OVN (Open Virtual Network) is a subcomponent of Open vSwitch (OVS). It allows for the expression of overlay networks by connecting logical routers and logical switches. Cloud providers and cloud management systems have been using OVS for many years as a performant method for creating and managing overlay networks.
Lately, OVN has come into its own because it is being used more in Red Hat products. The result has been an increased amount of scrutiny for real-world scenarios with OVN. This has resulted in new features being added to OVN. More importantly, this has led to tremendous changes to improve performance in OVN.
In this article, I will discuss two game-changing performance improvements that have been added to OVN in the past year, and I will discuss future changes that we may see in the coming year.
Recent improvements
ovn-nbctl daemonization
One of our first performance targets was to determine the feasibility of supporting clusters the size of OpenShift Online. Based on some expected numbers, we set up tests where we would build the cluster to the expected size, and then simulate the creation and deletion of pods once at scale to see how OVN performed. Based on our initial testing, we were not very happy with the results. As the scale grew, the time it took to make changes to the cluster took longer and longer.
After isolating components and profiling them, we finally had a working theory on what was causing the problem: ovn-nbctl. ovn-nbctl is a command-line utility that allows for interaction with the OVN northbound database. This command is the main mechanism by which OpenShift builds its overlay network. I was able to create a shell script that mimicked the setup from our scale tests but that focused solely on the ovn-nbctl calls. Here is that script:
#!/bin/bash
# Create router
ovn-nbctl lr-add router
# Create switches
for i in $(seq 1 159); do
j=$(printf '%02x' $i)
ovn-nbctl ls-add ls$i
ovn-nbctl lsp-add ls$i lsp-ro$i
ovn-nbctl lrp-add router ro-lsp$i 00:00:00:00:00:$j 10.0.0.$i/16
ovn-nbctl set Logical_Switch_Port lsp-ro$i options:router-port=ro-lsp$i type=router addresses=router
done
for i in $(seq 1 92); do
for j in $(seq 1 159); do
k=$(printf '%02x' $i)
l=$(printf '%02x' $j)
create_addrset=$((($j - 1) % 2))
addrset_index=$((($j - 1) / 2))
ovn-nbctl lsp-add ls$j lsp${j}_10.$i.0.$j
ovn-nbctl lsp-set-addresses lsp${j}_10.$i.0.$j "00:00:00:00:$k:$l 10.$i.0.$j"
if [ $create_addrset -eq 0 ]; then
ovn-nbctl create Address_Set name=${i}_${addrset_index} addresses=10.$i.0.$j 1> /dev/null
else
ovn-nbctl add Address_Set ${i}_${addrset_index} addresses 10.$i.0.$j
fi
ovn-nbctl acl-add ls$j to-lport 1000 "outport == \"lsp${j}_10.$i.0.$j\" && ip4.src == \$${i}_${addrset_index}" allow
ovn-nbctl acl-add ls$j to-lport 900 "outport == \"lsp${j}_10.$i.0.$j\"" drop
done
done
The first loop in the script creates 159 logical switches and connects all of them to a logical router. The next set of nested loops simulates the operations performed when adding a pod to an OpenShift cluster:
- A switch port is added to one of the switches.
- The switch port's address is added to an address set. Each address set consists of two addresses. Therefore, alternating runs through the loop will either create a new address set or add the switch port's address to the address set created during the previous loop iteration.
- ACLs are created for the new port. One ACL allows traffic to the port from other addresses in its address set. The other drops all other traffic.
The loops result in 159 switches with 92 ports, totaling 14,628 logical switch ports. Each iteration of the loop calls ovn-nbctl five times, meaning there are a total of 73,460 invocations of ovn-nbctl.
When we run the script, this is the result:
$ time ./scale.sh
real 759m27.270s
user 500m40.805s
sys 36m5.682s
It's hard to draw conclusions from that time alone, but I think it's fair to say that taking over 12 hours to complete is not good. So let's have a look at how long each iteration of the inner loop takes. Click the image below to enlarge it.

