite brittle.
For our Ticket Monster app, let’s prefer to split the functionality into cohesive “verticals” not by technological or organizational layers. Each vertical will have its own “UI” (or UI component), “business services” and “database” that are specific to the function of administering the site. (For the first steps, however, we’ll leave the UI as a monolith an break down the pieces behind it. We’ll come back to breaking apart the UI, though that has its own challenges). Ticket Monster also allows users to review and book orders for concerts. Let’s split that into its own vertical. It may also have loyalty, recommendations, search, advertisements, personalization, etc. We’ll split those into their own verticals each owning their own database, UI, and integration points (REST services, backends, etc). If we need to make changes to the Loyalty functionality of the website, I don’t need to go and re-deploy the entire monolithic business-services tier or anything related to Search for example. I can deploy the part of loyalty from the UI to the DB that I need without forcing impacting changes to other services. Ideally a single team would own and operate each service as well.
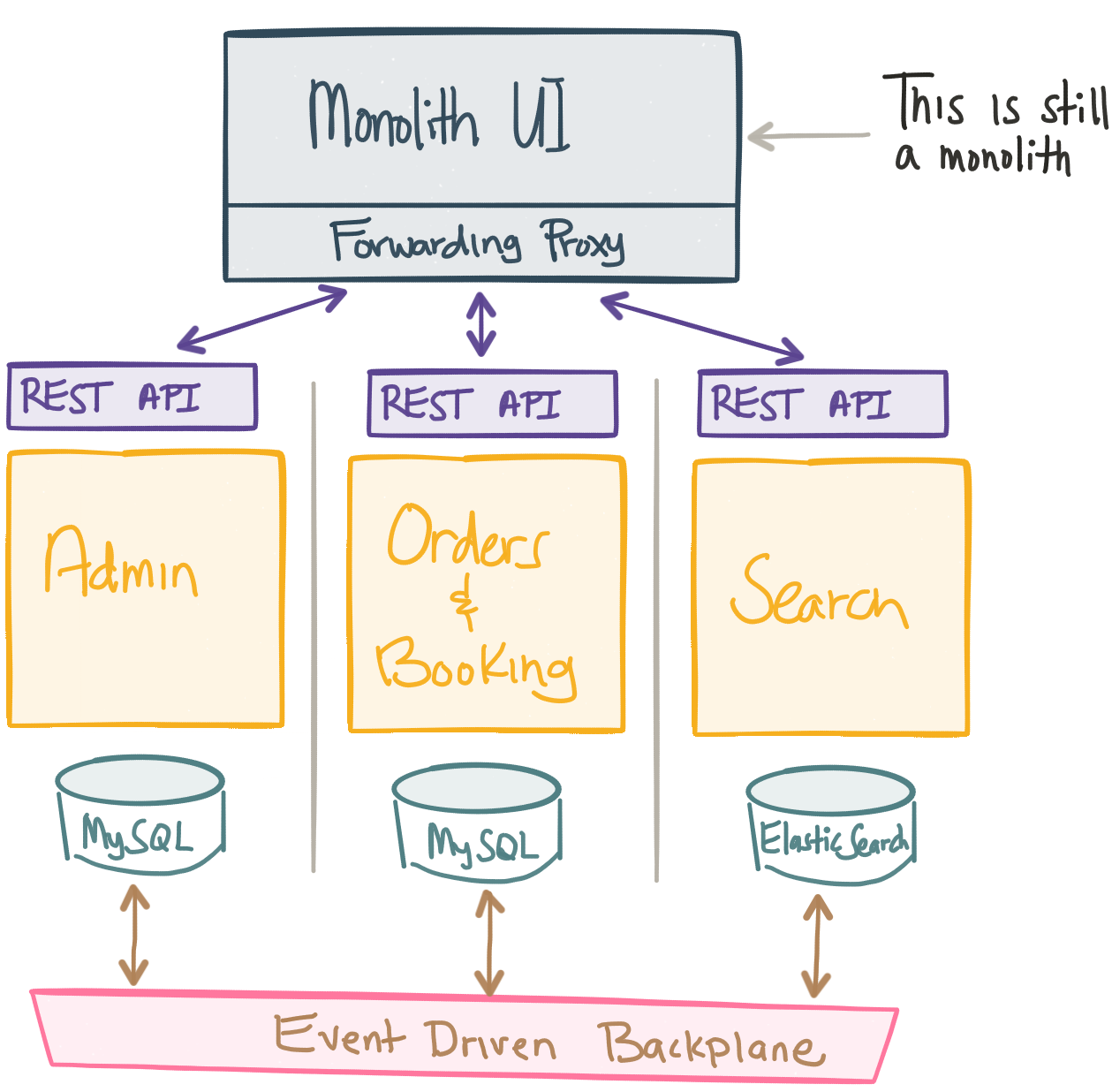
This gives us better cohesion within the code as well as more autonomy between the services. Once you start wrapping your head around what it means to split along business function verticals, we can explore for each vertical what its bounded context looks like; or whether or not it makes sense to apply CQRSwithin a bounded context. Or what type of database it should use based on its read/write patterns (Document? Relational? Graph) and whether you favor consistency or can tolerate a loss of data/inconsistent data. Or what transactions, compensations, apologies, etc might look like. And on and on.. We can now make these decisions in terms of whats best for our individual services not the lowest common denominator for a layer or a monolith. That’s what we’ll continue to explore in the next post! Stay tuned!
Update
Someone on twitter (thanks @herrwieger!) pointed me to this: Self contained systems (SCS) which articulates this concept that I’ve blogged about here. This is spot on and exactly to what I was referring. The more interesting thing happens when we explore each “self-contained system” within a bounded context and how it then breaks down into more granular microservices only if necessary. The boundaries are the important consideration when talking about a monolith, and that’s what I’ve touched on here and what SCS defines.
Last updated: March 15, 2023