An introduction to microservices through a complete example
Today I want to talk about the demo we presented @ OpenShift Container Platform Roadshow in Milan & Rome last week.
The demo was based on JBoss team's great work available on this repo:
https://github.com/jbossdemocentral/coolstore-microservice
In the next few paragraphs, I'll describe in deep detail the microservices CoolStore example and how we used it for creating a great and useful example of DevOps practices.
We made some edits to the original project to simplify all the concepts during the demo. (We just edited some usernames and timeout.) You can browse our repo on the next link, anyway keep an eye on the original repo too: https://github.com/alezzandro/coolstore-microservice
PLEASE NOTE: we used "stable-ocp-3.5" branch, so please refer to this when looking at the repo.
The whole CoolStore project has been set up in an OpenShift environment using the script available in the repository at:
openshift/scripts/provision-demo.sh
There is also some documentation available for the script here:
The CoolStore project: a microservices example
CoolStore is a containerized polyglot microservices application consisting of services based on JBoss Middleware, NodeJS, Spring, Netflix OSS and more running on OpenShift.
It demonstrates how to wire up small microservices into a larger application using microservice architectural principles.
Services
Several individual microservices and infrastructure components make up this app:
- Catalog Service - Java application running on JBoss Web Server (Tomcat) and MongoDB, serves products and prices for retail products.
