Many organizations buying GPUs today end up with the same problem: the cards are expensive, the demand across teams is uneven (about 52% utilization on average), and there's no clean way for a developer to actually get their hands on one without filing a ticket. The result is usually some mix of GPUs sitting idle and GPUs being hoarded… sometimes both (and somehow on the same cluster).
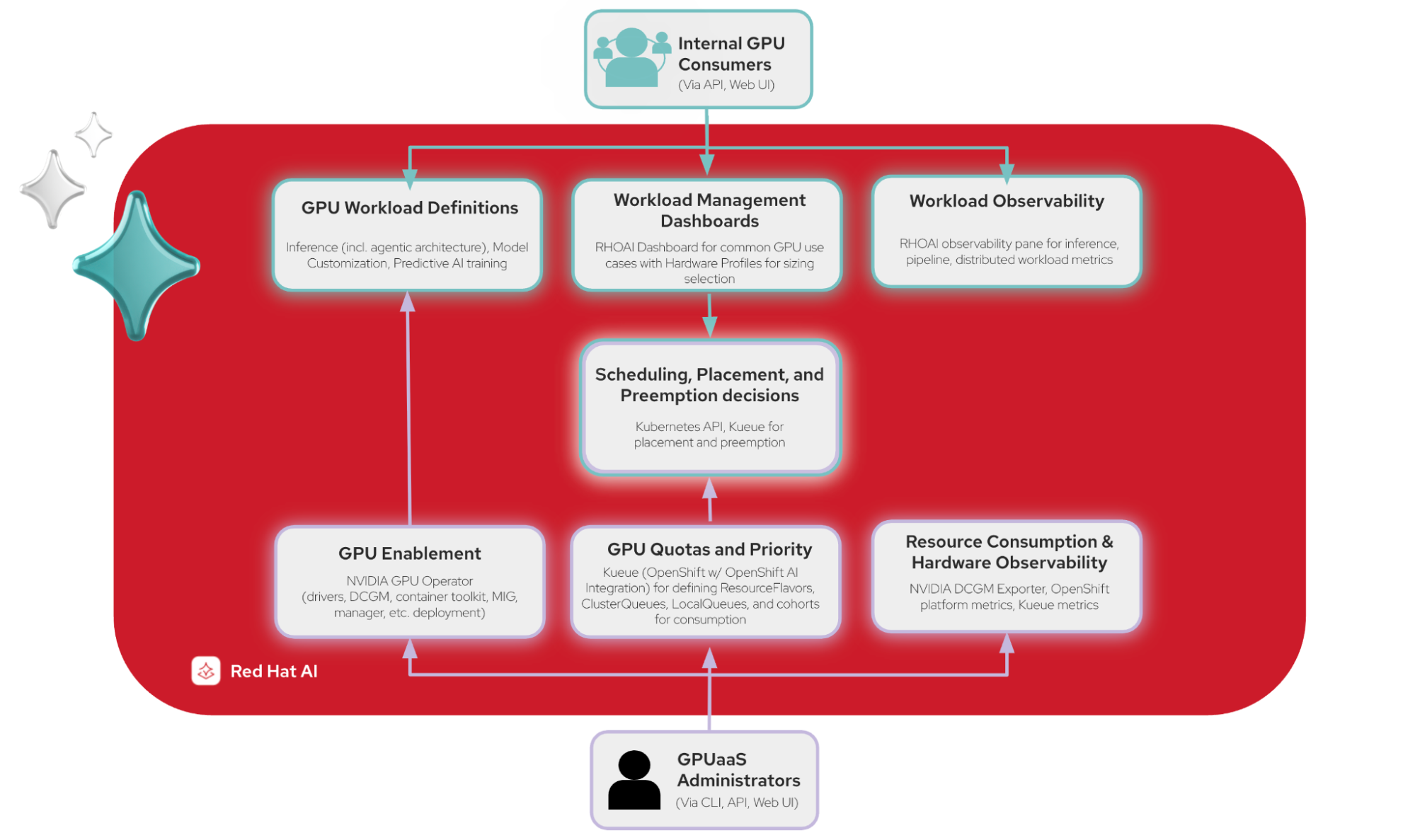
GPU-as-a-Service (GPUaaS) is the pattern that fixes that. A central platform team owns the hardware, and developers reserve slices of it on demand, almost like booking a meeting room. This post walks through how we put that workflow together on Red Hat OpenShift using the Red Hat build of Kueue, NVIDIA Multi-Instance GPU (MIG), and a small custom dashboard plug-in for self-service requesting of GPU resources, as shown in Figure 1.
How GPUaaS works: Kueue and NVIDIA MIG
We use OpenShift core platform features and OpenShift AI workload integration to manage a central pool of shared compute.
