Introduction:
Environment:
- Infinispan 9.0.0
- Spark 2.0.1
- OpenShift Dedicated v3.3
- Oshinko
Spark Batch Job Example:
apiVersion: batch/v1
kind: Job
metadata:
name: recommend-mllib-scheduled
spec:
parallelism: 1
completions: 1
template:
metadata:
name: recommend-mllib
spec:
containers:
- name: recommend-mllib-job
image: docker.io/metadatapoc/recommend-mllib:latest
imagePullPolicy: "Always"
env:
- name: SPARK_MASTER_URL
value: "spark://instance:7077"
- name: RECOMMEND_SERVICE_SERVICE_HOST
value: "jboss-datagrid-service"
- name: SPARK_USER
value: bob
restartPolicy: Never
Scheduled Job (Running Spark Job Every 5 mins):
apiVersion: batch/v2alpha1
kind: ScheduledJob
metadata:
name: sparkrecommendcron
spec:
schedule: "*/5 * * * ?"
jobTemplate:
spec:
template:
spec:
containers:
- name: pi
image: docker.io/metadatapoc/recommend-mllib:latest
imagePullPolicy: "Always"
env:
- name: SPARK_MASTER_URL
value: "spark://instance:7077"
- name: RECOMMEND_SERVICE_SERVICE_HOST
