Objective
Some days ago, I was having an argument with a few Java developers about Node.js, they asked questions like “why should I use that?” or “what’s the benefit?”, I told them by memory that Node.js is an event driven I/O, and thanks to that you will end up writing very efficient server-side applications. They come back saying that they can get the same effect using threads.
Thing is I wasn't fully prepared to explain the difference, I had a notion of what the epoll system call in GNU/Linux is, but I didn’t have a full map in my mind. The goal of this document is to explain how Node.js Event Driven works and why this paradigm and non-blocking I/O is so important if you want to make a efficient use of your resources (Disk, Network, etc).
Anatomy of a browser request
When you are in your browser and you navigate to a site, your browser open a transaction sending a message to the server asking for some resource usually an html file, and the server execute some business logic and then respond sending this page back to the client.
To make this happen using your favorite language you need a operative system with Socket API support in POSIX compliant OS or Winsock if you run in Windows, your server code no matter in what language will end up making system calls through this library.
Blocking I/O
You may had heard that almost everything in Unix is a file ( I/O stream), this apply to sockets as well, when you create one socket you get back an file descriptor representing an I/O capable resource.
The system call to do the handshake with the browser/client is called accept this call blocks by default, this means that your program will wait for data to come in, while your are waiting your program will be unable to handle business logic.
This code below can only handle one client at time, and thats sad.

Multi-threading
Your user base is growing and now you have a problem because your server is not fast enough due to the blocking nature of your implementation, so a common technique is to spawn a new thread or process to handle the I/O for each client.
This is fantastic but lets examine some pitfalls:
- The Linux kernel reserve 2 MB RAM per thread by default, this means that your memory grows linearly in proportion of sockets opened, without counting that each of them replicate the business logic cost in RAM, so consider that 2MB is the minimum per thread.
- Need to deal with Thread-safety problems (see deadlock risks), racing conditions, sharing resources, mutex (is a form of blocking but with threads).
- Degrading CPU cache locality, when you are looking to max out the value of your CPU this should be a concern.
- The time it takes to switch between worker threads (context switching)
- Worker threads are I/O bound
- The number of threads an OS can create per process.
The thread exhaustion can be somewhat mitigated using Thread pools, a lot of enterprise grade Java web application use this technique, this technique is not as efficient as an non-blocking solution as we going to see in a moment.
This a naive implementation of a multi-thread http-server:

This picture shows how a thread pool works, and its limitations.

Non-Blocking I/O
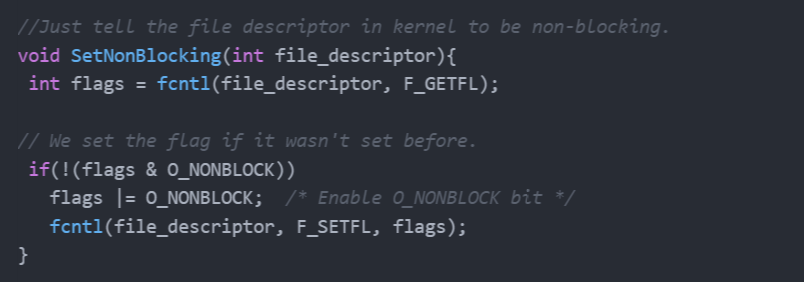
This is a Kernel level feature that allows us to set a flag that tells the system to return I/O operations (read, write, close,...) immediately even if data is not ready, this has a nice side effect, the caller thread never blocks, but it require us to change the way we code because we can’t rely in the blocking nature of the accept anymore.
Evented I/O
We want to know when data is ready, we can check the data readiness asking accept each cycle of the loop but that's sounds bad, The Linux kernel gives us a more elegant way to deal with this dilemma. Since Kernel 2.5.44 we have an epoll API that allows us to monitor multiple file descriptors to see if they are ready for I/O.
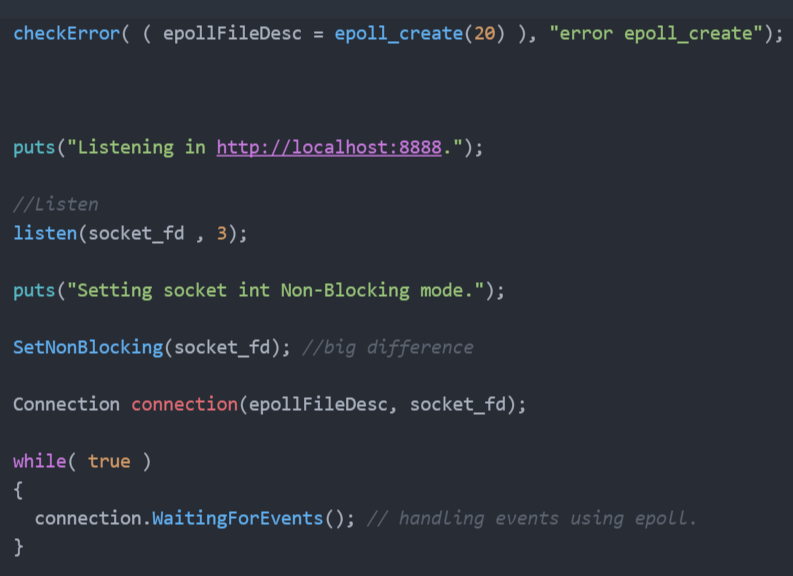
Non-Blocking I/O + Event Driven
Merging this two functionality allow us to overlap business operations with I/O, and doing it well give us low resources starvation. Other advantages include:
- Efficiently lets the kernel manage context switching and I/O readiness.
- Epoll API scale well monitoring large set of file descriptor, in other words you can handle more request at the same time.
- Monitoring only cost 90 byte (160 bytes in 64bits systems), as per epoll documentation.
- Efficiently overlap I/O with other tasks like business logic, etc.
Non-Blocking I/O + Epoll (Event Driven) + V8 Engine = Node.js
So Javascript was created with user interface in mind, one of the language features is function first class citizen that allows you to pass functions as parameters, so basically you can monitor for events (user interaction) and pass a function to handle this events.
In the other hand handling I/O events with epoll can be a little bit complicate (handling calls with state for example), this require your server app to be react accordingly to all possible events emitted by the file descriptor, this is one of the many good excuse to use Javascript, the result is Node.js that glue v8 and LibUV (event I/O support across OS) to create a very good framework to develop critical I/O server applications.
Conclusion
We have described different way to handle I/O bound scalability showing various techniques used to solve this problems, as we can observe Node.js take advantage of the most efficient of those techniques and this maybe explain the excitement in the community and fast adoption of this platform to handle big concurrency problems.
I left example code for testing the 3 ways to handle Socket I/O here, they are simple implementations just to showcase the different I/O approach.
References:
I/O Multiplexing & Scalable Socket Servers
http://www.drdobbs.com/open-source/io-multiplexing-scalable-socket-servers/184405553
The Linux Programming Interface: http://man7.org/tlpi/
http://people.eecs.berkeley.edu/~sangjin/2012/12/21/epoll-vs-kqueue.html
Last updated: October 31, 2023