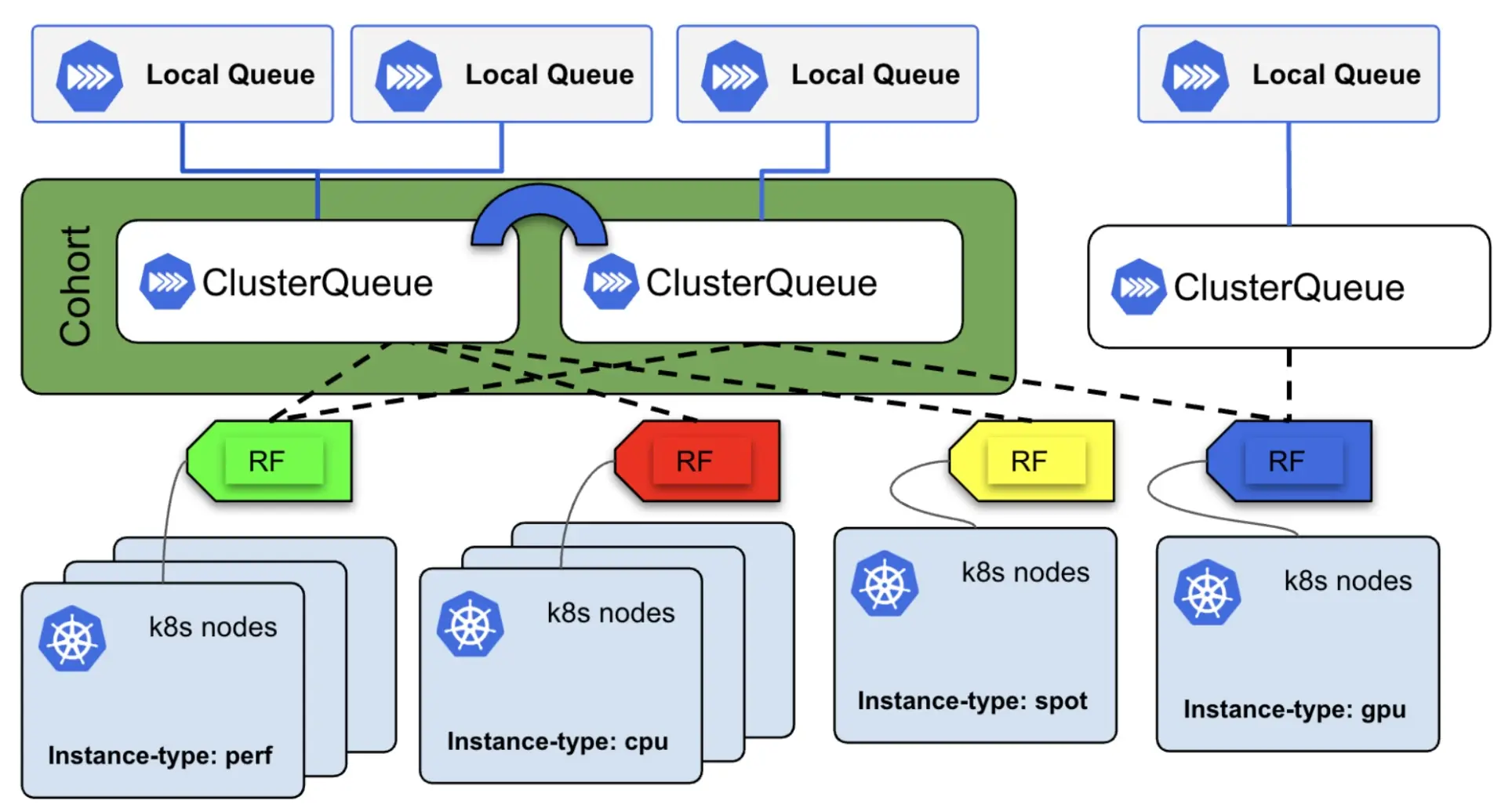
Kueue is a queueing and quota system for Kubernetes workloads. It lets a platform admin define resource pools, assign them to specific teams or users, and apply rules like fair sharing when things get busy, as shown in Figure 2.
NVIDIA MIG lets a single physical GPU be sliced into smaller, isolated instances. For example, an H200 can be carved into smaller pieces like a 1g.18gb slice or a 2g.35gb slice, each of which behaves like an independent GPU. MIG makes GPU-as-a-Service more flexible because instead of allocating a whole accelerator to someone running a small model, they can request the slice they actually need, as shown in Figure 3.
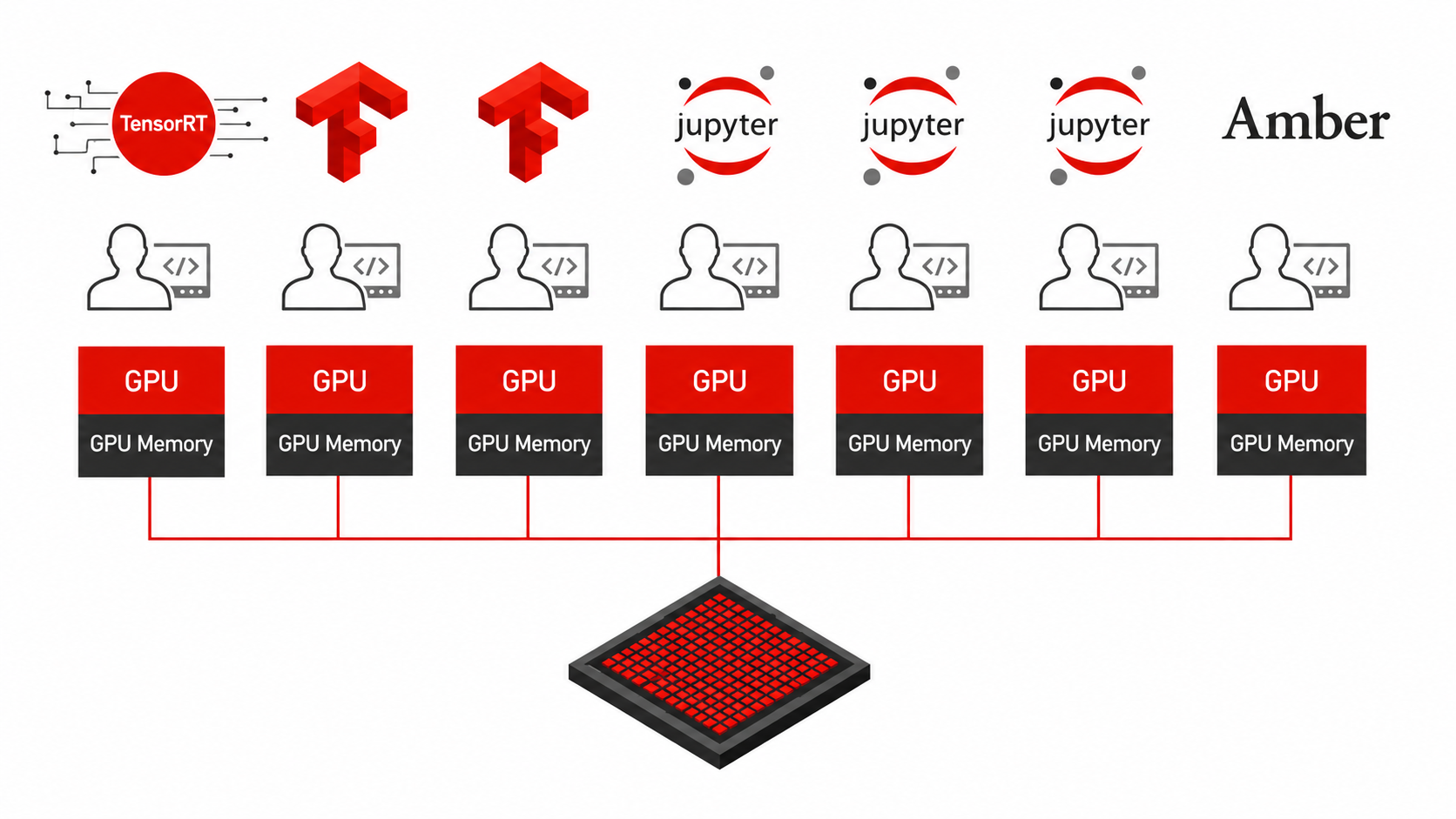
MIG partitions are configured in the NVIDIA GPU Operator using a combination of labels on nodes and platform-level enablement in the operator's ClusterPolicy resource.
