If you've spent time deploying traditional large language models (LLMs), you've likely wrestled with the classic tradeoff between accuracy and performance. Typically, we're forced to make a rigid architectural choice: Do you deploy a massive, slow model for deep reasoning, or a small, lightning-fast one for everyday chat? Often, we end up gluing these models together with complex semantic routers. What if we didn't have to choose? Diffusion LLMs offer a way out of this trap, alongside a host of other potential benefits.
Why the shift and how it works
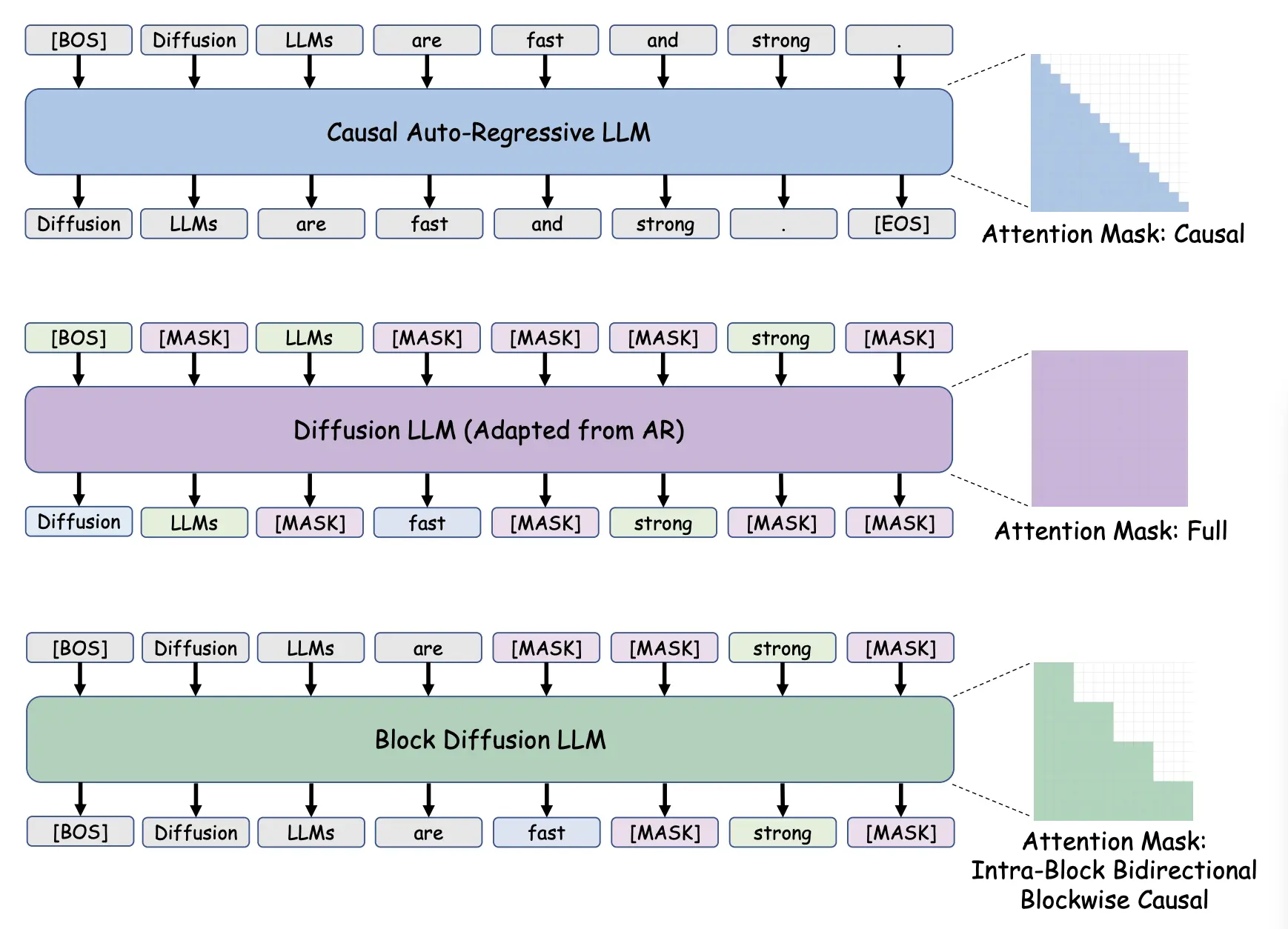
Traditional auto-regressive (AR) models use causal next token prediction. They predict the next token one by one, moving strictly from left to right. It works, but it's rigid.