As you can see in the graph, as the test continues, the amount of time it takes to complete a loop iteration increases. Towards the end, an iteration takes over seven seconds to complete! Why is this?
To understand the issue, let's start by taking a closer look at how OVSDB clients and servers work. OVSDB clients and servers communicate using JSONRPC. To prevent the need for raw JSONRPC from being embedded within client code, OVS provides a C-based IDL (interface definition language). The IDL has two responsibilities. First, at compile time, the IDL reads the schema for the databases and generates native C code to allow for programs to read and manipulate the database data in a type-safe way. Second, at runtime, the IDL acts as a translator between the C structures and JSONRPC.
A typical OVSDB client starts by determining which database it is interested in, which tables in that database it is interested in, and which columns' values within those tables it is interested in. The client formulates a request to the server asking for the current values of those databases, tables, and columns. The server responds with the current values encoded as JSON. The client's IDL then translates the JSON into native C structures. The client code can now read the contents of the database by examining C structures. If the client wants to make a modification to the database, it can make its own C data and pass it to the IDL for processing. The IDL then converts this to a JSONRPC database transaction to send to the server.
The IDL also aids the database client for messages originating from the server. If the data in the database changes, the server can send an update JSONRPC message to the client. The IDL then uses this JSONRPC to modify the C data with the updated information.
This works well for long-running OVSDB clients. After the initial dump of the current database, interaction between the client and server happens in small chunks. The problem with ovn-nbctl is that it is a short-lived process. ovn-nbctl starts up, requests all data from the northbound database, processes that JSON data into C data, and then usually performs a single operation before exiting. Through our profiling, what we found was that the majority of time was spent by ovn-nbctl processing the initial database dump at startup. This makes sense when you consider the amount of data being processed as the test reaches its conclusion.
The solution we created was to make ovn-nbctl have the option of being a long-running process. ovn-nbctl has been outfitted with an option to allow the OVSDB client portion of it to run in the background continuously. Further invocations of ovn-nbctl pass the command to the daemon process. The daemon process then passes the result of the command back to the CLI. By doing it this way, the OVSDB client only requires a single database dump from the server, followed by gradual updates of the content. ovn-nbctl processes can run much faster since they no longer require a dump of the entire database every time.
The solution was initially implemented by Jakub Sitnicki of Red Hat and then improved upon by Ben Pfaff of VMware.
The actual mechanism for running ovn-nbctl as a daemon is simple. You can run the following command:
$ export OVN_NB_DAEMON=$(ovn-nbctl --pidfile --detach)
By setting the OVN_NB_DAEMON variable, any further calls to ovn-nbctl will connect to the daemon process.
With this improvement in place, we modified the previous script to have the daemonization line at the beginning. Running the modified script results in the following:
$ time ./scale-daemon-new.sh real 5m9.950s user 1m18.702s sys 1m41.979s
That is considerably faster! It's over 99% faster, in fact. Here is a graph of each loop iteration. Click the graph to enlarge it.
