Topics such as application resiliency, self-healing, antifragility are my area of interest. I've been trying to distinguish, define, and visualize these concepts, and create solutions with these characteristics.

Software characteristics">
However, I notice repeatedly, that there are various conference talks about resiliency, self-healing, and antifragility and often they lazily conclude that Netflix OSS Hystrix is the answer to all of that. It is important to remember that conference speakers are overly optimistic, wishful thinkers, and it takes more than a Circuit Breaker to create a resilient and self-healing application.
Conference level Resiliency
So what does a typical resiliency pitch look like: use timeouts, isolate in bulkheads, and of course apply the circuit breaker pattern. Having implemented the circuit breaker pattern twice in Apache Camel (first a homegrown version, then using Hystrix) I have to admit that circuit breaker is a perfect conference material with nice visualization options and state transitions. (I will spare explaining to you how a circuit breaker works here, I'm sure you will not mind). And typically, such a pitch concludes that the answer to all of the above concerns is Hystrix. Hurrah!
Get out of the Process
I agree with all the suggestions above such as timeout, bulkhead, and circuit breaker. But that is a very narrow sighted view. It is not possible to make an application resilient and self-healing (not to mention antifragile) only from within. For a truly resilient and self-healing architecture, you need also isolation, external monitoring, and autonomous decision-making. What do I mean by that?
If you read Release It carefully, you will realize that bulkhead pattern is not about thread pools. In my Camel Design Patterns book, I've explained that there are multiple levels to isolate and apply the bulkhead pattern. Thread Pools with Hystrix is only the first level.
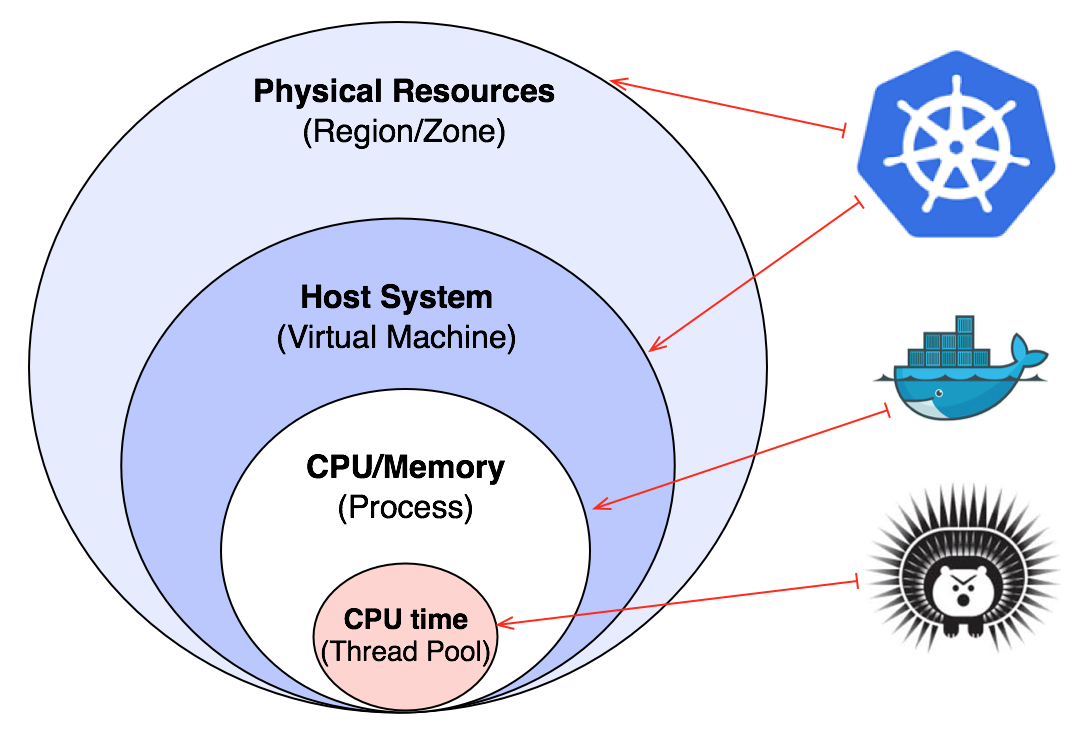
Bulkhead levels and tools">
Hystrix uses thread pools to ensure that the CPU time dedicated to your application process is better distributed among the different threads of the application. This will prevent a CPU intensive failure from spreading beyond a thread pool and other parts of the service still gets some CPU time.
But what about any other kind of failure that can happen in an application that is not contained in a thread pool? What about if there is a memory leak in the application or some sort of infinite loop or a fork bomb? For these kinds of failures, you need to isolate the different instances of your service through process resource isolation. Something that is provided by modern container technologies and used as the standard deployment unit nowadays. In practical term, this means isolating processes on the same host using containers by setting memory and CPU limits.
Once you have isolated the different service instances and ensured failure containment among the different service processes through containers, the next step is to protect from VM/Node/Host failures. In a cloud environment, VMs can come and go even more often, and with that, all process instances on the VM would vanish. That requires distributing the different instances of your service into different VMs and contain VMs failures from bringing down the whole application.
All VMs run on some kind of hardware and it is also important to isolate hardware failures too. If an application is spread across multiple VMs but all of them depend on a shared hardware unit, a failure on the hardware can still affect the whole application.
A container orchestrator such as Kubernetes can spread the service instances on multiple nodes using an anti-affinity feature. Even further, anti-affinity can spread the instances of a service across hardware racks, availability zones, or any other logical grouping of hardware to reduce correlated failures.
Self-Healing from What?
The circuit breaker pattern has characteristics for auto-recovery and self-healing. An open or half-open circuit breaker will periodically let certain requests reach the target endpoint and if these succeed, the circuit breaker will transition to its healthy state.
But a circuit breaker can protect and recover only from failures related to service interactions. To recover from other kinds of failures that we mentioned previously, such as memory leaks, infinite loops, fork bombs or anything else that may prevent a service from functioning as intended, we need some other means of failure detection, containment, and self-healing. This where container health checks come into the picture.
Health checks such as Kubernetes liveness and readiness probes will monitor and detect failures in the services and restart them if required. That is a powerful feature, as it allows polyglot services to be monitored and recovered in a unified way.
Restarting a service will help only to recover from failures. But what about coping with other kinds of behavior such as high load? Kubernetes can scale up and down the services horizontally or even the underlying infrastructure as demonstrated here.

