This post is the first in a series of three related posts that describes a lightweight cloud-native distributed microservices framework we have created called EventFlow. EventFlow can be used to develop streaming applications that can process CloudEvents, which are an effort to standardize upon a data format for exchanging information about events generated by cloud platforms.
The EventFlow platform was created to specifically target the Kubernetes/OpenShift platforms, and it models event-processing applications as a connected flow or stream of components. The development of these components can be facilitated through the use of a simple SDK library, or they can be created as Docker images that can be configured using environment variables to attach to Kafka topics and process event data directly.
Background
Event processing is a methodology for reasoning about streams of potentially real-time events and data and generating conclusions based on both their absolute values and their temporal characteristics. Streams of events can come from many sources; they could be generated by parts of an organization (for example, patterns of orders, sales calls. etc.), they could be aggregated from external sources (for example, occurrences of news items, stock prices, etc.), collected from sensors (Internet-of-Things applications have the potential to generate vast quantities of streaming data), or even emitted by changes occurring within a cloud hosting platform.
Despite the attraction of being able to react in real time to streams of information, the actual process of creating and deploying event-driven systems is complex. In addition to managing the actual business logic for event processing, there are additional considerations to take into account when deploying this logic to produce a functioning system:
- Code must be built and packaged in a form suitable for deployment within a container environment. This is largely dealt with using tooling such as Maven with the relevant plugins (typically, the fabric8 plugin). However, the responsibility of installing and connecting to the underlying messaging middleware is still the responsibility of the developer.
- The process of modifying and scaling applications needs to be carefully managed. Adding additional compute resources to ease bottlenecks requires new resources to be brought on-stream and integrated into a running system without interfering with existing operations. Likewise, removing surplus resources needs to be done in a way that doesn’t affect the overall semantics of the application. This is particularly significant if the additional resources are located in remote cloud platforms (for example, a cloud bursting operation).
Given the benefits and challenges associated with efficiently processing event data, it is not surprising that a large number of platforms have been created.
It is important to realize that we made no attempt to re-create the functionality offered by libraries such as the Apache Kafka Streams API. Instead, we created a framework for connecting streaming components (some of which may themselves contain Apache Kafka Streams API code) into a coherent data flow that can be deployed and managed in a container platform.
Also, the framework described in this post was designed specifically to operate at scale within a container platform and was written using an entirely cloud-native approach. This approach has a number of distinct advantages:
- Container platforms are well suited to dealing with varying levels of load because the architecture makes it extremely easy to scale up or down parts of an application in response to different levels of demand.
- By adopting a cloud-native first approach, we can leverage the various management, data representation, and monitoring tools that are already provided by the container platform.
- The inherent flexibility in terms of implementation languages afforded by a platform such as OpenShift means that applications can be built using a variety of different toolkits and languages and still operate on the same stream of events.
In this post, we will focus on processing CloudEvents, which provide a standard mechanism for describing event data in a platform-independent manner. The CloudEvents specification aims to make it easier to write portable applications that produce and consume event-based services. The specification provides a base level of metadata, which might be of interest for an event, and the payload, which can be of arbitrary structure. CloudEvents are distinct from a binding to any particular serialization format, but the event-flow platform uses a JSON representation of them. Even though we are focussing on CloudEvents in this post, the EventFlow platform is not specific to them. It can be used to transport any other type of "serializable" data between processors.
EventFlow architecture
For the purposes of the EventFlow platform, an application is modelled as a connected set of processors (P1,P2, and P3). Event data flows between these processors along logical connections (C1 and C2):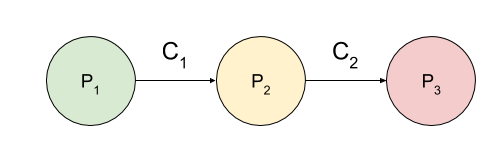
In order to participate in such a flow, any code written by a developer needs to fit into one of three categories:
-
- Data Source: Code that falls into this category produces a stream of data that is passed to other processors via a connection. Data sources are typically located at the beginning of an event flow and can be thought of as a bridge between an external system and the stream processing application.