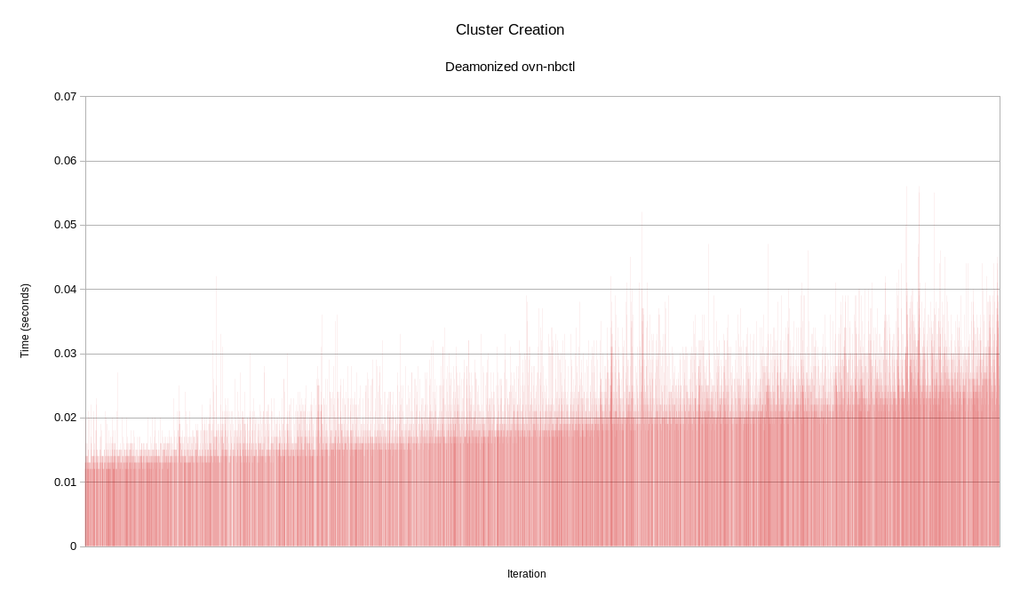
That is a lot more flat than we previously saw. There still is a slight increase over time. That is due to certain ovn-nbctl commands becoming more complex as the total data size grows. The scale of the growth is much smaller than in the previous run.
Port groups
Another bottleneck seen in OVN testing was a tremendous slowdown when ACLs were heavily used. Here's a script that illustrates the issue well:
#!/bin/bash
NUM_PORTS=${1:-100}
ADDR_SET="\"10.1.1.1\""
for x in 1 2 3 4 ; do
for y in {0..255} ; do
ADDR_SET="${ADDR_SET},\"10.0.$x.$y\""
done
done
ovn-nbctl create Address_Set name=set1 addresses=$ADDR_SET
ovn-nbctl list Address_Set
ovn-nbctl ls-add ls0
COUNT=0
while test ${COUNT} -lt ${NUM_PORTS} ; do
echo "ovn lsp$COUNT"
ovn-nbctl --wait=hv lsp-add ls0 lsp${COUNT}
ovn-nbctl acl-add ls0 to-lport 1000 "outport == \"lsp${COUNT}\" && ip4.src == \$set1" allow
ovs-vsctl add-port br-int port${COUNT} \
-- set Interface port${COUNT} external_ids:iface-id=lsp${COUNT}
COUNT=$[${COUNT} + 1]
done
Let's discuss what's happening in the script. First, an address set called set1 is created that has 1,020 IP addresses in it (10.0.1.0 through 10.0.4.255). We then create a logical switch ls0 and add NUM_PORTS to it. NUM_PORTS defaults to 100, but this can be changed to any value by passing an argument to the script. In our testing, we use 1000 for NUM_PORTS. In addition to creating the port, we also add a new ACL that allows traffic to go to this new port from any of the addresses in our address set. There are two important other lines here as well
- The
ovn-nbctl lsp-addcommand contains--wait=hv. This means that the command will block until it has been processed byovn-controllerprocesses running on all hypervisors. In our case, we are running in the OVS sandbox, so there is only one hypervisor. That means just waiting for a singleovn-controllerto finish. - There is an
ovs-vsctl add-portcommand to bind the logical switch port to the OVSbr-intbridge. This makes it so that OpenFlow can be generated byovn-controllerfor this particular logical switch port.
This particular script is not far-fetched. The number of addresses in the address set may be larger than a typical deployment, but this pattern is commonly used by deployments when using ACLs. They create ACLs that are mostly identical aside from the logical switch port that the ACL applies to.
Let's see what happens when we run this script and create 1,000 logical switch ports.
$ time ./load_net.sh 1000 real 125m16.022s user 2m47.103s sys 0m11.376s
The script takes over two hours to complete. Like before, it's hard to gauge anything based on a time alone. Let's look at what happens when we time each iteration in the loop. Click the picture to enlarge it.