Kueue and MIG meet in a resource called a ClusterQueue. The coveredResources block in this configuration file (Figure 4) lists each MIG slice size alongside CPU, memory, and full GPUs.
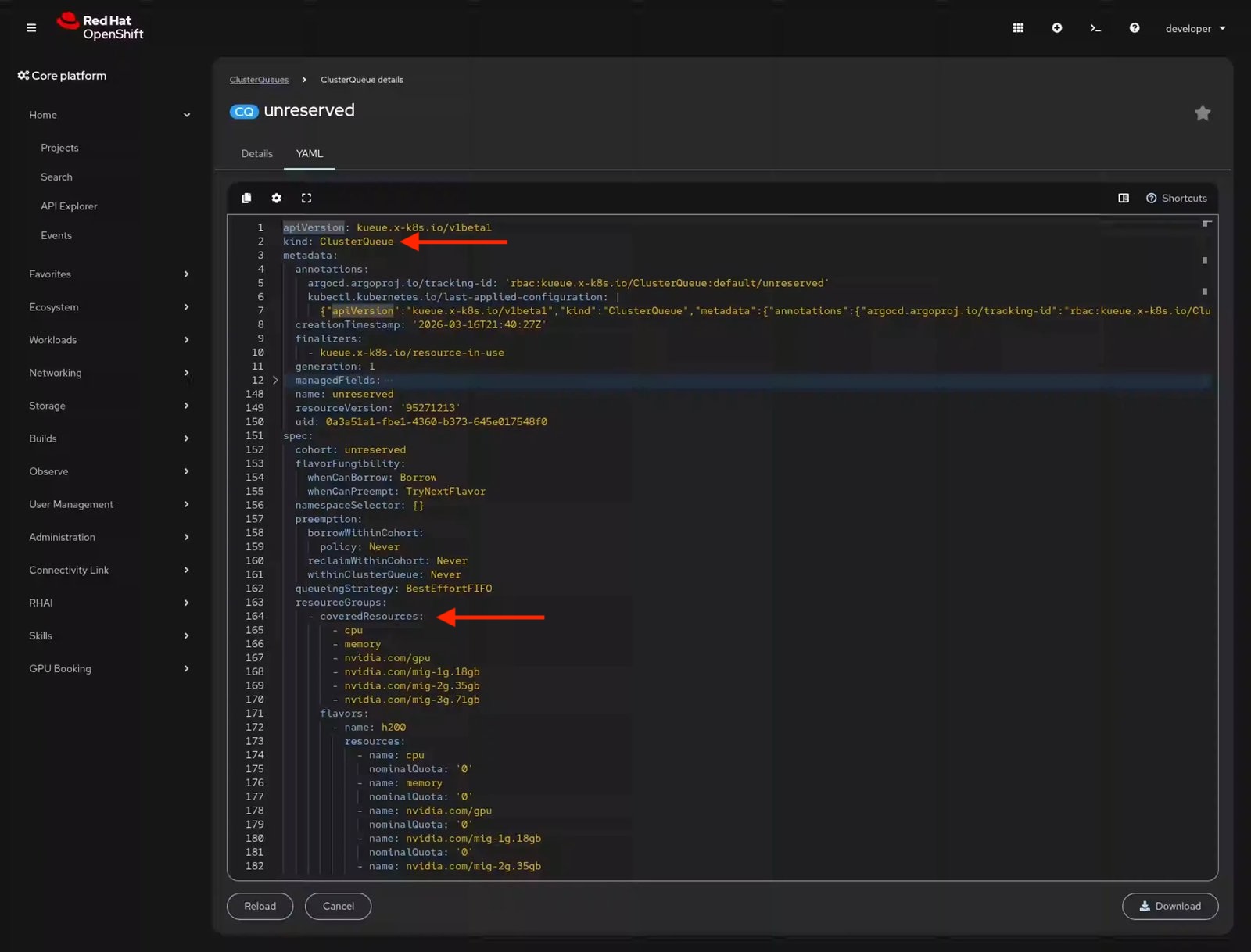
With the Red Hat build of Kueue, our platform team can define resource quotas (including individual MIG slice sizes) with flexible fair sharing, preemption, and queue prioritization. With that setup, let's look at what a developer actually sees when booking GPU resources. The ClusterQueue in this example does not have any direct quota; instead, it borrows from within its assigned cohort. This system allows teams to request unclaimed GPUs on a self-service basis without availability guarantees, making it ideal for lower-priority batch jobs.
How can we self-serve GPU quota reservations?
Kueue's APIs provide extensive scheduling options, but most developers don't want to write YAML to request a GPU for the afternoon. To simplify this process, our platform team built a custom GPU booking plug-in for the OpenShift web console (Figure 5), and it's just as cool as you'd expect.