- Cart Service - Native Java application, manages shopping cart for each customer.
- Inventory Service - Java EE application running on JBoss EAP 7 and PostgreSQL, serves inventory and availability data for retail products.
- Coolstore Gateway - Java EE + Spring Boot + Camel application running on JBoss EAP 7, serving as an entry point/router/aggregator to the backend services.
- Web UI - A frontend based on AngularJS and PatternFly running in a Node.js container.
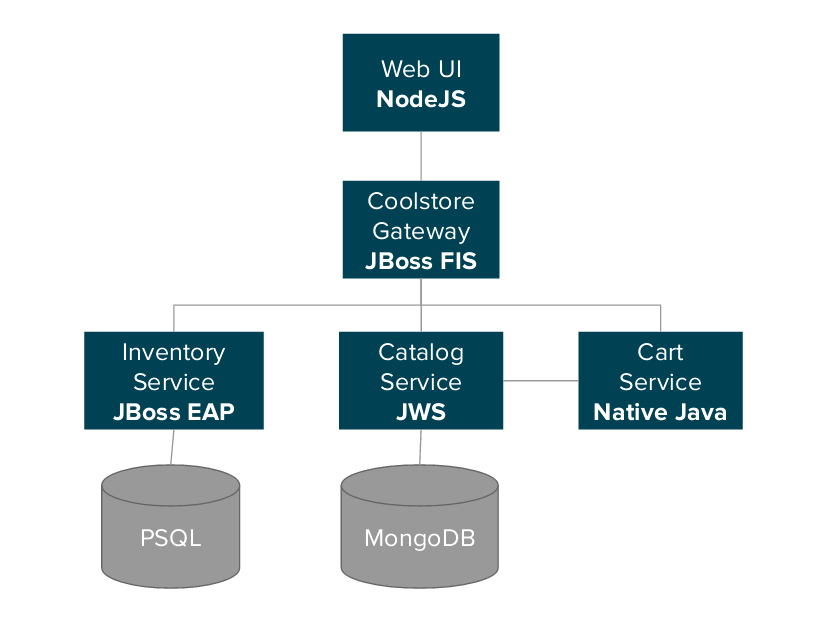
This is an example demo showing a retail store consisting of several of microservices based on JBoss EAP 7 and Node.js, deployed to OpenShift.
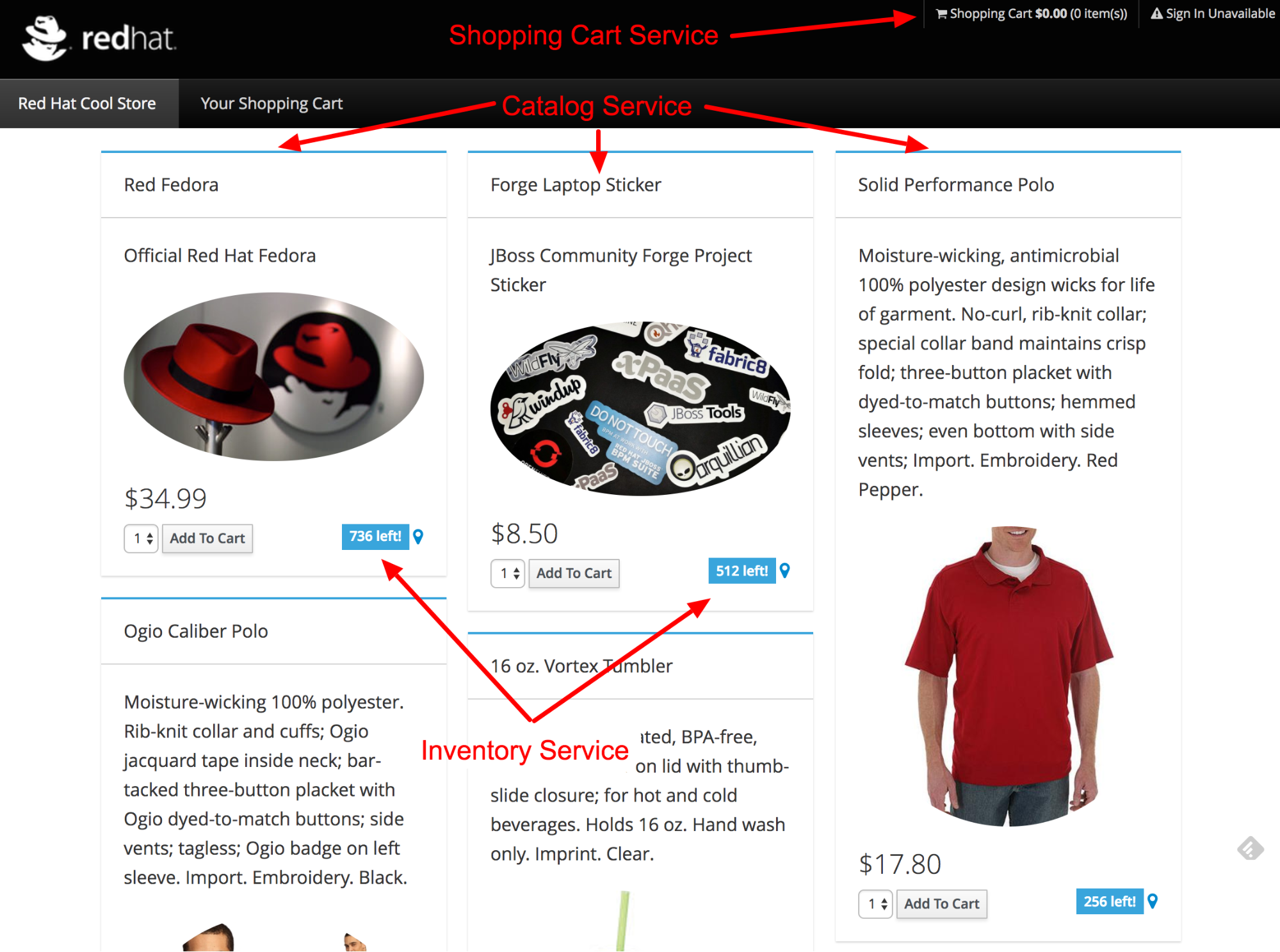
You'll find below a screenshot of the web-ui for the online shop:
OpenShift Setup for CoolStore
An existing OpenShift 3.5 installation has been used for hosting the whole demo with two users pre-configured:
- operation: an OpenShift's user that will be used as operation team that will administrate the operational side of the application.
- developer: an OpenShift's user that will be used as developer team that will handle development of one of the many microservices involved in the application.
You'll see below a screenshot of the OpenShift web interface while using 'operation' user:
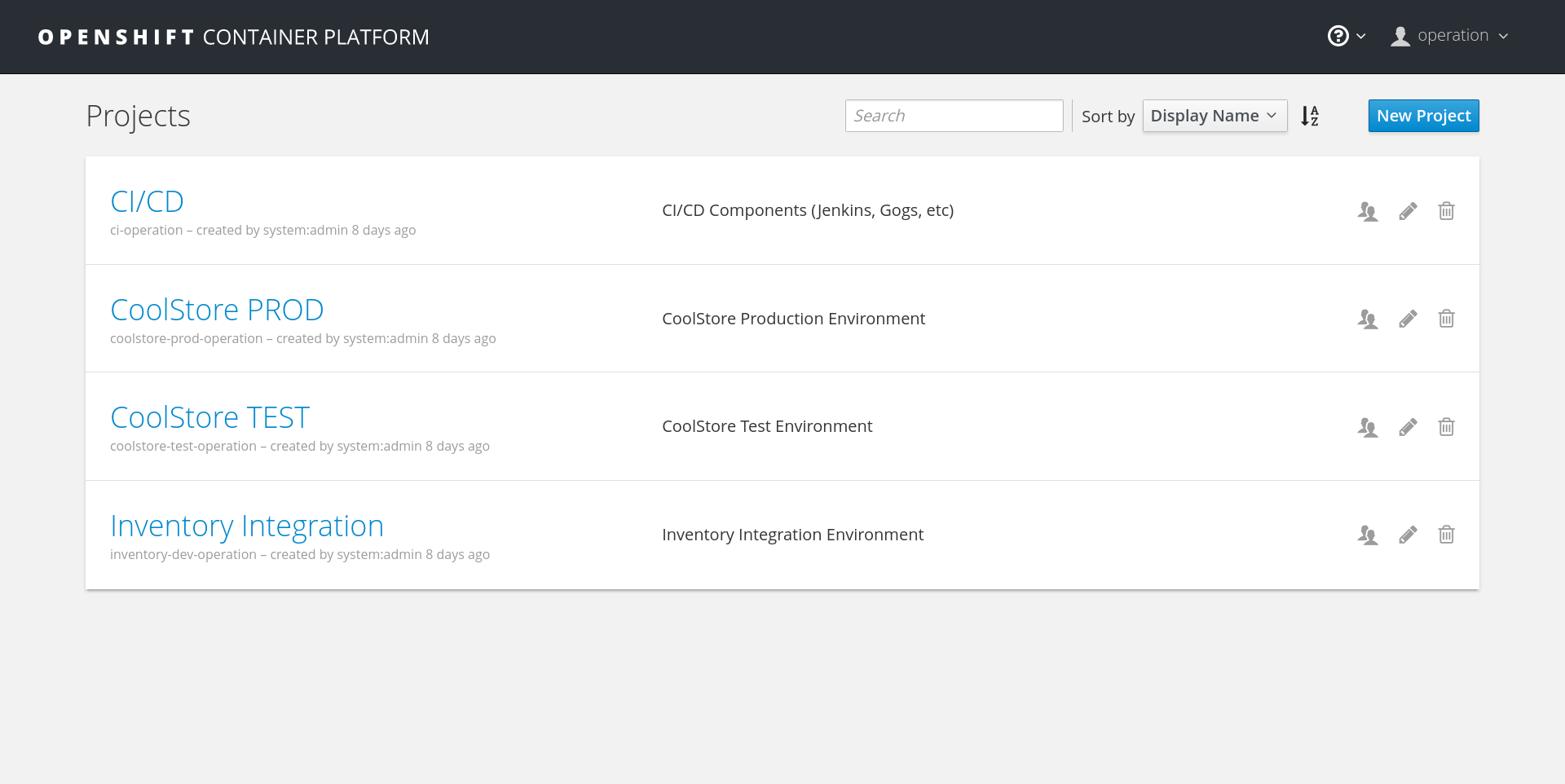
As you can see, we have four projects set up in OpenShift:
- CI/CD: Project that will hold various services for CI/CD purposes -> git, Jenkins, Maven repo (Nexus).
- CoolStore PROD: Project that will hold the application's production environment.