Like with the ovn-nbctl issue before, we can see that the time increases steadily as the test goes on. As the network gets more ACLs, it takes longer for the loop to complete. Why is this?
The answer has to do with the way that ovn-controller generates OpenFlow. Despite the fact that our ACLs reference a 1,020-member address set as a single unit, that does not translate directly into OpenFlow. Instead, the address set has to be expanded into each individual address, and each individual address is evaluated in a separate flow. When we add our first port, ovn-controller generates OpenFlow similar to the following for our ACL in OpenFlow table 44:
priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.1.1 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.1.2 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.1.3 actions=resubmit(,45) ... priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.255.255 actions=resubmit(,45)
As an explanation:
- Table 44 is on the logical switch egress pipeline, and it is where flows pertaining to
to-lportACLs are written. metadatais an identifier for the datapath of the packet. In this case, 0x1 refers to our logical switch.reg15is an OpenFlow register that stores the output port number. In this case, 0x1 refers to the first logical switch port we have added. The flow checks the output port because our ACL was ato-lportACL. If it had been afrom-lportACL, then we would have checked the input port instead, and we would do it in a different OpenFlow table.nw_srcis the network layer source address.- The
resubmit(,45)action allows for processing to continue at OpenFlow table 45. The action is "resubmit" in this case because our ACL had an "allow" action on it. If it had been "drop," then the flow would haveactions=dropinstead.
So in this case, we've created 1,020 flows, one for each address in our address set. Now let's see what happens when we add our second port:
priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.1.1 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x2,nw_src=10.0.1.1 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.1.2 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x2,nw_src=10.0.1.2 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.1.3 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x2,nw_src=10.0.1.3 actions=resubmit(,45) ... priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.4.255 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x2,nw_src=10.0.4.255 actions=resubmit(,45)
We now have added an identical set of flows, except that reg15 matches 0x2 instead of 0x1. In other words, we've created another 1,020 flows for the new port we added. You may notice a pattern forming. The number of flows generated in table 44 is approximately the number of ports multiplied by the number of addresses in the address set. Let's count the total number of flows in our table after completing the script:
$ ovs-ofctl dump-flows br-int | wc -l 1033699 $ ovs-ofctl dump-flows br-int | grep table=44 | wc -l 1025001
There are over a million flows, and table 44 accounts for 99% of the total. Bear in mind that in our script, we have --wait=hv present when adding our logical switch port. This means that we have to wait for ovn-controller to generate every flow every time that we add a new switch port. Since the table is growing by 1,020+ flows every iteration, it eventually starts to take tens of seconds to add a single port.
The solution to this issue is to try to minimize the number of flows generated. There's actually a built-in construct in OVS's OpenFlow implementation called a conjunctive match. A conjunctive match allows for OpenFlow rules that exist in the same table and that have the same resulting action to be combined into a more compact form. If these rules have similar match criteria, then a list of flows pertaining to the first part of the common match criteria can be made, followed by a list of flows pertaining to the second part, and so on until all parts are matched.
Consider the previous set of flows. All of the flows exist in table 44 and have the same action of resubmitting to table 45. All of the flows match first on a port number, and then they all match on a set of IP addresses. What we want is a conjunctive match of two parts. The first part will match on every valid port, and the second part will match on every IP address in our address set. Each time we add a new port, the first part of the conjunctive match will have a new flow added to it, but the second part will remain the same. By doing this, the number of flows in table 44 could be approximated by the number of ports plus the number of addresses in the address set.
To get a conjunctive match generated, several ideas were presented. The one that won out was for the addition of a feature called port groups. A port group is a simple construct that allows for a number of logical switch ports to be referred to by a single collective name. References to port groups can be made in ACLs in place of where you would normally refer to a single port. Port groups have other nice features, but those lie outside the scope of this particular article.