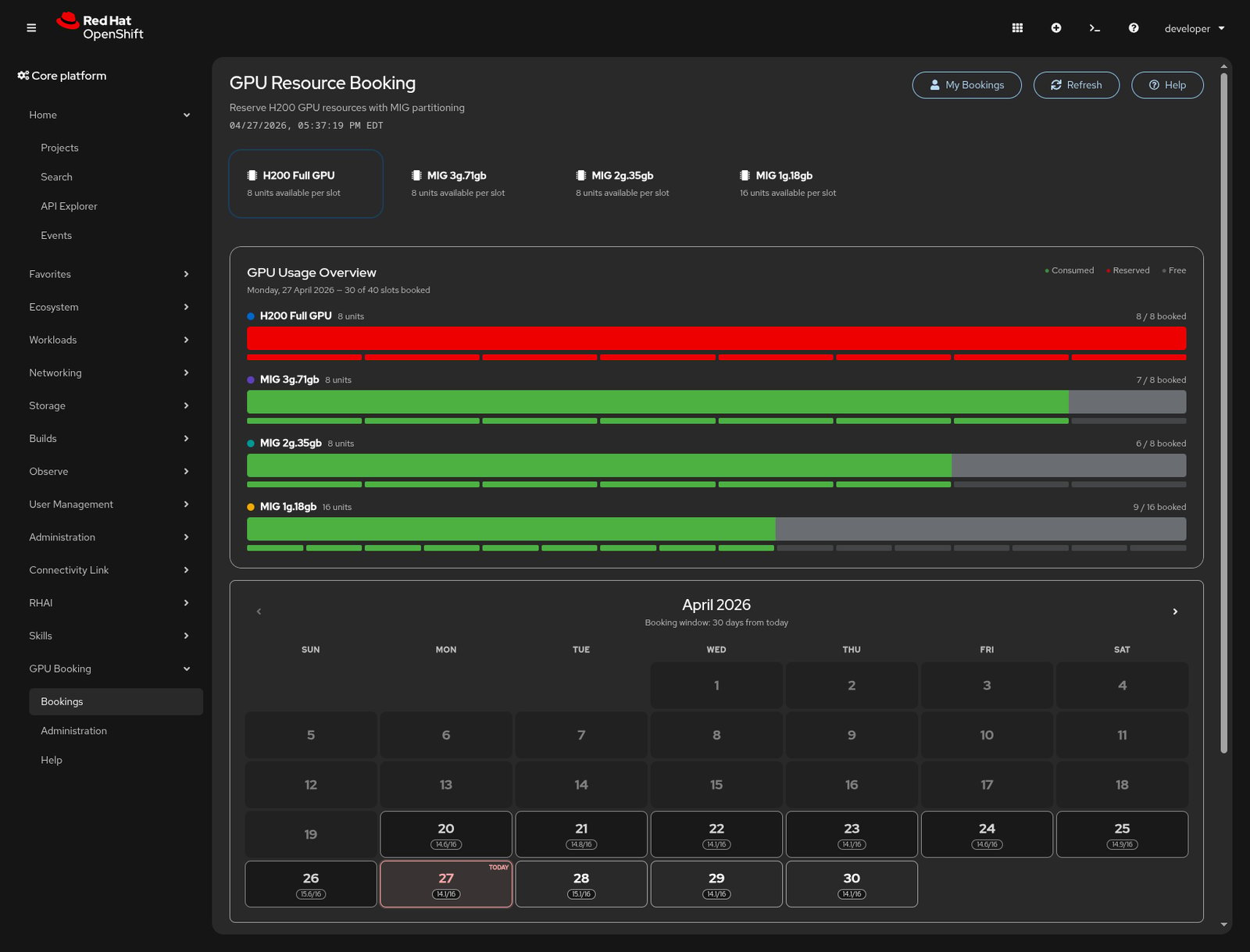
This GPU booking plug-in pulls live data from the Kueue APIs to show which resources are reserved or available, allowing you to schedule time on a calendar. The dashboard shows availability for each tier across full H200 GPUs and the three MIG slice sizes. When you're ready to reserve a slice, it's just as easy as setting the configuration and partition size. See Figure 6.