- CoolStore TEST: Project that will hold the application's testing environment.
- Inventory Integration: Project that will hold the integration tests environment for Inventory microservice.
Let's demo
First, of all, we introduced to the audience the "CoolStore TEST" project with all the running pods for every microservice defined previously in the architecture. It was an opportunity to walk through the various OpenShift's entities involved in the project: Pod, DeploymentConfig, Service, and Route.
Then we introduced the "CI/CD" project with the running services:
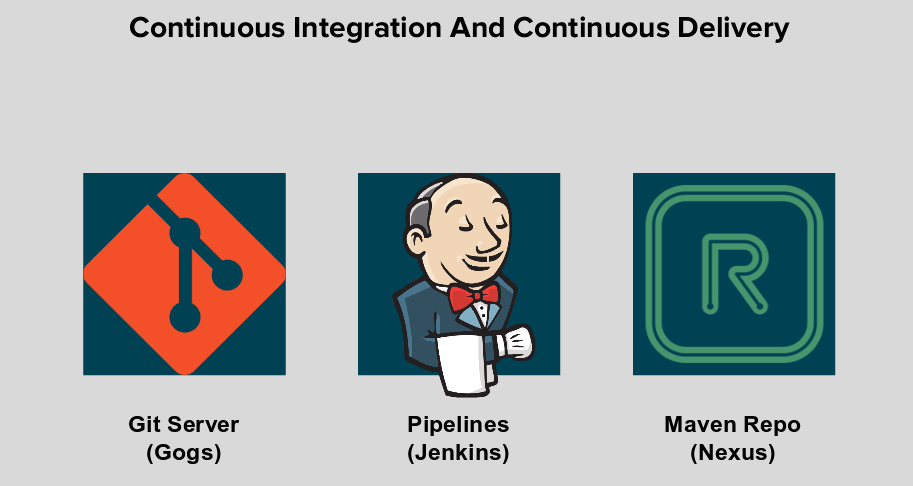
Then we started browsing the running Gogs service GUI and the manager's repo: "coolstore-microservice".
On the Gogs' side, we have two pre-configured users:
- manager: the user that will hold the main code repository. This user will be responsible for the code that will be run in production environment. See it as a development manager, or code reviewer.
- developer: the user that will hold his own copy of code repository. This user will be responsible for patching/fixing the code and requesting, "pull request" vs. the team's repo, about the changes.
Next step of the demo, was about the process of forking the repo, clone it, commit a fix, then create a pull request, as describe in the following schema.
PLEASE NOTE: We've demonstrated the patch/commit/pull request _ONLY_ for the Inventory microservice.
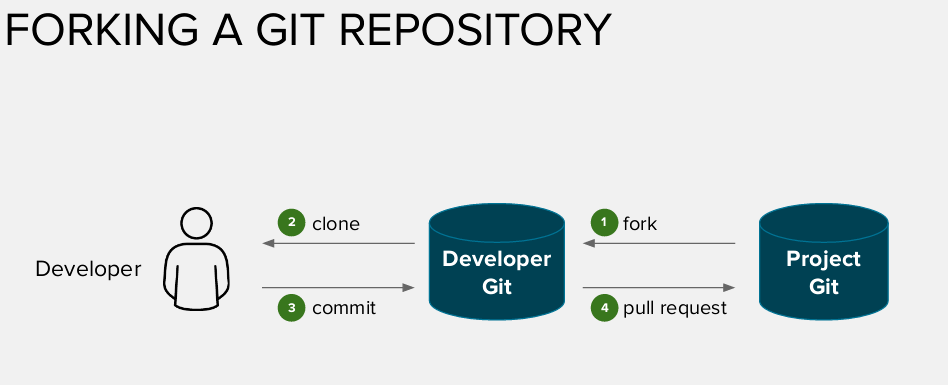
During the demo, we also demonstrated that developer user connected to OpenShift and created a new project for hosting the build/tests for his upcoming fix.