Port groups were initially implemented by Han Zhou of eBay, but loads of other contributors have fleshed out the feature and improved it since.
Now let's rewrite the script using port groups. The major difference will be that instead of defining new ACLs for every port we add, we will define a single ACL that refers to a port group. As we create new logical switch ports, we will add the port to the port group. Having all ports and IP addresses expressed in a single ACL should allow for the conjunctive match to be created. Here is the resulting script:
#!/bin/bash
NUM_PORTS=${1:-100}
ADDR_SET="\"10.1.1.1\""
for x in 1 2 3 4 ; do
for y in {0..255} ; do
ADDR_SET="${ADDR_SET},\"10.0.$x.$y\""
done
done
ovn-nbctl create Address_Set name=set1 addresses=$ADDR_SET
ovn-nbctl list Address_Set
ovn-nbctl ls-add ls0
ovn-nbctl create Port_Group name=pg1
ovn-nbctl acl-add ls0 to-lport 1000 "outport == @pg1 && ip4.src == \$set1" allow
ovn-nbctl acl-list ls0
COUNT=0
while test ${COUNT} -lt ${NUM_PORTS} ; do
echo "ovn lsp$COUNT"
ovn-nbctl --wait=hv lsp-add ls0 lsp${COUNT}
port=$(ovn-nbctl get Logical_Switch_Port lsp${COUNT} _uuid)
ovn-nbctl add Port_Group pg1 ports $port
ovs-vsctl add-port br-int port${COUNT} \
-- set Interface port${COUNT} external_ids:iface-id=lsp${COUNT}
COUNT=$[${COUNT} + 1]
done
As you can see, the construction is mostly similar. Notice that we refer to port group pg1 using the @ sign when defining our ACL. This lets OVN know that we are referring to a port group and not a single port in our ACL. Let's see what happens when we run this script and create 1,000 logical switch ports.
$ time ./load_net_pg.sh 1000 real 6m23.696s user 3m15.920s sys 0m10.849s
Now the script takes only about 6 minutes to complete. That's a 95% improvement! Here is a graph of each iteration of the loop. Click the picture to enlarge it.
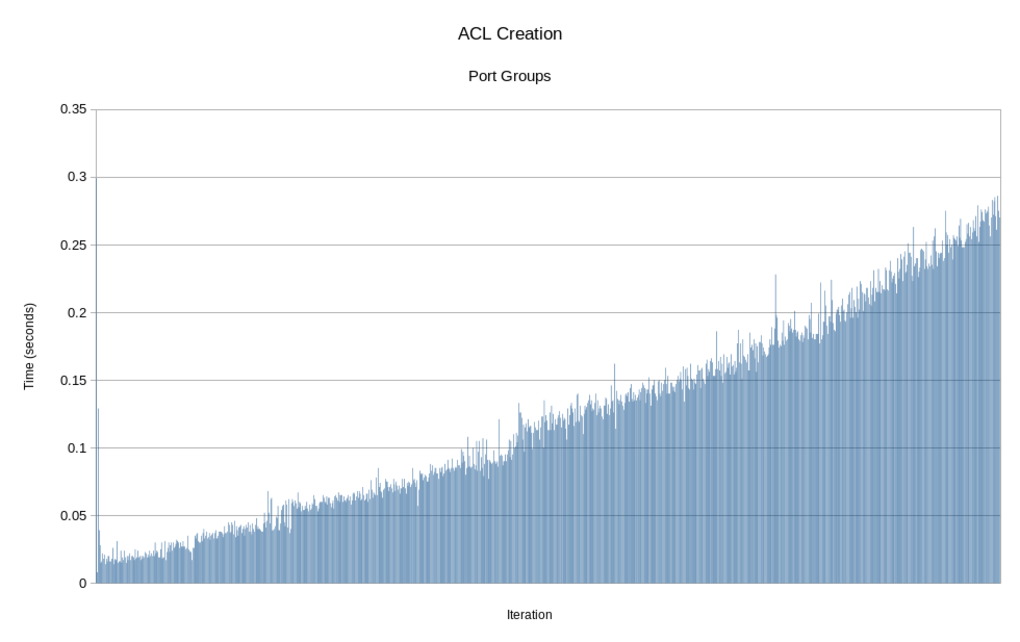
The time is still increasing on each iteration, but if you look at the scale on the y-axis, you can see the times are much lower. To put it in perspective, these are the two graphs superimposed on each other. Click the picture to enlarge it.