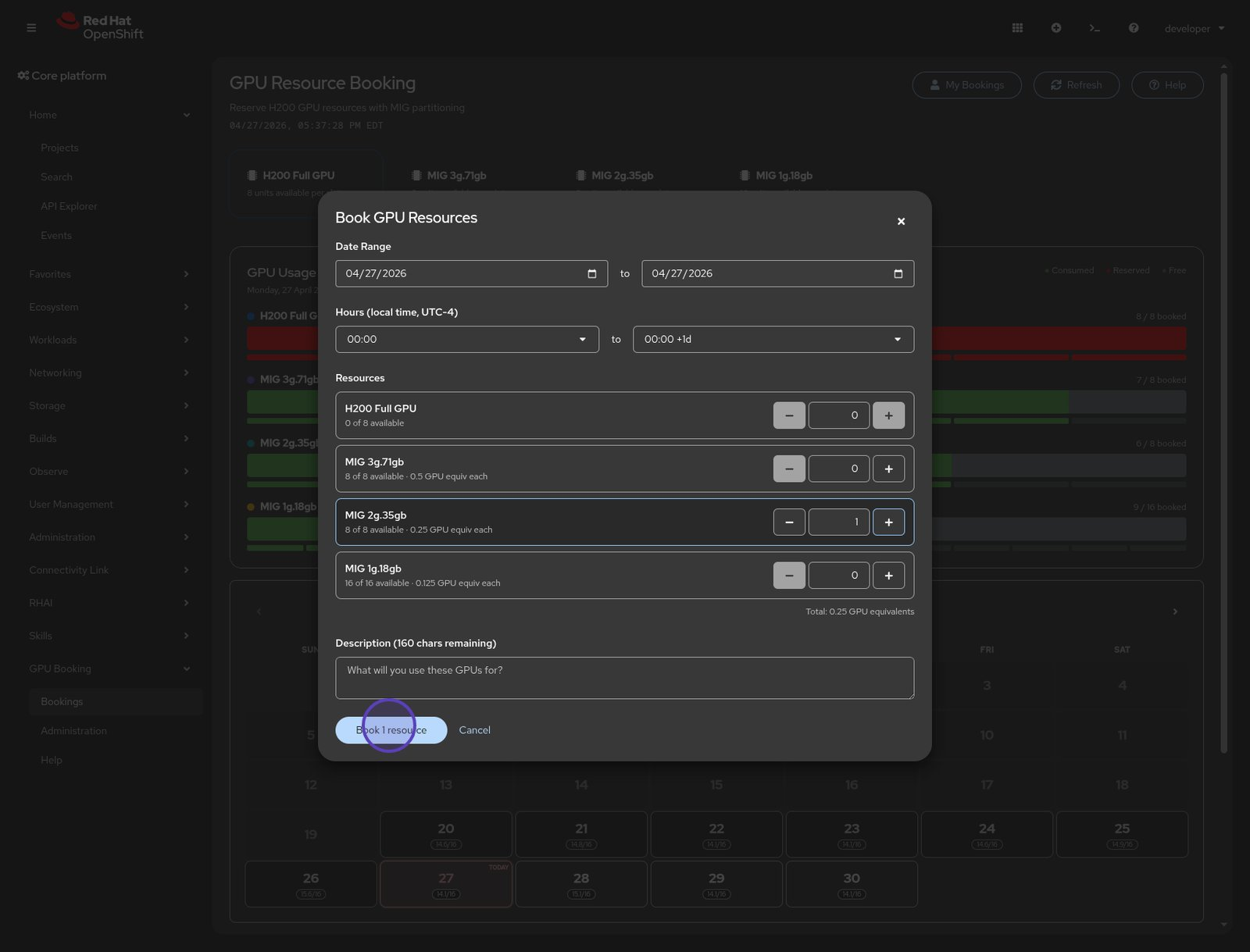
This custom plug-in relies on standard Kubernetes and Kueue architectural designs rather than introducing a unique data model. Because it generates native Kueue resources, operations tools like GitOps pipelines and the command-line interface (CLI) continue to function without interruption. Reviewing the ClusterQueue configuration shows the assigned quota for the requested MIG 2g.35gb resource size (Figure 7).
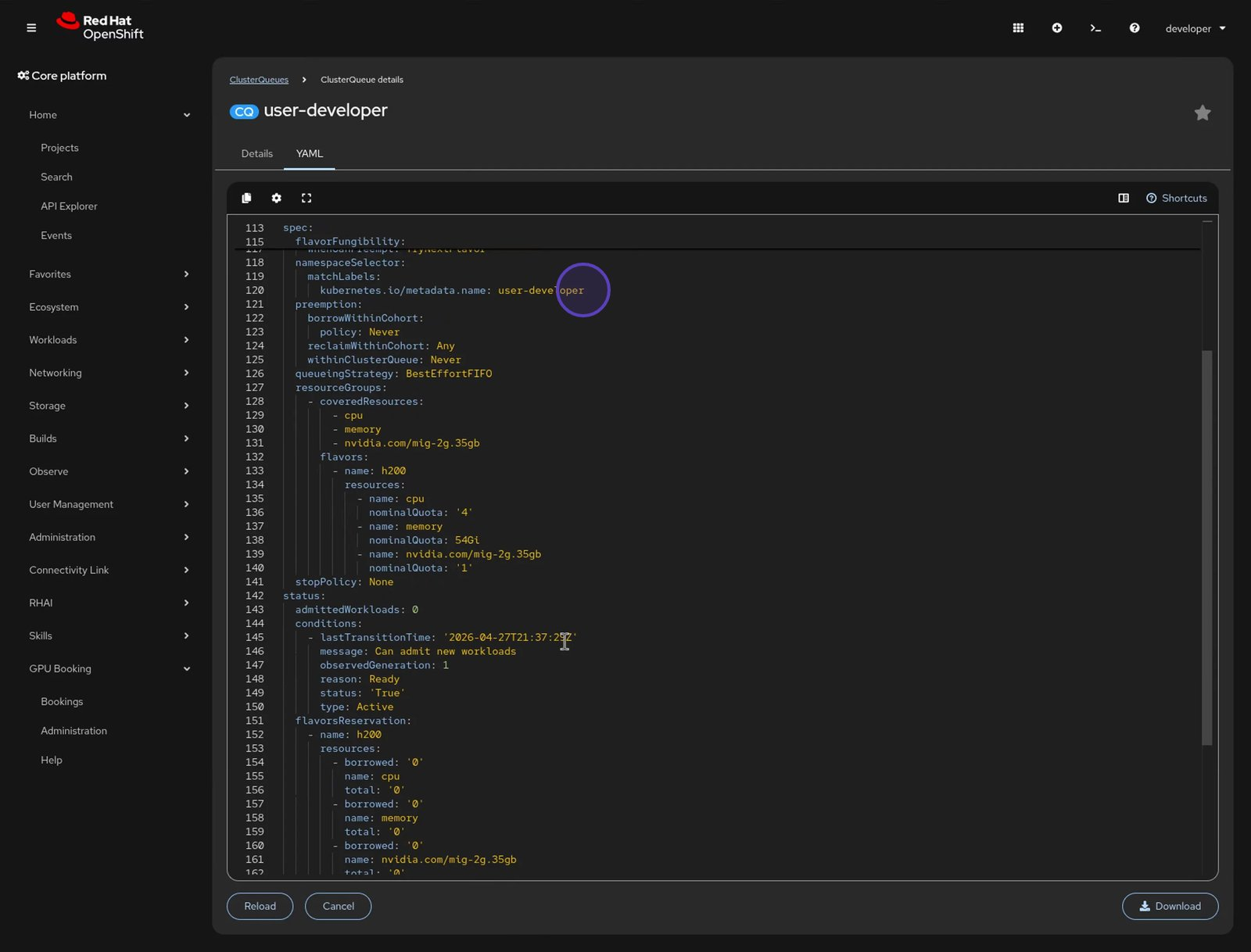
Because our plug-in uses the namespaceSelector field within the ClusterQueue, developers from other projects cannot accidentally schedule workloads against this dedicated quota. It still participates in the broader cluster cohort, so it benefits from fair sharing when other workloads aren't pushing. While our booking UI offers an accelerated way to write the YAML, the system manages all actions through native Kubernetes resources.
