It's been a while since our last deep-dive into the Docker project graph driver performance. Over two years, in fact! In that time, Red Hat engineers have made major strides in improving container storage:
- Introduced the docker-storage-setup package to help make configuring devicemapper-based storage a snap.
- Introduced full support for overlay FS in RHEL7.2+ when used with containers
- Introduced overlay2 as Tech Preview mode
- Gotten SELinux support to both overlay and overlay2 merged into upstream kernel 4.9
- Added a warning message for when folks are using loop-lvm
All of that, in the name of providing enterprise-class stability, security and supportability to our valued customers.
As discussed in our previous blog, there are a particular set of behaviors and attributes to take into account when choosing a graph driver. Included in those are page cache sharing, POSIX compliance and SELinux support.
Reviewing the technical differences between a union filesystem and devicemapper graph driver as it relates to performance, standards compliance and density, a union filesystem such as overlay2 is fast because
- It traverses less kernel and devicemapper code on container creation (devicemapper-backed contpersistent volumeainers get a unique kernel device allocated at startup).
- Containers sharing the same base image startup faster because of warm page cache
- For speed/density benefits, you trade POSIX compliance and SELinux (well, not for long!)
There was no single graph driver that could give you all these attributes at the same time -- until now.
How we can make devicemapper as fast as overlay2
With the industry move towards microservices, 12-factor guidelines and dense multi-tenant platforms, many folks both inside Red Hat as well as in the community have been discussing read-only containers. In fact, there’s been a --read-only option to both the Docker project, and kubernetes for a long time. What this does is create a mount point as usual for the container, but mount it read-only as opposed to read-write. Read-only containers are an important security improvement as well as they reduce the container’s attack surface. More details on this can be found in a blog post from Dan Walsh last year.
When a container is launched in this mode, it can no longer write to locations it may expect to (i.e. /var/log) and may throw errors because of this. As discussed in the Processes section of 12factor.net, re-architected applications should store stateful information (such as logs or web assets) in a stateful backing service. Attaching a persistent volume that is read-write fulfills this design aspect: the container can be restarted anywhere in the cluster, and its persistent volume can follow it.
In other words, for applications that are not completely stateless an ideal deployment would be to couple read-only containers with read-write persistent volumes. This gets us to a place in the container world that the HPC (high performance/scientific computing) world has been at for decades: thousands of diskless, read-only NFS-root booted nodes that mount their necessary applications and storage over the network at boot time. No matter if a node dies...boot another. No matter if a container dies...start another.
Use of a pattern like this gives us some additional flexibility in the Docker project graph driver layer as well. In order to deliver page-cache sharing, POSIX-compliance and SELinux support together, Vivek and I began prototyping a new design (which we’re calling the shared-rootfs).
This technique is not terribly new and has been used by several other systems in the past. But it is new to the Linux container ecosystem. Vivek has prepared a patch for the Docker project here and Dan Walsh has a patch to add SELinux support to runc here.
The new --shared-rootfs daemon option has very important implications for usability, performance and density. When --shared-rootfs is passed to the docker daemon at start-up, any container run as --read-only will automatically share it’s rootfs with the base image.
In the current implementation of Docker project's graph drivers, when a new container is created from the base image it gets it’s own mount point. This is where the behavior of graph drivers differ. In this scenario, a union filesystem such as aufs or overlay will maintain inode numbers between the base image and container. btrfs and devicemapper will not -- this is what leads to the difference in page-cache sharing behavior:
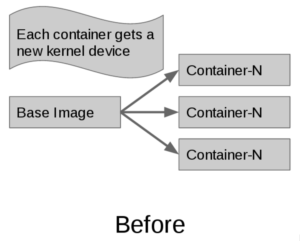
When using the --shared-rootfs option to the docker daemon, a new kernel device is replaced with a bind-mount of the base image filesystem, mounted in read-only mode. The combination of bind mount and read-only root fs looks like this:
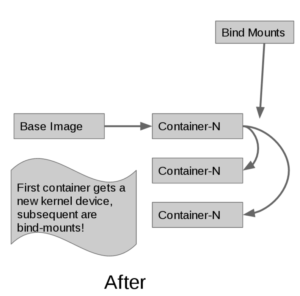
Using a bind-mount allows us to achieve our main goals: page-cache sharing, optimal density of containers per system, startup speed and POSIX compliance.