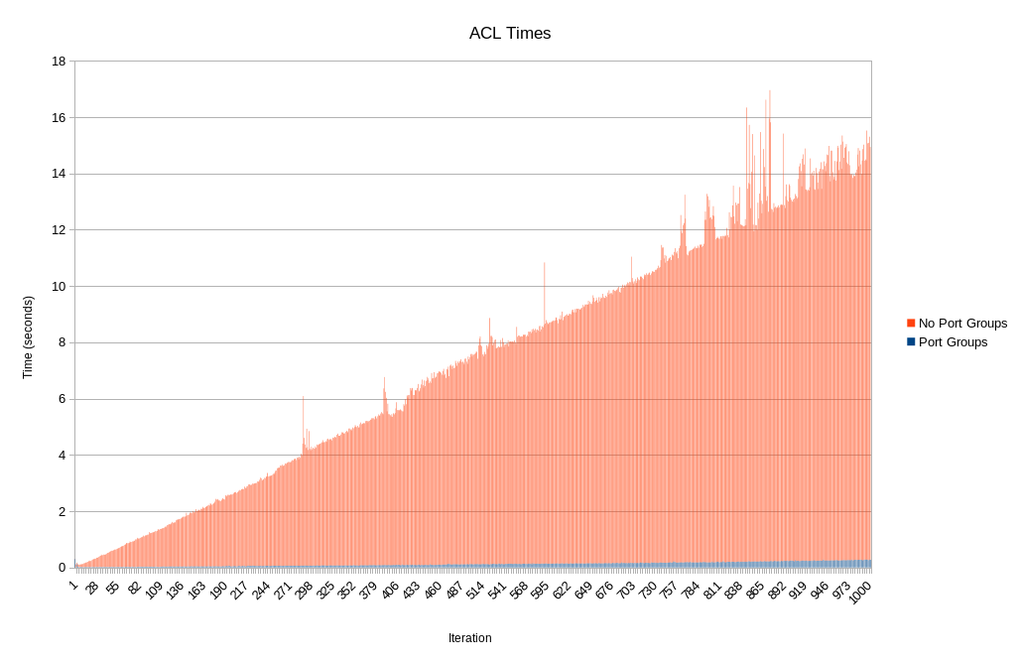
You can see the blue bars starting to appear in the bottom right of the graph if you squint just so...
Let's take a look at the flows generated at each step. After adding one switch port, the OpenFlow looks like this:
priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.1.1 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.1.2 actions=resubmit(,45) priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.1.3 actions=resubmit(,45) ... priority=2000,ip,metadata=0x1,reg15=0x1,nw_src=10.0.4.255 actions=resubmit(,45)
So far, it's exactly the same as when we didn't use port groups. Now let's add a second port.