- Data Sink: Data Sinks receive data from other processors in a flow and act upon it without any more downstream flow operations. An example of a Data Sink could be code that receives data at the end of a flow and inserts results into a database.
- Data Processor: Data Processors act as both a Data Source and Data Sink processing a stream of input event data and producing a stream of output data. An example of a Data Processor could be an operation that filters a stream of raw data for significant events that are passed to the output stream for further downstream processing.
Because the components within a flow are deployed as OpenShift pods, we can support varying levels of message throughput, by increasing or decreasing the number of deployed pods for each component. For example, a flow containing a computationally expensive step (P2 in the figure below) could have extra replicas of the bottleneck processor deployed to cope with the throughput. (EventFlow supports replicas deployed both in the local cloud environment and/or in remote cloud environments):
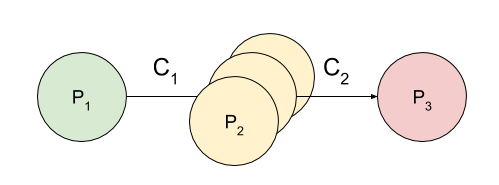
In order to connect processors together and the manage the distribution of events between replicas, we make use of Apache Kafka (as provided by the Red Hat AMQ Streams product) deployed within the container platform. For the example shown in the first figure, the two inter-processor connections (C1 and C2) are represented using two separate Kafka topics.
When a flow is deployed within the container platform, the components within the flow are represented as follows:
-
- Flow: The definition of the flow (whether it is created using a graphical editor or from the Kubernetes k8s API) is stored as a Custom Resource within the container platform.
- Processor: Processors are deployed as containers within OpenShift. During the process of developing a Processor, a Docker image is created and uploaded to a registry. Deployed replicas of this image are responsible for performing the actual processing tasks.
- Connections: The process of deploying the Kafka topics that represent connections within the data flow involves creating a Custom Resource for each Topic. Red Hat AMQ Streams contains an operator that responds to changes in these Custom Resources by creating, removing, or modifying the appropriate Kafka topics.
These concepts are illustrated below:
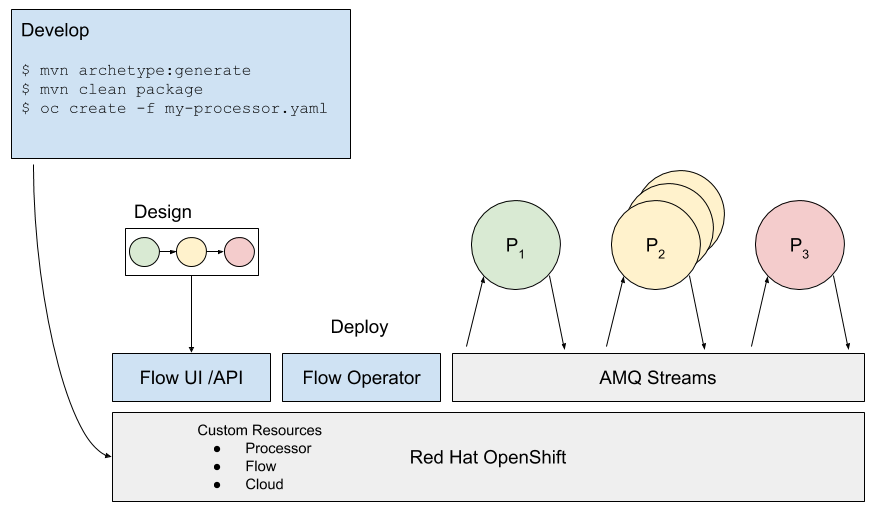
Developing, designing, deploying, and managing flows
Given the high-level overview presented above, making use of the event-flow platform requires developers to consider a set of tasks ranging from the development of event processing code to the management of deployed replicas and connections to remote clouds.