We also demonstrated, just before the "commit phase" how to create a "webhook" for the Inventory BuildConfig that started automatically the local developer's build once upon the commit (this step, of course, is optional, as one may want to manually trigger the build of the code).
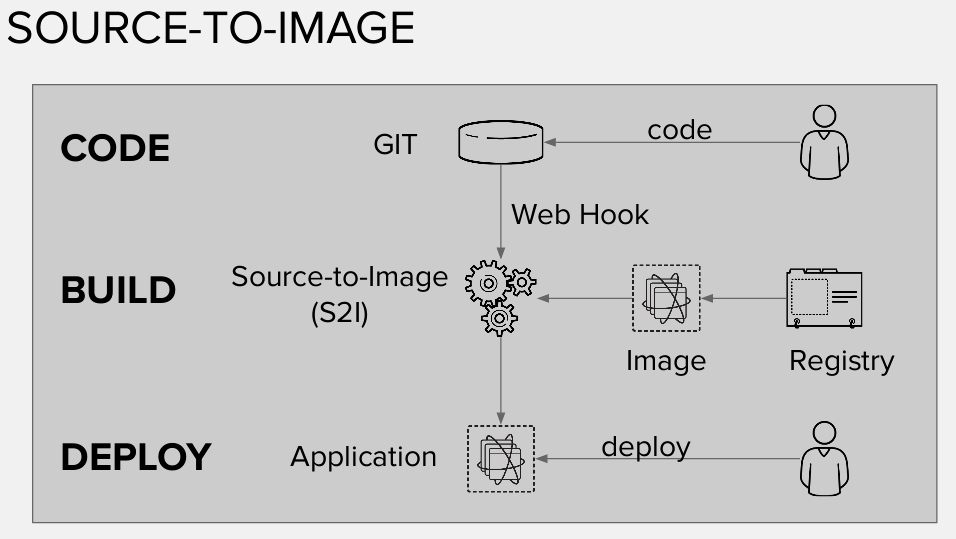
We've introduced the concept of Source to Image (s2i) and how it works under the hood in OpenShift, helping the developer in the code build process.
Before the pull request, we also checked that the fix we applied is actually working through the integrated swagger interface for the Inventory microservice.
We finally logged in the git server as "manager" user for approving the incoming developer's pull request.
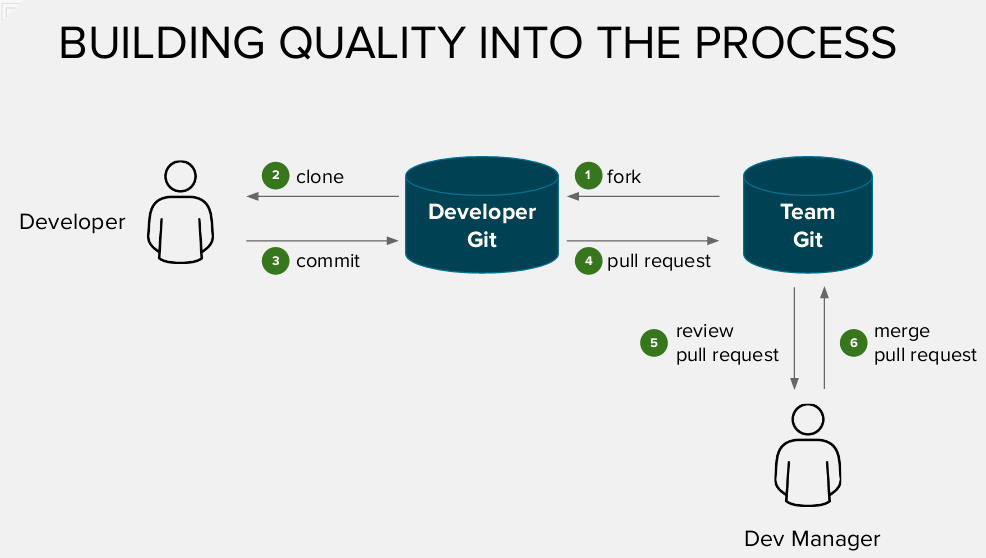
Jenkins' pipelines, now.