priority=2000,conj_id=2,ip,metadata=0x1 actions=resubmit(,45) priority=2000,ip,metadata=0x1,nw_src=10.0.1.1 actions=conjunction(2,1/2) priority=2000,ip,metadata=0x1,nw_src=10.0.1.2 actions=conjunction(2,1/2) priority=2000,ip,metadata=0x1,nw_src=10.0.1.3 actions=conjunction(2,1/2) ... priority=2000,ip,metadata=0x1,nw_src=10.0.4.255 actions=conjunction(2,1/2) priority=2000,ip,reg15=0x1,metadata=0x1 actions=conjunction(2,2/2) priority=2000,ip,reg15=0x2,metadata=0x1 actions=conjunction(2,2/2)
And there's the conjunctive match we were after! The top line creates the conjunctive match. The ID of the conjunctive match is 2, and it states that if all requirements of the conjunctive match are met, then the action is to resubmit to table 45. The rest of the lines define the requirements of the conjunctive match with their conjunction actions. The 2 before the comma indicates they are a requirement for the conjunctive match with ID 2. The numbers after the comma indicate the requirement number and total number of requirements of the conjunctive match. All of the flows that end with 1/2 in their conjunction action pertain to the source IP address. All flows with 2/2 in their conjunction action pertain to the output logical switch port. The conjunctive match results in the same logical set of actions to take but expresses it in a more compact way.
After loading our network up with 1,000 switch ports, let's examine the total number of OpenFlow flows generated.
$ ovs-ofctl dump-flows br-int | wc -l 9098 $ ovs-ofctl dump-flows br-int | table=44 | wc -l 2027
That is three orders of magnitude fewer flows than before. Now table 44 accounts for only 22% of the total flows. This makes a world of difference in the time it takes for ovn-controller to generate the flows.
Mixing the optimizations
One thing you may have noticed in our ACL generation script is that we did not use a daemonized ovn-nbctl. We discussed in the first section how great an optimization that is, so let's see how that makes a difference here.
$ time ./load_net_pg_daemon.sh real 3m50.670s user 0m20.340s sys 0m8.608s
Not bad! We got another 40% speedup over the non-daemonized version.
And since we're crossing streams here, what happens if we take our script from the ovn-nbctl daemonization section and use port groups with it? Here are the results:
$ time ./scale-daemon-new-pg.sh real 3m33.457s user 1m1.614s sys 1m24.891s
There's a 31% speedup, but it's not due to the same reasons we saw with conjunctive matches earlier. Since there is no --wait=hv in the script, we are not waiting for ovn-controller to generate flows. The big reason for the speedup is because using port groups requires fewer calls to ovn-nbctl than we previously used.
Future improvements
Incremental processing
One thing you may have noticed from the port groups section was the fact that ovn-controller has to generate the entire OpenFlow table every time it reads the contents of the southbound database. ovn-northd works similarly: it always reads the entire northbound database in order to generate a complete new set of southbound data. Operating this way has some distinct advantages.
- The code is easy to reason about.
- The code is resilient in the case of temporary connectivity failures.
What overshadows these advantages is that this method is slow, computationally expensive, and it gets worse as the size of the dataset increases. A huge performance boost can be gained by processing the changes to the database rather than all content in the database.
This is a difficult thing to do in practice. There have been multiple attempts to refactor ovn-controller to process results incrementally. The most common issue with these implementations is increased difficulty in maintaining the code. A common problem seen throughout all attempts is that C doesn't provide the easiest way of implementing an incremental processing engine.
Having examined the problems with past attempts and understanding the best way to move forward, engineers at VMware have started an effort to rewrite portions of OVN in a different language than C. They have created a language called Differential Datalog, commonly abbreviated DDlog. DDlog at its core is an incremental database processing engine. This is exactly what is needed in order to get more performant processing. Ben Pfaff sent a good e-mail to the ovs-discuss mailing list with a summary of the project.
So what sort of benefits can we expect from incremental processing? Han Zhou of eBay put together a proof-of-concept C version of incremental processing for ovn-controller. In tests run by him and me, we found around a 90% reduction in CPU usage by ovn-controller. We also found about a 90% speedup in ovn-controller's general operation. Unlike the optimizations discussed in the previous sections, this doesn't apply to specific use cases, but rather provides an optimization for ALL operations by ovn-controller. DDlog's experimental results on ovn-northd shows similar improvements. This presentation by Leonid Ryzhyk provides some graphs illustrating the immense speedup seen with DDlog's incremental computation over the current C implementation at all cluster sizes.
