One of my favourite books is Antifragile by Nassim Taleb where the author talks about things that gain from disorder. Nacim introduces the concept of antifragility which is similar to hormesis in biology or creative destruction in economics and analyses it charecteristics in great details. If you find this topic interesting, there are also other authors who have examined the same phenomenon in different industries such as Gary Hamel, C. S. Holling, Jan Husdal. The concept of antifragile is the opposite of the fragile. A fragile thing such as a package of wine glasses is easily broken when dropped but an antifragile object would benefit from such stress. So rather than marking such a box with "Handle with Care", it would be labelled "Please Mishandle" and the wine would get better with each drop (would be awesome woulnd't it).

It didn't take long for the concept of antifragility to be used also for describing some of the software development principles and architectural styles. Some would say that SOLID prinsiples are antifragile, some would say that microservices are antifragile, and some would say software systems cannot be antifragile ever. This article is my take on the subject.
According to Taleb, fragility, robustness, resilience and antifragility are all very different. Fragility involves loss and penalisation from disorder. Robustness is enduring to stress with no harm nor gain. Resilience involves adapting to stress and staying the same. And antifragility involves gain and benefit from disorder. If we try to relate these concepts and their characteristics to software systems, one way to define them would be as the following.
Disorder
Different systems are affected by different kind of disorder, such as stress, time, change, volatility, debt, etc. For software systems, the main disorder is the change. The business is in a constant changing environment and the software needs to adapt to the business needs quickly. That is implementing new requirements, changes to existing functionality, even creating new business opportunities through innovation. A software system has to change all the time, otherwise it is obsolete.
Apart from development time challenges, there are also runtime challenges for software systems too. Software systems are created and exists to add value by running in a production environment. And while doing so, they are under stress by end users and other systems. This is another kind of disorder, that software systems have to deal with.
Fragile
This property describes systems that suffer when put under stress. Imagine a software project that is not easy to change at development time. For example if it is not easy to extend, modify and deploy to the production environment. Or a system that is not able to handle unexpected user inputs or external system failures and breaks easily. That's is a fragile system that is harmed by stress and penalised by change, a good example of fragile.
Robust
This is a system that can continue functioning in the presence of internal and external challenges without adaptation. Every system is robust up to a level. For example a bottle is robust until it reaches the level of breaking point. A software system can be made robust to handle unanticipated user input, or failures in external systems. For example handling NullPointerException in Java, using try-catch-finally statements to handle unreliable invocations, having a thread pool to handle concurrent users, creating network connections using timeouts, are all examples of robustness for a software system. But a robust system doesn't adapt to a chaining environment and when the stress and change threshold is reached it would break. The qualities that define the robustness vary from system to system. An ATM for example needs to be robust and not fail in the middle of a transaction, whereas, a media streaming service can drop a frame or two, as long as it continues streaming under stress.
Resilient
A system is resilient when it can adapt to internal and external challenges by changing its method of operation. The key here is that the system is responding to stress by changing its internal behaviour rather than resisting stress with a predefined buffer.
- A typical example here is the circuit breaker pattern which changes its internal state to adapt to the external system behaviour to protect itself.
- Another example would be using a retry mechanism with some backoff algorithm to handle transient failures in external systems.
- A different technique for creating resilient systems is through graceful degradation, both on the UI and the server side. Rendering UI based on the user agent capabilities, or failing fast on the server side and fallback to some default values are commonly used techniques to adapt to failures.
- Systems with self healing and autorepair capabilities are another example of resiliency. These systems are self-aware and can detect abnormalities and take corrective actions. For example Kubernetes/OpenShift will perform regular liveness checks for the running Docker containers and if they detect any anomalies they will restart the container and perform necessary backoffs until the application stabilises. This is another mechanism to cope with stress and improve application resilience.
Before looking at the next level of software evolution - the antifragile systems, let's visualise and summarise different kind of software system characteristics.