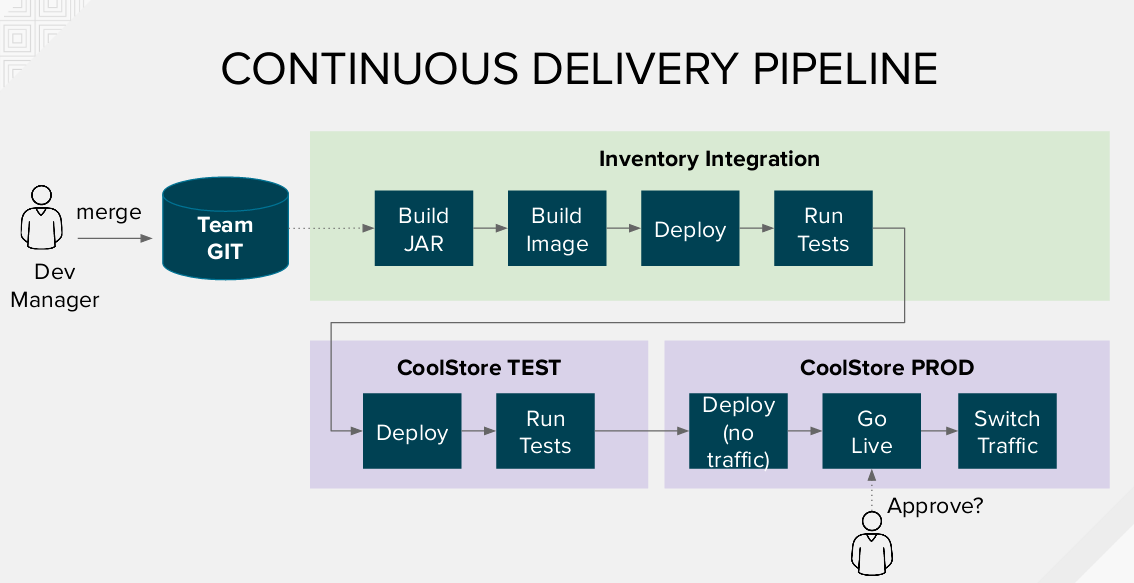
Back on OpenShift, we've introduced then the Pipeline's concepts, its usage and how the inventory pipeline will work for moving the applied fix in production using the better and safer way.
The Inventory-Pipeline will:
- Take the team's code repository and start a new Build in the Inventory-Integration project that was set up by the "operation" user.
- Deploy and run tests on "Inventory-Integration" project. This step overlaps a bit, with what we did in the “developer” self-service environment. However, one should notice that in theory, you can have multiple fixes/features coming from many developers (each working in his environment), and the integration environment is used to test that everything plays nicely together.
- Promote the container image (that we just built), in the project "CoolStore TEST" and run tests on it.
- Deploy the container image in the "CoolStore PROD", without switching live production traffic (OCP Route) to it (e.g. a “silent” prod deploy).