A diffusion LLM (dLLM) flips the script, offering a refreshing, dynamic alternative. Instead of guessing one word at a time, a dLLM drafts a sequence of text and then refines it, using two techniques:
- Bidirectional attention: Unlike AR models that can only look at the past, a dLLM looks at both the past and the future tokens it is drafting. This creates incredibly coherent, context-aware output.
- Iterative refinement: Think of it like a game of fill-in-the-blank. Instead of writing a sentence word-by-word, the model drafts a full sentence with blanks—like "The quick [MASK] fox jumps over the [MASK] dog." In the next step, it looks at the whole sentence to perfectly fill in "brown" and "lazy." It loops back to enhance the quality and logic of the draft with each pass.
Figure 1 shows the progression from a standard causal mask of auto-regressive models to the full bidirectional mask of early diffusion LLMs.
The runtime tradeoff
So why is this architecture so different? The magic is a beautifully simple, dynamic runtime tradeoff. With standard AR models, the compute spent on a token is baked into the architecture. If you want more intelligence, you need a bigger model or complex, latency-heavy test-time compute loops.
A dLLM fundamentally rewrites these rules. Because a dLLM drafts multiple tokens simultaneously and refines them over multiple "steps" (similar to how an AI image slowly comes into focus), you can tune quality against latency on the fly.
Need instant, real-time speed for a voice assistant? Run the exact same model at fewer steps.
Need deep, complex reasoning for a coding task? Turn the steps up to let the model refine its draft.
There's no need to swap models, maintain multiple endpoints, or build complex routing logic. You deploy one single model and flex its performance to meet the exact needs of the moment. It's elegant, efficient, and incredibly powerful.
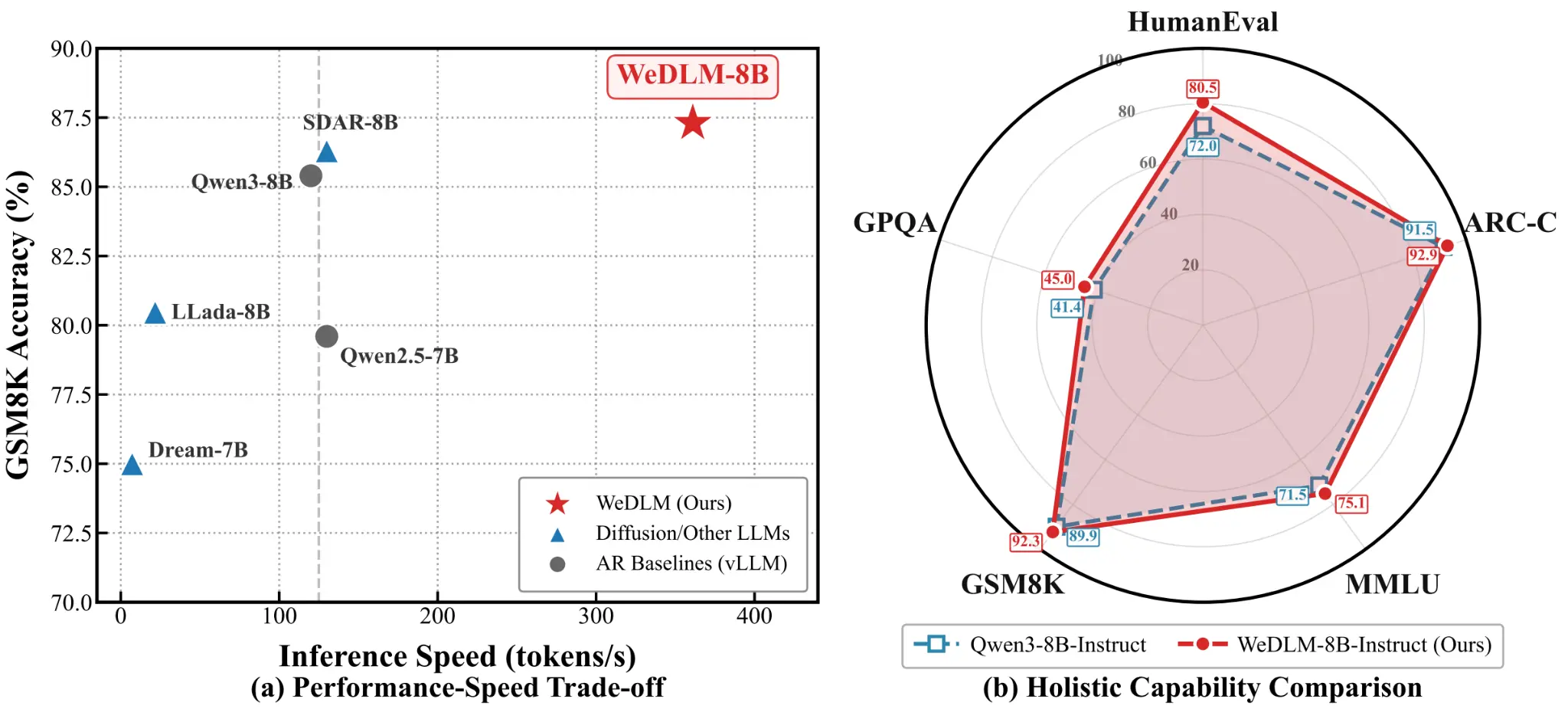
Figure 2 shows some example real-world statistics for a dLLM.