Deploying a model onto the reserved GPU slice
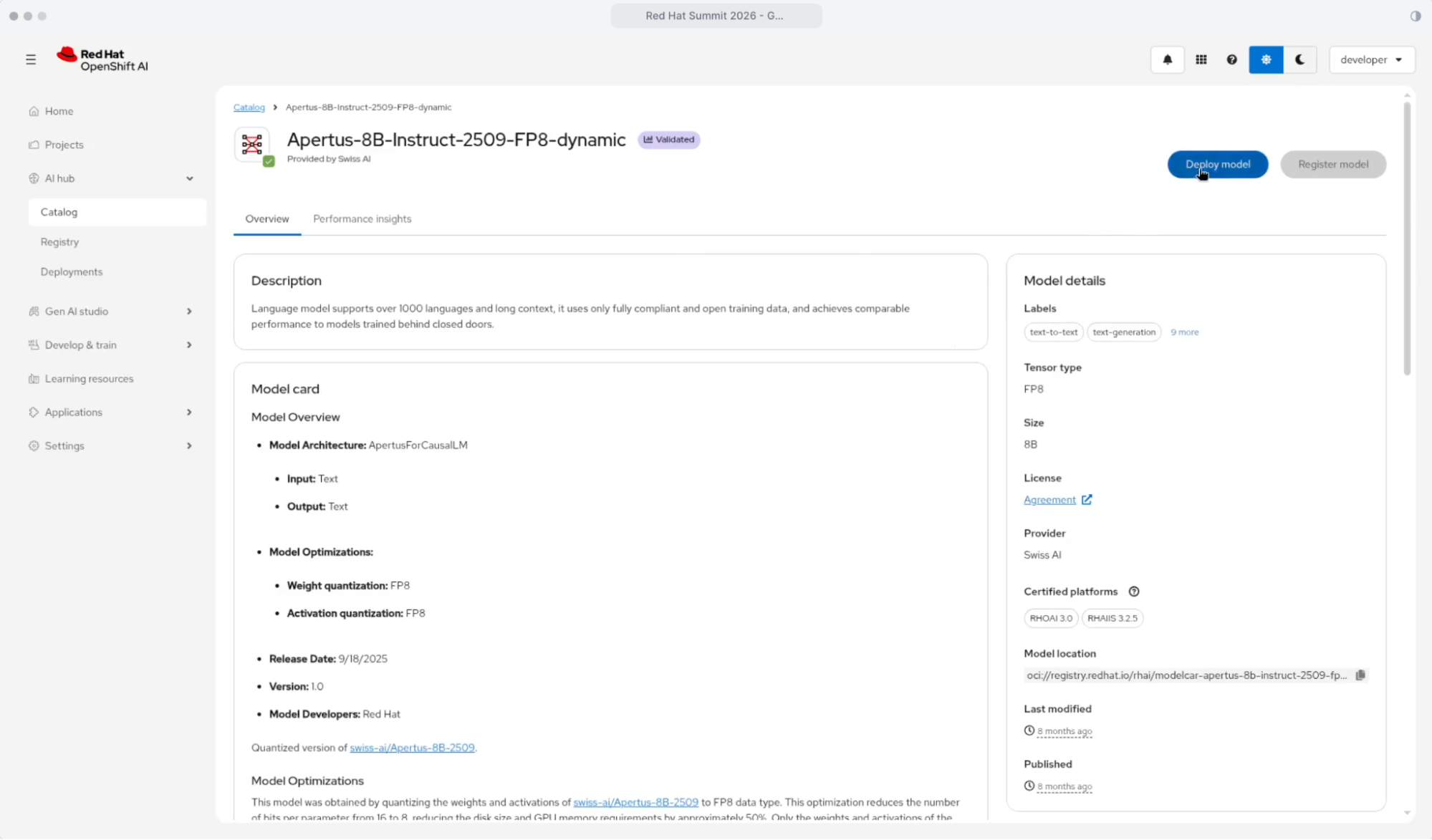
With a reservation in hand, configuring OpenShift AI is simple. You can select an appropriately sized model from the model catalog (Figure 8). Each model provides performance details and standard benchmarks across different types of accelerators, reducing the guesswork of “Will this model fit properly on my hardware?”
The deployment guide prompts you to choose a hardware profile (Figure 9). An administrator preconfigures hardware profiles to link a model deployment to a LocalQueue and its corresponding reserved ClusterQueue. The custom plug-in automates the creation of these HardwareProfile resources alongside the LocalQueue and ClusterQueue, providing immediate self-service access.