AWS outage handled by Kubernetes">
Health checks and container restarts can help with individual service failures, but what happens if the whole node or rack fails? This is where the Kubernetes schedule kicks in and places the services on other hosts that have enough capacity to run them.
As you can see here, in order to have a system that can self-heal from different kinds of failures, there is a need for a much more resiliency primitives than a circuit breaker. The integrated toolset in Kubernetes in the form of container resource isolation, health checks, graceful termination and start up, container placement, auto scaling, etc do help achieve application resiliency, self-healing and even blend into antifragility.
Let the Platform Handle it
There are many examples of developer and application responsibilities that have shifted from the application into the platform. With Kubernetes some examples are:
- Application health checks and restarts are handled by the platform.
- Application placements are automated and performed by the scheduler.
- The act of updating a service with a newer version is covered by Deployments.
- Service discovery, which was an application level concern, has moved into the platform (through Services).
- Managing Cron jobs have shifted from being an application responsibility to the platform (through Kubernetes CronJobs).
In a similar fashion, the act of performing timeouts, retries, circuit breaking is shifting from the application into the platform. There is a new category of tools referred to as Service Mesh and with the more popular members at this moment being:
- Envoy from Lyft Engineering
- Linkerd from https://buoyant.io
- Traefik from https://containo.us
These tools provide features such as:
- Retry
- Circuit-breaking
- Latency and other metrics
- Failure- and latency-aware load balancing
- Distributed tracing
- Protocol upgrade
- Version-aware routing
- Cluster failover, etc
That means, very soon, we won't need an implementation of the circuit breaker as part of every microservice. Instead, we will be using one as a sidecar pattern or host proxy. In either case, these new tools will shift all of the network-related concerns where they belong: from L7 to L4/5.

Image from Christian Posta">
When we talk about Microservices at scale, which is the only possible way to manage complexity: automation and delegation to the platform. My colleague and friend @christianposta has blogged about Service Mesh in depth here.
A Resiliency Toolkit
Without scaring you death, below is a collection of practices and patterns for achieving a resilient architecture by Uwe Friedrichsen.

Resiliency patterns by Uwe Friedrichsen">
Do not try to use all of them, and do not try to use Hystrix all the time. Consider which of these patterns will apply to your application and use them cautiously, only when a pattern benefit outweighs its cost.
At the next conference, when somebody tries to sell you a circuit breaker talk, tell them that this is only the starter and ask for the main course.

About the author:
Bilgin Ibryam is a member of Apache Software Foundation, integration architect at Red Hat, a software craftsman, and blogger. He is an open source fanatic, passionate about distributed systems, messaging and application integration. He is the author of Camel Design Patterns & Kubernetes Patterns books. Follow @bibryam for future blog posts on related topics.
Download this Kubernetes cheat sheet for automating deployment, scaling and operations of application containers across clusters of hosts, providing container-centric infrastructure.