Develop: Maven archetypes for developing processors
Maven archetypes can be used to provide scaffolding for developers creating processors that the event flow can include. The event-flow SDK provides interfaces that can be used to produce and consume CloudEvents with very little effort from the developer. For example, the following code will log the events it receives. The event-flow runtime is responsible for configuring the processor with the input/output connection details and any settings the developer requires.
@CloudEventComponent
public class EchoingProcessor {
Logger logger = Logger.getLogger(DataLogger.class.getName());
@CloudEventProducer(name = "OUTPUT_DATA")
CloudEventProducerTarget target;
@CloudEventConsumer(name = "INPUT_DATA")
public void onCloudEvent(CloudEvent evt){
if(evt.getData().isPresent()){
logger.info(evt.getData().get().toString());
}
target.send(evt);
}
}
The development of custom processors will be covered in depth in Part 3 of this series. Part 3 will also show how to develop processors in other languages.
Design: EventFlow Manager API and UI
Flows are represented internally as k8s Custom Resources. While these can be created via the standard k8s API and we provide Java classes for working with the CRD, this is not very convenient for most developers. To make it easier for developers to create and deploy flows, we have developed an initial web-based UI for creating flows graphically.
Using this tool, developers can select input topics that are already present in Red Hat AMQ Streams and connect them to processors that have been deployed into OpenShift. The Manager UI allows developers to set processor parameters and non-functional settings such as the number of replicas of each processor. It is likely that in the future the current prototype UI will be replaced with other tools that are more consistent and user-friendly.
Deploy: Flow Operator
The Flow Operator is deployed into OpenShift and is responsible for the deployment and configuration of Flows. The operator is notified when new Flow Custom Resources are deployed into the platform or when an existing one is updated. The Operator inspects the Flow CR (Custom Resource) and generates a set of resources (Deployments, ConfigMaps, and KafkaTopics) that can be deployed into OpenShift. In a new Flow deployment, these resources are created in the platform and the flow will begin to process data when it arrives on an input topic. In the case of reconfiguring an existing flow, the Operator will update only the components that have been changed, leaving the unchanged components "as is." Such changes could be increasing the number of replicas of a processor or editing the flow definition to include additional processors.
Connect: Making use of Red Hat AMQ Streams
The EventFlow platform uses Red Hat AMQ Streams as the communication mechanism between microservices. This allows the platform to dynamically create topics as required and has some convenient properties with respect to deployment and reconfiguration.
The deployment of the flow processors may occur in any order dependant on factors such as whether any images are cached locally and the startup overhead for each container. Because Red Hat AMQ Streams will buffer the messages in between processors, we are able to instantiate the flow in any order with confidence that once upstream components have started, the messages will begin to flow.
Second, one of the properties of Apache Kafka that underlies Red Hat AMQ Streams is that it has the potential to store historical messages indefinitely. This feature means that if a new processor is added to a running flow, there is the potential to "replay" old messages through it and all downstream processors. This results in the reconfigured flow behaving as if it had been deployed initially.
Additional resources
Here are some additional Kafka posts that might be helpful:
- Smart-Meter Data Processing Using Apache Kafka on OpenShift
- Introducing the Kafka-CDI Library
- Announcing AMQ Streams: Apache Kafka on OpenShift
Conclusion
This post presented a framework that is capable of processing streams of events using a set of components that are connected using an installation of Apache Kafka provided by the Red Hat AMQ Streams product. This approach to event processing allows developers to create simple components that can be wired together using either a graphical editor or via a flow definition document. This means that complex event-processing pipelines can be created relatively easily and then scaled in response to varying levels of demand or distributed over multiple cloud providers, as required.
The next posts in this series will describe the process of event-flow creation and deployment and also introduce the software development environment that enables developers to create their own processing components and link them together using this framework.
Last updated: March 24, 2023