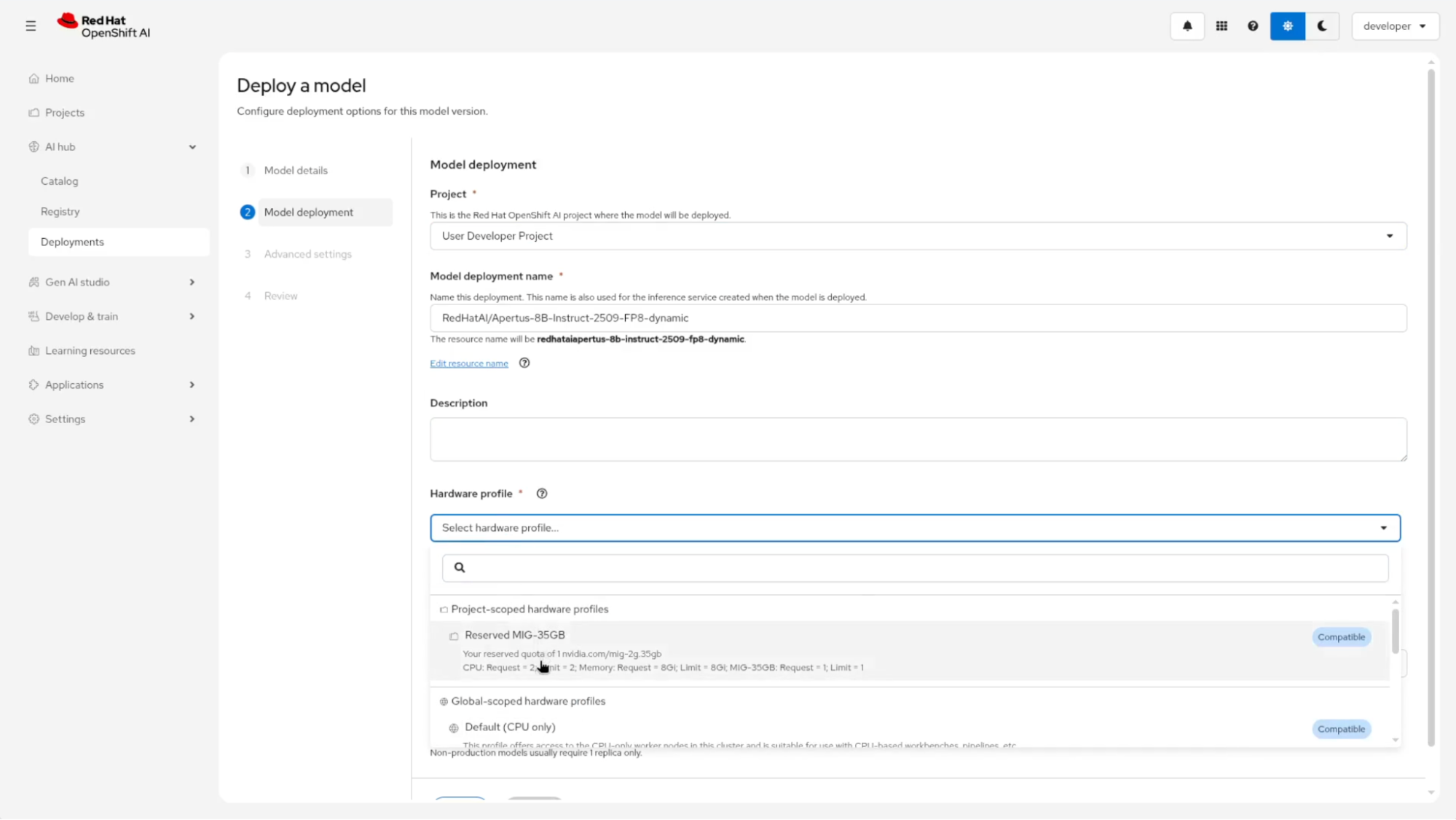
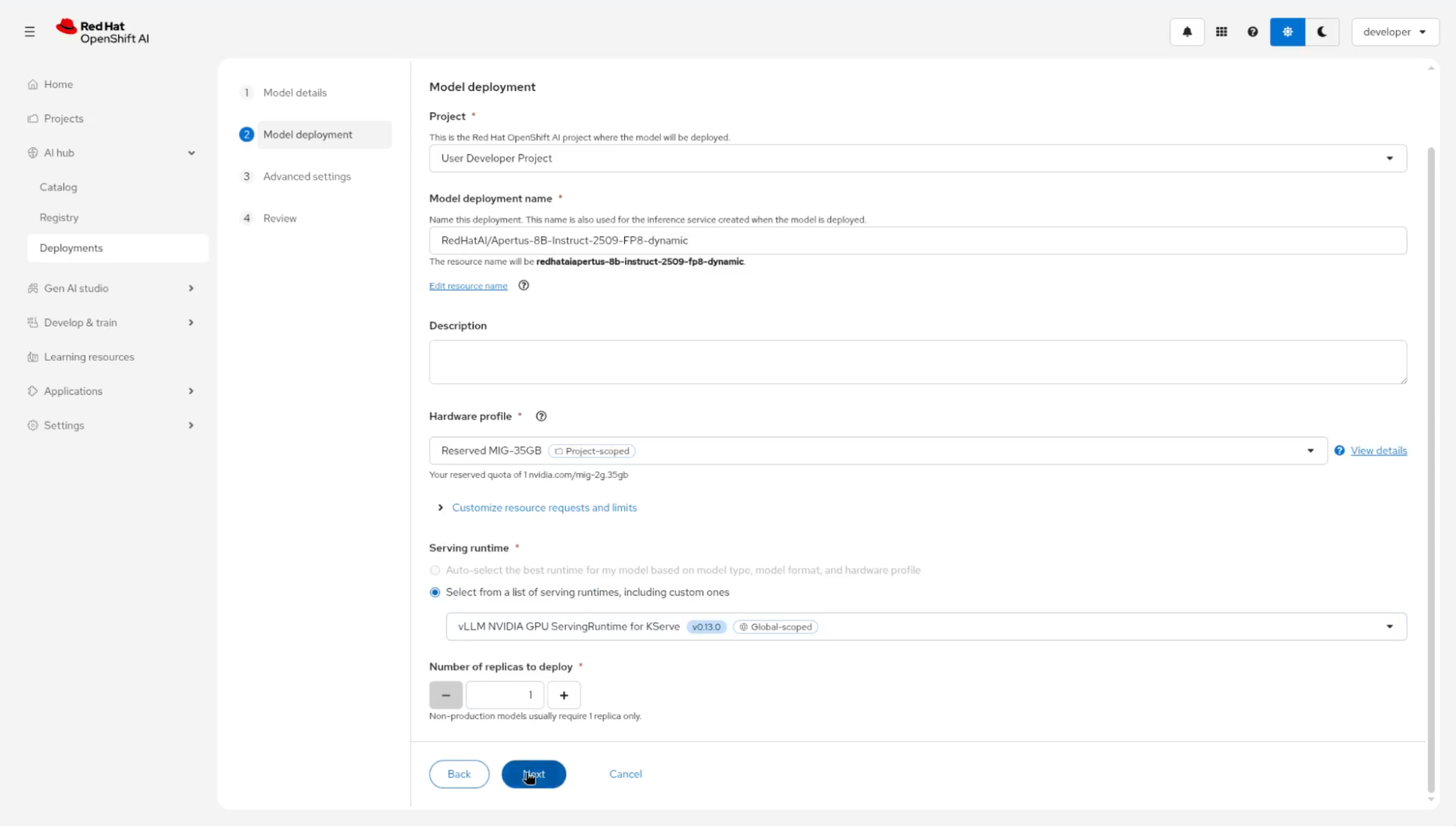
Selecting the Reserved hardware profile tethers this deployment to your booked GPU resource. The deployment operates as a standard OpenShift AI workload while executing within the defined Kueue reservation. Select the reserved profile, choose the vLLM NVIDIA image, and deploy (Figure 10). The model deploys exclusively to your reserved multi-instance GPU slice.