- Wait for "Go Live".
- Switch traffic on the new running container, by moving the production route to the service pointing to the latest version of the service.
As you can see, we've set up two versions of the running Inventory container following the principles of the Blue/Green Deployment Model. Using this deployment model one version of our application is running live and the other it's idle ready to be switched on, in the case of new deployments. The advantages include zero downtime, testing your software in a real environment, and potentially rolling back easily to a previous version, if necessary.
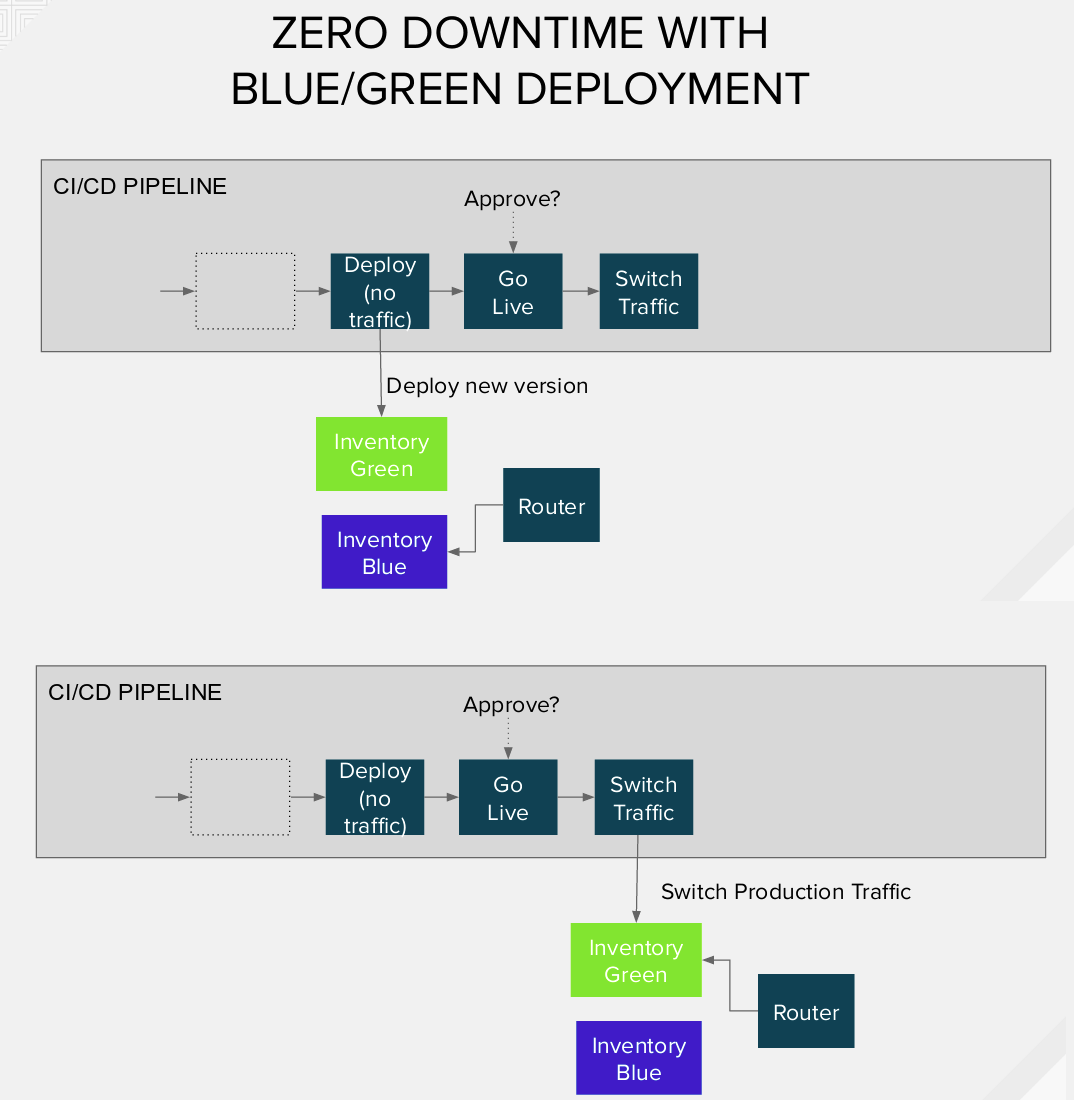
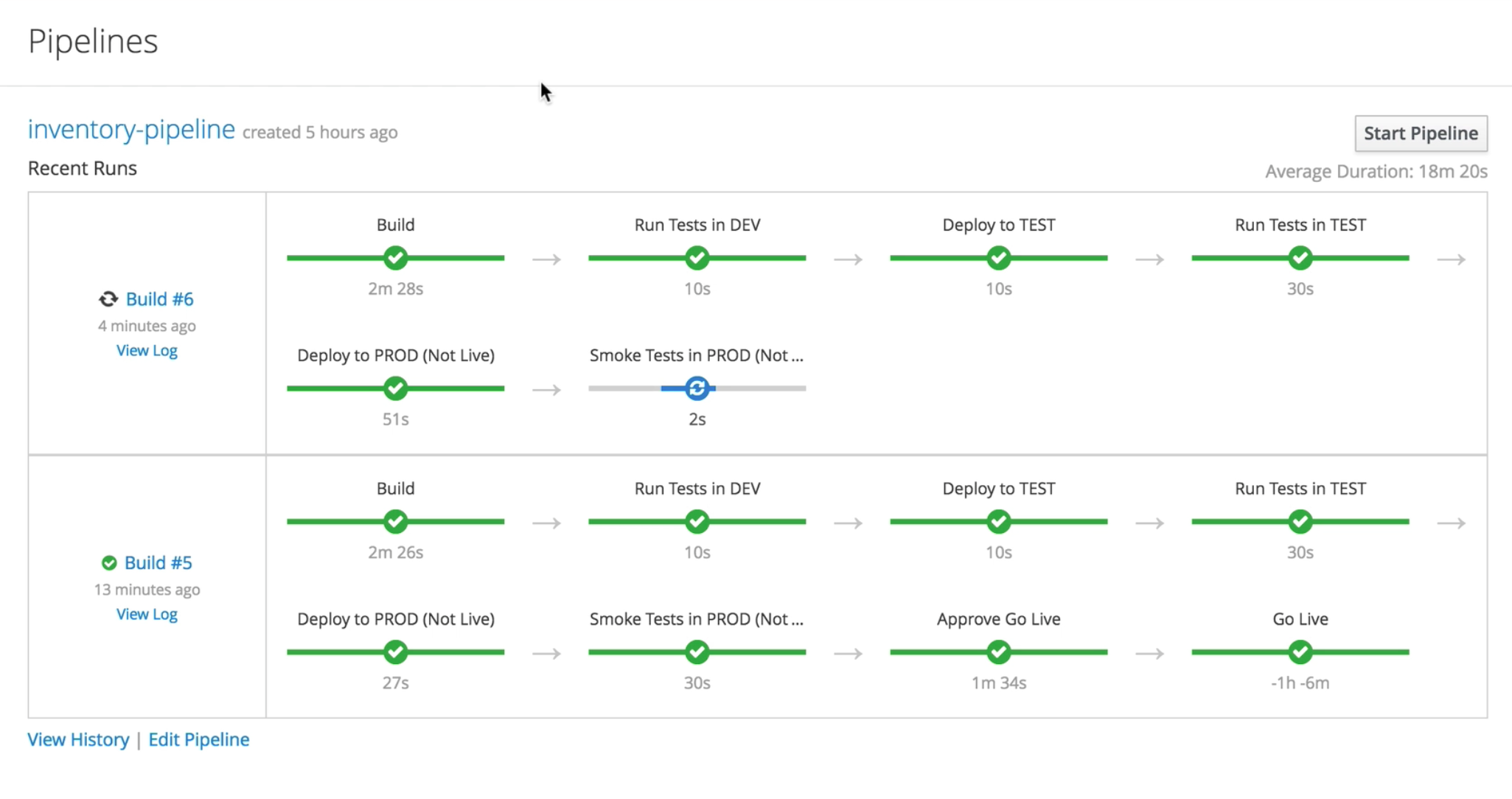
In order to complete the process, we ran the "inventory-pipeline", then tested the "Inventory-Green" just deployed in prod (as idle) through a temporary route. Finally, we approved the Go-Live, by clicking on the manual input step required by the jenkins pipeline.