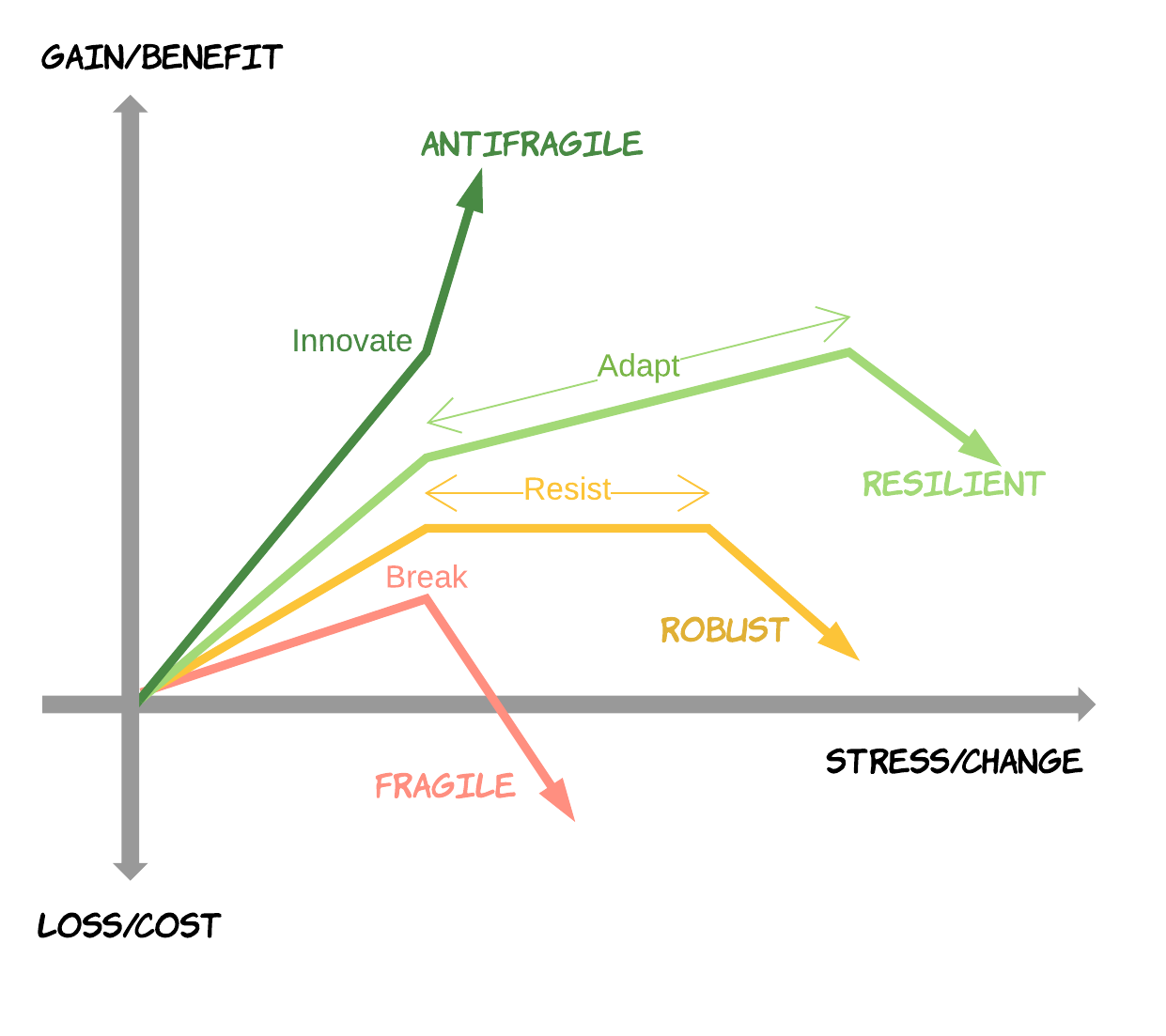
- A fragile system is difficult to modify, and cannot cope with a changing environment. Even if it provides some value when used in a stable non changing environment, when faced with further stress and change, it quickly turns into a liability. Many organisations have applications (mainframes for example) which are impossible to change, very expensive to maintain, but still running on high cost as they are very critical to the business.
- A robust system is the one that is implemented with certain buffers to handle change and stress. So when the stress level increases, it can withstand it for up to a level without losing its capabilities and still provide a good value. But a robust system does not adapt, and if the stress and change levels continue raising, such a system can also stops providing benefit and may turn into liability and run on loss.