Why GPU-as-a-Service matters
We're seeing a wide variety of practical use cases for AI, from traditional recommendation systems to the latest AI agents and coding assistants. These workloads depend on consistent access to underlying hardware accelerators. This standardized approach allows developers to build features without being bottlenecked by tickets or GPU availability, while the platform team maintains visibility into resource use patterns. Long-running jobs like real-time inference can share resources elastically with batch jobs like AI model fine-tuning, governed by your established access policies.
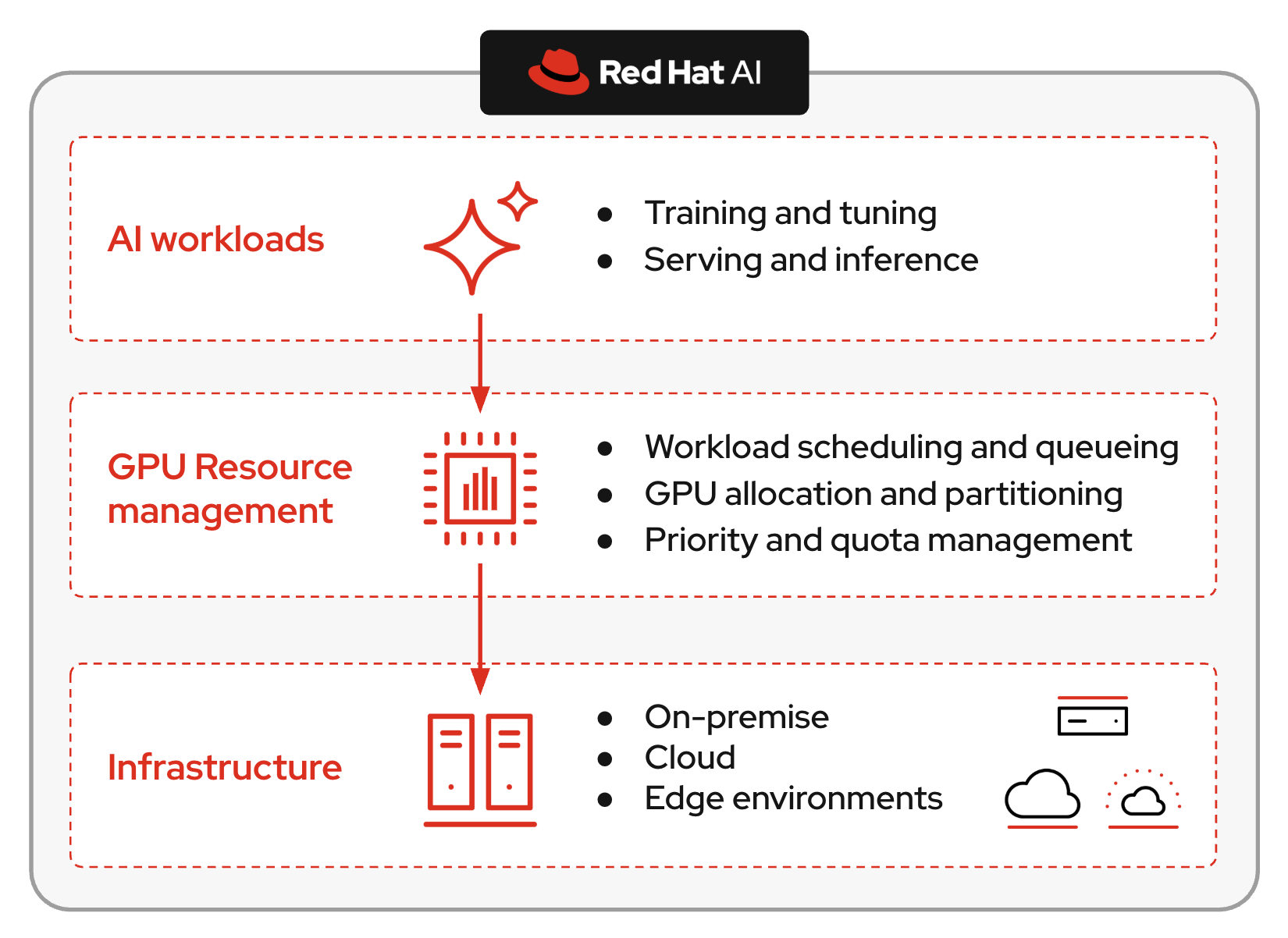
These components integrate as hybrid cloud resources using Red Hat OpenShift and OpenShift AI. Explore the interactive GPU-as-a-Service demo or visit the Red Hat AI inference product page to get started.