How does it perform?
We used the same test harness that was used for the original blog. This involves creating 1000 containers in three modes:
- devicemapper read-write (our current default mode, called dm-rw in the graphs)
- devicemapper read-only (the new shared-rootfs mode, called dm-ro in the graphs)
- overlay2
This was done on a 16-core system with 128GB RAM, RHEL 7.3 Beta, a single SSD for all tests, and used docker-1.12 plus Vivek’s patch.
To create 1000 “pause” pods and delete them:
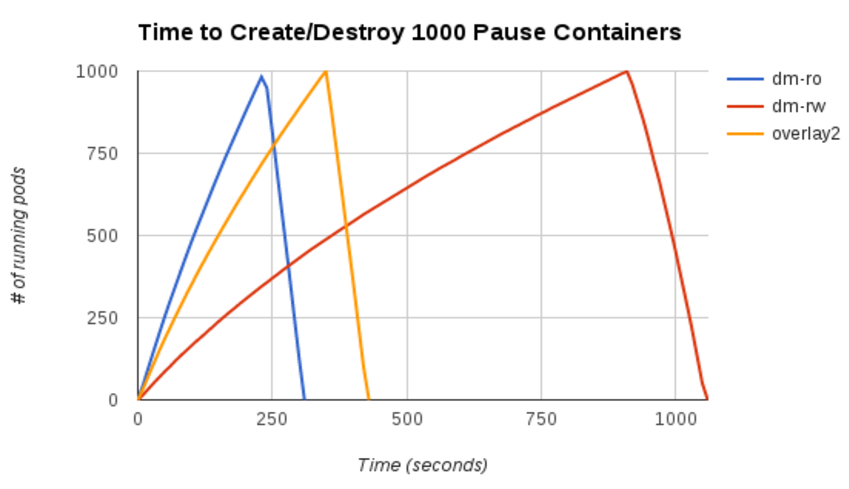
- dm-ro is 25% faster than overlay2 and 250% faster than dm-rw.
How much disk I/O is done to start each container:
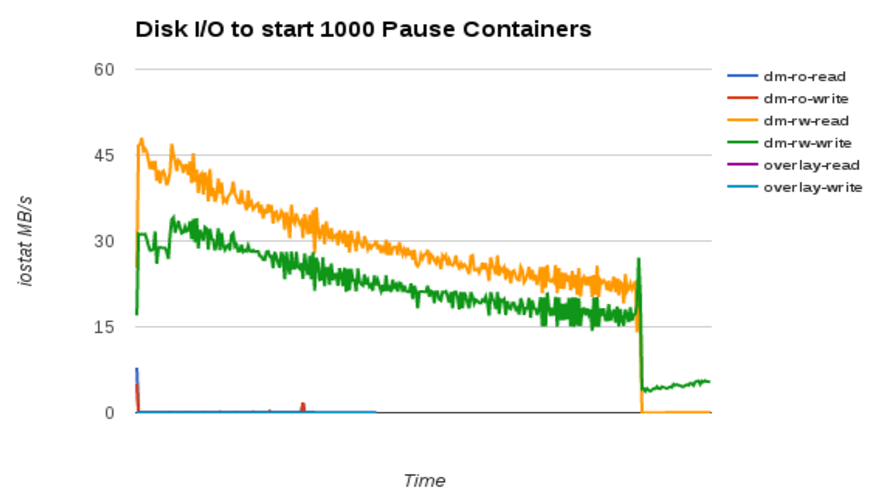
- As reported in the previous blog, devicemapper (dm-rw) does unique I/O for each container start, because there is no page-cache sharing.
- Note that the dm-ro and overlay2 modes do I/O at the very beginning to start the first container, but then no I/O after that. Exactly what we want -- the behavior of a shared page-cache.
How does it affect individual container start times?