Defend your application using: the Circuit Breaker
The last demonstration was on the Circuit Breaker features provided by JBoss Fuse Integration Service (FIS) and Netflix OSS Hystrix library.
In the production project, indeed, we also deployed two containers of the Netflix OSS project:
- Turbine: a tool for aggregating streams of Server-Sent Event (SSE).
- Hystrix: a dashboard that will connect to a running instance of Turbine server, displaying aggregated data coming from Hystrix circuit breaker deployed inside our services.
You'll find below a snippet of code showing how this library (hystrix) can be used in a Camel route (on JBoss FIS).

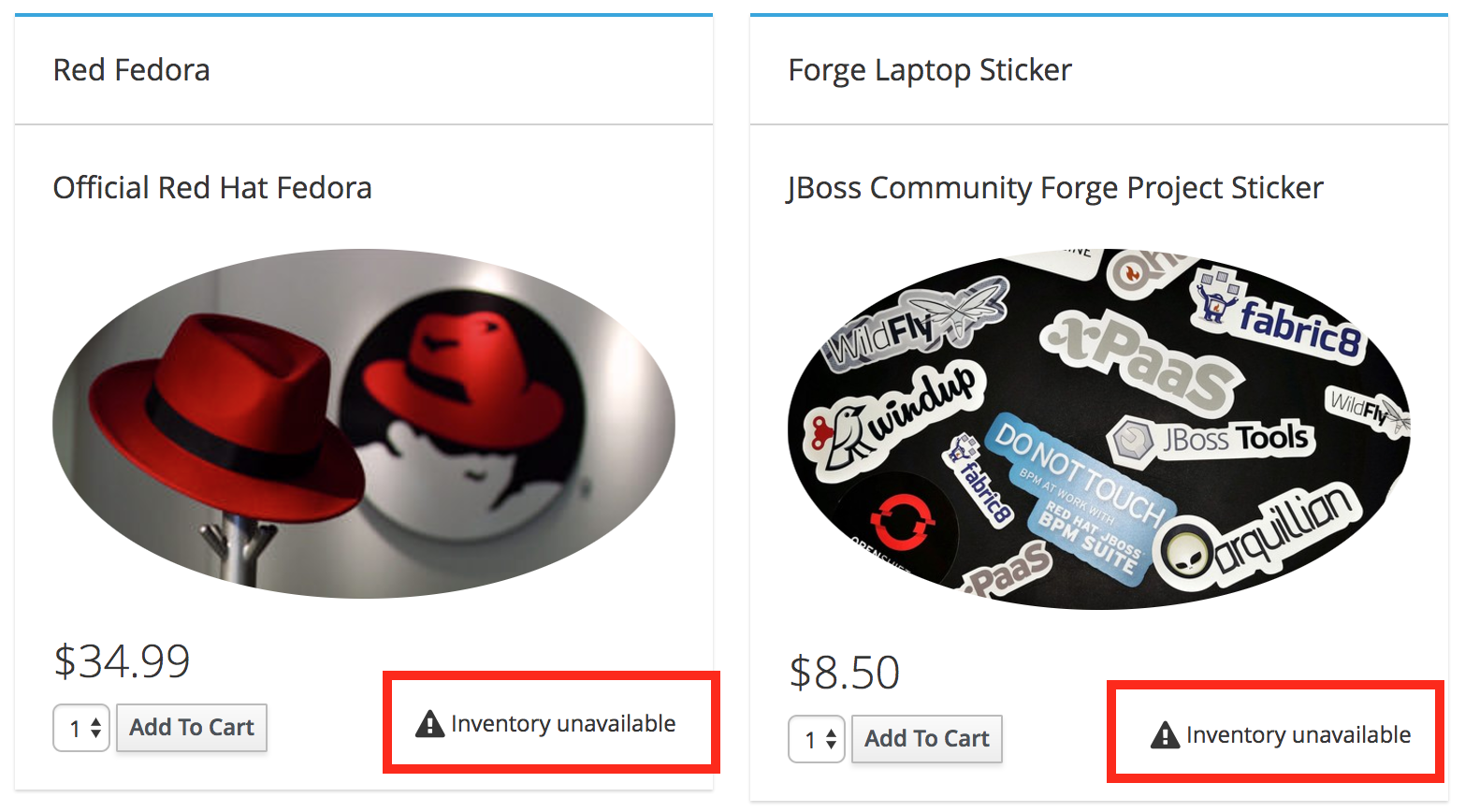
After a quick introduction, we demonstrated that after shutting down the live inventory container (by down-scaling it to 0 pods), the inventory service was unavailable but the whole application was still running, just reporting that the message "Inventory unavailable". That’s because in our camel - hystrix route, we defined a static fallback (a string) in the case of service unavailability.