- A resilient system can handle more stress and change as it is designed and implemented with stress in mind and adaptability features. Even if it is not benefiting from stress, it can survive lot's of different kind of stress and change and provide value up to a greater degree.
- An antifragile system is created with change in mind and it feeds from stress and change. It is much harder to create such a system (it is not a software system but a social-technical system) but once it is in place, it drives the business based on change, and even creates the change.
Antifragile
Many things in life are antifragile, such as the human body. When stressed at the right level, a muscle or bone wold come back stronger. But can a software system be antifragile? Certainly there are some tools, platforms, architectural styles, methodologies that can help create software with antifragile characteristics. Let's see some of the more popular ones.
Auto scaling feature allows applications to handle increasing load by creating more instances of the application. To achieve that, the software system have to able to measure and then react to change and stress. Some good examples here are AWS autoscaling of EC2 instances at infrastructure level, and OpenShift autoscaling of application containers for the application level. This is a feature that transitions applications from resiliency to antifragility since the software system is shifting resources from one part of the system into another to respond to stress.
Microservices. According to Taleb, at times of stress, the large is doomed to breaking. And that phenomen has been observed with mammals, corporations, administrations, etc. In software and large projects, this behaviour has been observed even more often. The bigger a software project is, the harder it becomes to change and react to stress. Microservices is an architecture styles that allows easier change by having autonomous services with well defined APIs - features that allow change. Russ Miles is a strong believer and proponent of Antifragile Software through Microservices (here is an intro video from him).
Chaos engineering is a technique to create antifragility by evolving systems to survive chaos. Rather than waiting for things to break at the worst possible time, the idea of chaos engineering is to proactively inject failures in order to be prepared when disaster strikes. Netflix’s Simian Army is a very good materialization of this technique, designed to generate failures and help isolate system’s weaknesses.
Continuous deployments to a production environment creates continuous partial system failures and forces organisations to react better to failures through redundancy, rolling upgrades, rollbacks, and avoiding single points of failure. Other techniques such as canary release, blue-green deployments, are used to reduce the risk of introducing new software into production environment. Some other methods such as A/B testing even allows experimenting with change and measuring its effect, in order to gain from change.
The human element
Antifragility is not an universal characteristics. Different systems are antigragile towards different kind of disorder. For example Chaos Monkey will make your system antifragile towards EC2 deaths, and autoscaller will make your system respond to specific type of load. But your systems will not be antifragile towards other kinds of stress. And if you look above at the different ways of introdusing antifragility into software systems, all of them are means for making the social-technical system antifragile (and not only the software system):
- Chaos engineering forces human feedback to the injected randomness and makes the system antifragile.
- Microservices alone do not make a software system antifragile. But microservices combined with appropriate organisational and team structure enables antifragility. If microservices are a way for architecting applications into autonomous structures, DevOps is a means for organizing teams into similar structures. You need both in order to benefit from them and gain from disorder.
- Continuous deployment pipeline is a tool that allows teams to react to stress faster, introduce or retract change faster and generally use the stress as the driver.
- Similarly, iterative development is not enough to benefit from changing environment. But iterative development with open and honest retrospective rituals is.
Innovate
If it takes few weeks to create a new developer environment, you can not react to change. If it takes three months to release a new feature, you can not react to change. If your ops team is watching the metrics dashboard and manually scaling applications up and down, you cannot embrace change. If the team is hardly catching up with the change, there is no way to gain from change. But once you put an appropriate organizational structure, the right tools and culture in place, then you can start gaining from change. Then you can afford having Friday Hackathons, then you can start exploring open source projects and start contributing to them, then you can start open sourcing your internal projects and benefit from a community, and generally be the change itself. And why not the Netflix or the Amazon of tomorrow.

About the author:
Bilgin Ibryam is an Apache Camel committer, integration architect at Red Hat, a software craftsman and blogger. He is an open source fanatic, passionate about distributed systems, messaging and application integration. He is the author of Camel Design Patterns & Instant Apache Camel Message Routing books.