The evolution of diffusion LLMs
This architecture is rapidly evolving across three distinct generations:
- First generation (the pioneers): Early models like LLaDA 1.0, and Dream used a full context approach. They were groundbreaking, but because they tried to refine the entire sequence at once and could not use standard KV caching, they were computationally heavy and slow.
- Second generation (the pragmatists): Models like SDAR, LLaDA 2.0, and Fast-dLLM2 got smarter by shifting to a blocked causal context. By operating on smaller chunks (typically 8 to 64 tokens at a time) and enabling block-wise KV caching, they drastically improved inference speed and made dLLMs practical for real-world use.
- Third generation (the frontier): New models and innovations are popping up every day. LLaDA 2.1 with token editing, and WeDLM with stream decoding, just to name two. That's just the beginning for this self-reinventing third generation.
The need for speed and scale
The demand is undeniable, and the open source community is moving fast. Popular models like LLaDA2.0-mini, LLaDA2.1-flash, Fast_dLLM_v2_1-1.5B, and SDAR-1.7B are experiencing a surge in downloads on Hugging Face, with some reaching 150,000 monthly downloads.
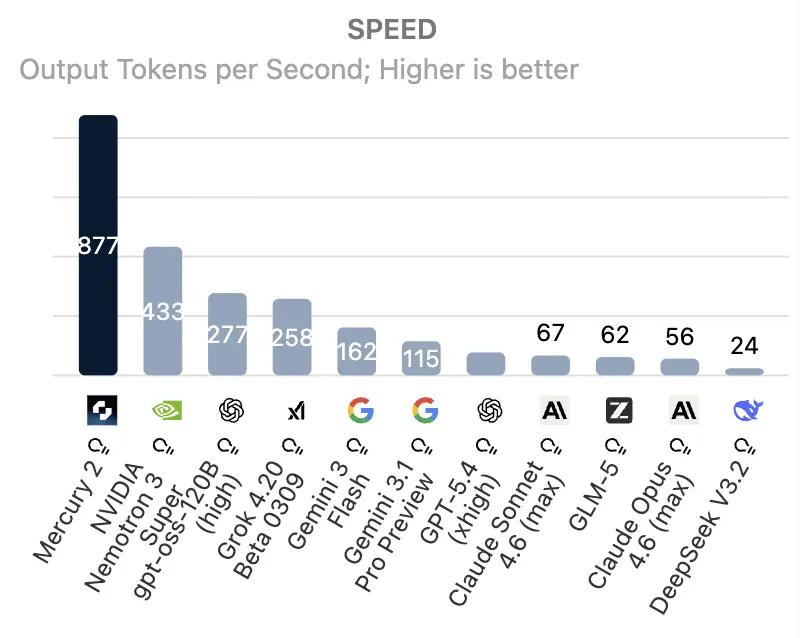
We're seeing trending dLLMs like the open source LLaDA 2.X hitting over 800 output tokens per second (TPS), while the Mercury 2 is crossing the 1000+ TPS threshold. When looking at the data, models like WeDLM and LLaDA 2.1 are outperforming baseline vLLM auto-regressive models, as shown in Figure 3.
Building the future at Red Hat
At Red Hat, we believe in taking brave leaps forward along with the rest of the open source community. We aren't just watching this dLLM trend happen, we're actively exploring this promising architecture to build the infrastructure that supports it. The journey into diffusion LLMs is just beginning, and it's full of brilliant possibilities. Stay tuned for more updates, and as always, keep building with curiosity!
You can also leverage the no-cost 60-day Red Hat AI trial to test leading and emerging models and experience the benefits they can unlock for your unique business use cases.