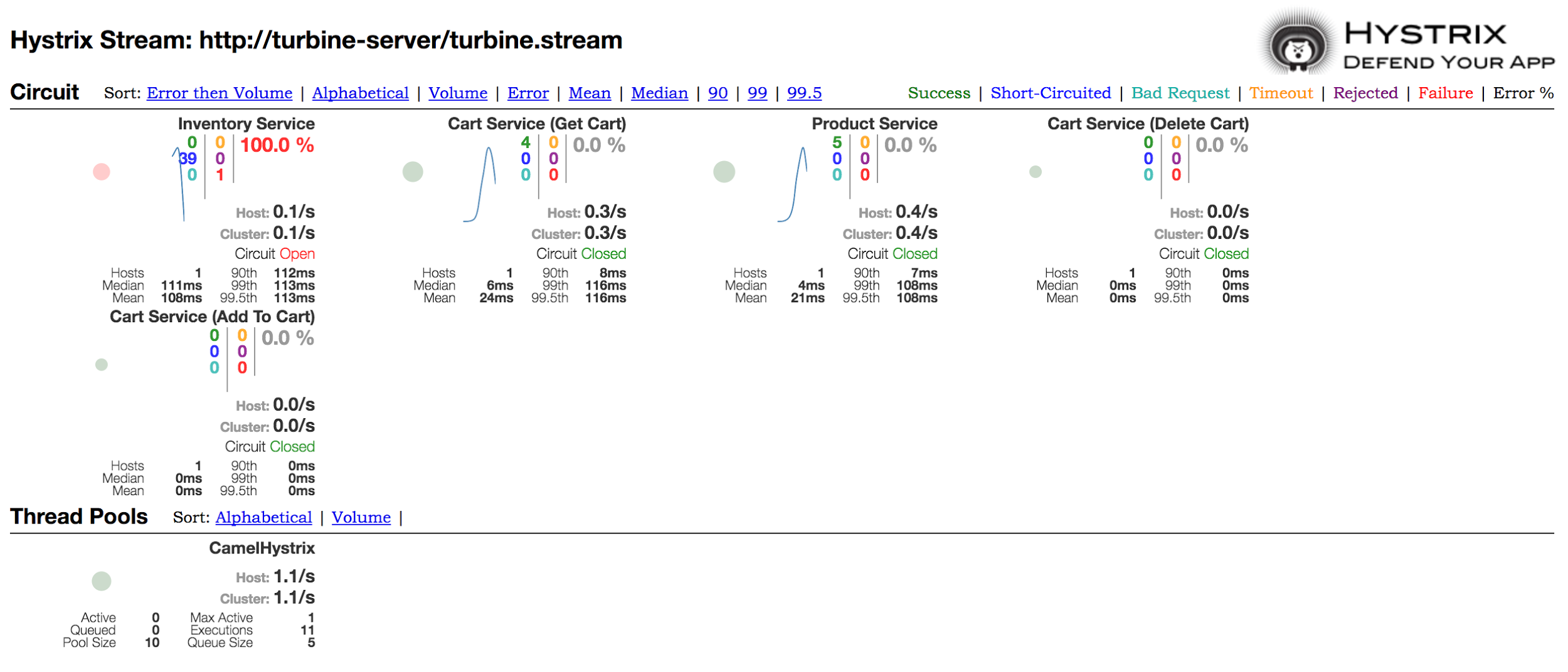
Looking at Hystrix console the circuit for the Inventory service is "open".
That's all!
Thank you so much if you joined OpenShift Container Platform Roadshow in Milan/Rome and see you soon!
About Alessandro
 Alessandro Arrichiello is a Solution Architect for Red Hat Inc. He has a passion for GNU/Linux systems, which began at age 14 and continues today. He worked with tools for automating Enterprise IT: configuration management and continuous integration through virtual platforms. He’s now working on distributed cloud environment involving PaaS (OpenShift), IaaS (OpenStack) and Processes Management (CloudForms), Containers building, instances creation, HA services management, workflows build.
Alessandro Arrichiello is a Solution Architect for Red Hat Inc. He has a passion for GNU/Linux systems, which began at age 14 and continues today. He worked with tools for automating Enterprise IT: configuration management and continuous integration through virtual platforms. He’s now working on distributed cloud environment involving PaaS (OpenShift), IaaS (OpenStack) and Processes Management (CloudForms), Containers building, instances creation, HA services management, workflows build.
About Giuseppe
 Giuseppe Bonocore is a Solution Architect for Red Hat Inc., working on topics like Application Development, JBoss Middleware e Red Hat Openshift. Giuseppe has more than 10 years of experience about Open Source software, in different roles. Before joining Red Hat, Giuseppe worked in technical leadership roles in many different international projects, deploying open source based projects all across Europe.
Giuseppe Bonocore is a Solution Architect for Red Hat Inc., working on topics like Application Development, JBoss Middleware e Red Hat Openshift. Giuseppe has more than 10 years of experience about Open Source software, in different roles. Before joining Red Hat, Giuseppe worked in technical leadership roles in many different international projects, deploying open source based projects all across Europe.
Get immediate hands-on experience with the Red Hat OpenShift Container Platform TestDrive Lab on Amazon Web Services (AWS) or start a 30-day free trial to evaluate Red Hat OpenShift Container Platform in your datacenter.
Last updated: June 27, 2023