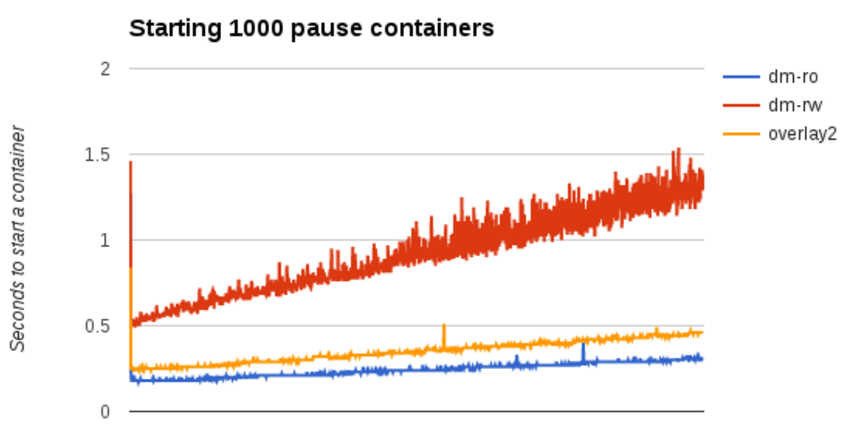
- Regardless of the graph driver, containers take an increasing amount of time as more containers are running.
- Notice again the initial spike when the base image content is pulled from disk into page-cache.
- Note that dm-ro is now consistently faster than overlay2 by approximately 50 milliseconds, and significantly faster than dm-rw.
Here you can see that the shared-rootfs mode saves a significant amount of memory:
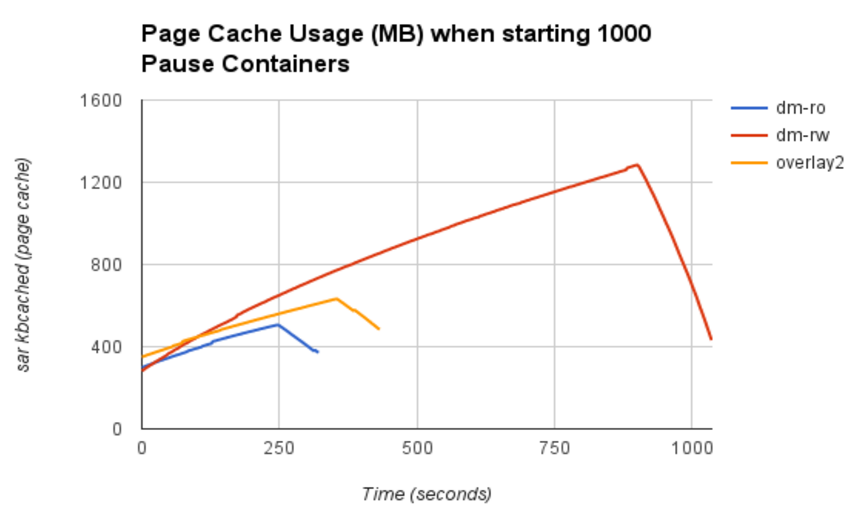
- drop_caches=3 run before every test
- Approximately 1GB memory is saved when comparing dm-rw with dm-ro.
- Slightly less memory used by dm-ro when compared with overlay2.
And here’s the best news...
We believe the same shared-rootfs technique can be brought to other graph drivers as well -- vfs and overlay2 included!
Having a single graph driver deliver the performance you want, with the security and POSIX compliance you need on-demand, at runtime...is a powerful new capability.
A few notes about the data…
This performance data and efficiency improvements are taken from an ideal scenario of a single image being run 1000 times in order to clearly demonstrate the improved behavior. Efficiency improvements will vary when using --shared-rootfs, largely depending on image re-use patterns in your environment. Assuming a typical production scenario where a smaller, well-curated pool of properly secured and patched base images, we do expect measurable benefit from this technique.
How does this affect Kubernetes: the answer is that it doesn’t just yet -- we’re figuring out the best way to surface this...one option would be that perhaps when specifying a read-only container in a Kubernetes PodSpec, it automatically implies shared-rootfs. In our current patch for the Docker project, you can still use read-only by itself -- backwards compatible for existing read-only users)
Vivek has submitted a first cut of implementing shared-rootfs to the Docker project for review. We look forward to iterating on the design with the community, and ultimately seeing it through into Red Hat’s products!
Last updated: February 23, 2024