The conversion to DDlog is a work in progress. The intent is to have the DDlog of ovn-northd finished and integrated into OVN by the release of version 2.11. Once the implementation drops, we encourage everyone to deploy it and tell us about the performance improvements you see. For those of you who are more hesitant about deploying a rewritten OVN component in your live environments, don't worry! The C implementation of ovn-northd will still be present, and you can choose to continue using it instead. But you'll be missing out on the amazing performance improvements of the DDlog implementation.
Other future improvements
Incremental processing is the foundation on which all future improvements are based. However, even with incremental processing, there are some future smaller improvements that we can visualize. Here is a brief list of possible improvements.
Incremental flow processing
ovn-controller currently creates a collection of all desired flows that it wants to install in OVS. It also maintains a collection of all flows currently installed in OVS. On each iteration, ovn-controller must determine the difference between the two collections and then send appropriate modification messages to OVS. With incremental processing in place, it naturally follows that we can incrementally calculate the flows to install as well. When testing Han Zhou's C implementation of incremental processing, the comparison between desired and installed flows was the new top user of CPU time.
Pass incremental changes directly
Once incremental processing is put in place, ovn-northd will calculate some change to make to the southbound database and make that change. ovn-controller will take the southbound database contents, determine what has changed, and act on those incremental changes. If ovn-northd has already calculated what the changes to the southbound database are, perhaps there could be a way to pass the changes directly between ovn-northd and ovn-controller. This could eliminate some repetitive processing in the two daemons. It's also possible to save some hard drive space that the southbound database would take up.
Of the possible improvements that could be made, this likely would be the most difficult to get right. This is because multiple ovn-controller daemons connect to the OVN southbound database. Therefore, trying to calculate a universal delta of changes means that it's easy for an ovn-controller to miss an update.
Even if this cannot be done across the board for all southbound data, perhaps something could be done specifically for the southbound Logical_Flow table. That table tends to grow larger than any other southbound table.
Better conjunctive match generation
We touched on how previously, conjunctive matches greatly helped to lessen the number of flows that are installed by ovn-controller. The expression parser in ovn-controller has difficulty generating conjunctive matches in situations where it really should be able to. It takes some more complex analysis of the resulting flows than currently exists in ovn-controller. If the expression parser could be made smarter, there might be some savings that could be made to the number of flows generated.
Centralize expression parsing
Currently, ovn-controller reads through logical flows from the southbound database and parses the expressions in order to generate flows for OVS. While there are some logical flows whose resulting parsed form will differ between hypervisors, most of the parsed expressions will be exactly the same no matter where they are parsed. Perhaps some computing power on the hypervisors could be saved by parsing expressions centrally instead.
Final thoughts
OVN development is entering an exciting time. Being able to improve performance on such a grand scale is a great sign that the software is maturing. With the introduction of incremental processing, I believe that control plane performance concerns will completely disappear. The use of OVN will become a natural fit for anyone that wants to use OVS in their environments, adding very little overhead.
I suspect that as word gets out about the performance improvements, adoption of OVN will increase even more. Increased adoption means that in addition to no longer needing to focus on performance, we can expect to see a bevy of new features added to OVN in the near future.
If you are interested in contributing, I strongly encourage you to get involved now. This could be the beginning of a golden age of new OVN features to add.
Additional resources
- Open Virtual Network articles on the Red Hat Developer blog
- Open vSwitch articles on the Red Hat Developer blog
- How to create an Open Virtual Network distributed gateway router
- IP packet buffering in OVN
- Dynamic IP Address Management in Open Virtual Network (OVN): Part One
- Network debugging with eBPF (RHEL 8 Beta)
- Introduction to Linux interfaces for virtual networking
- Troubleshooting FDB table wrapping in Open vSwitch
- Troubleshooting Open vSwitch DPDK PMD Thread Core Affinity
- Debugging Memory Issues with Open vSwitch DPDK
- Open vSwitch: Overview of 802.1ad (QinQ) Support