value: "jboss-datagrid-service"
- name: SPARK_USER
value: bob
restartPolicy: Never
Environment Setup
oc cluster up
oc new-app -f http://goo.gl/ZU02P4
oc policy add-role-to-user edit -z oshinko
oc new-app -f https://goo.gl/XDddW5
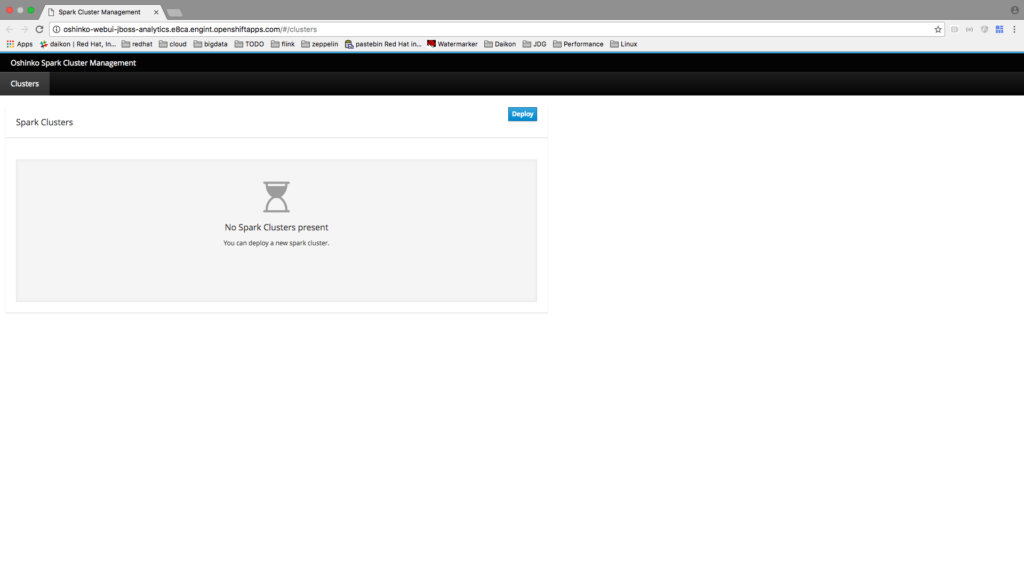
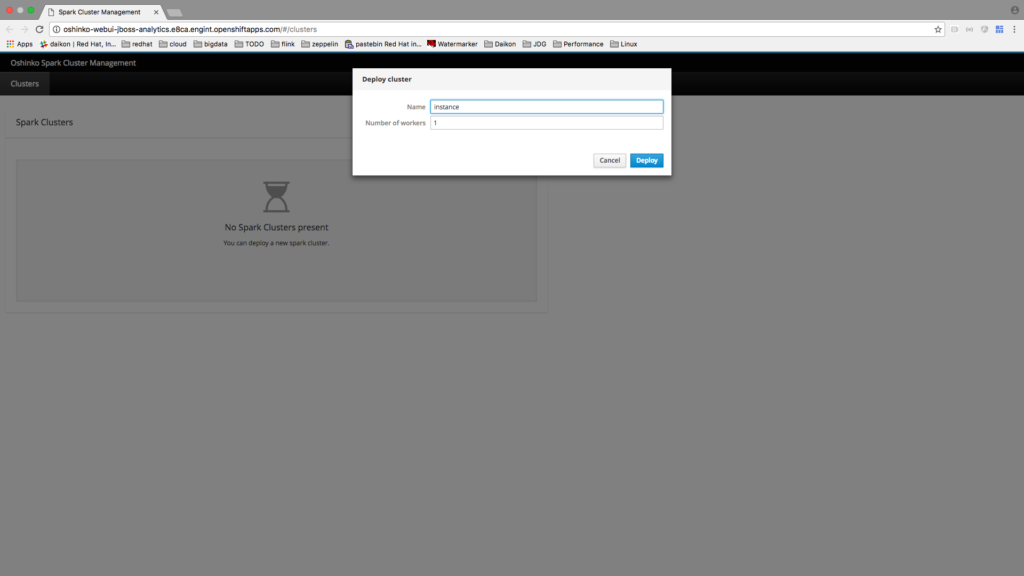
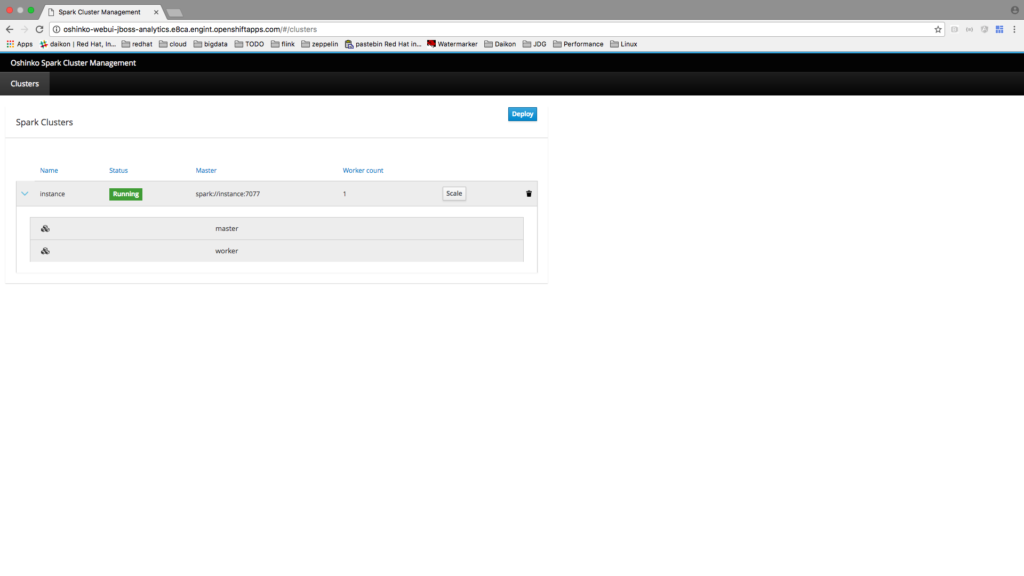
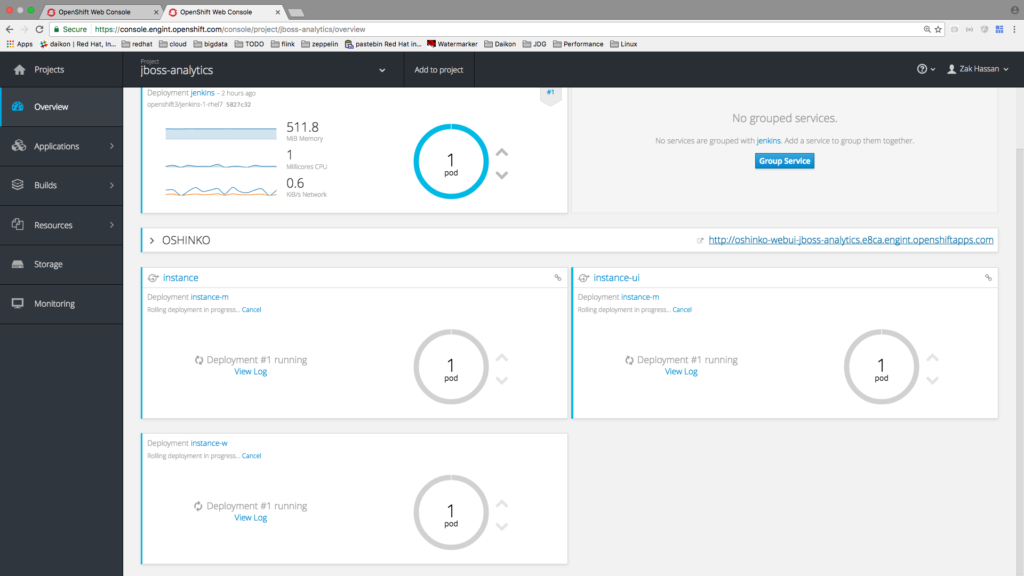
Spark Job Template
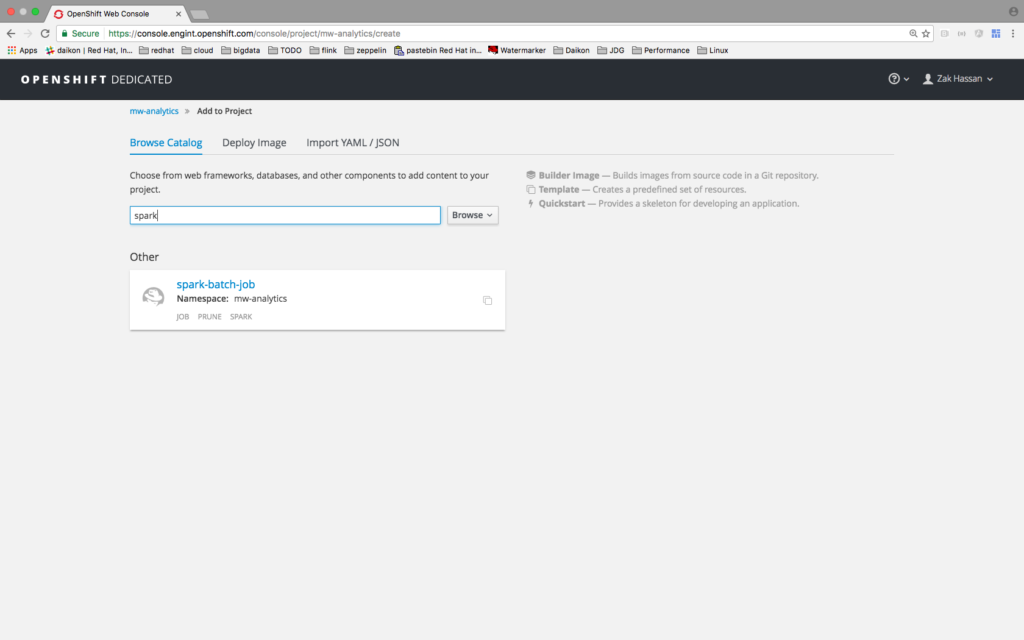
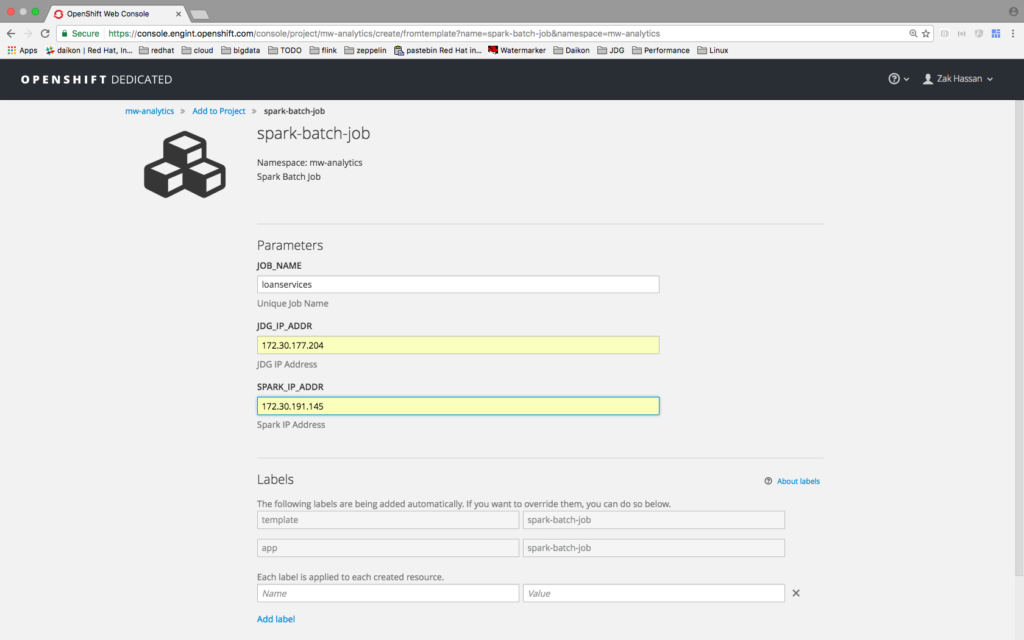
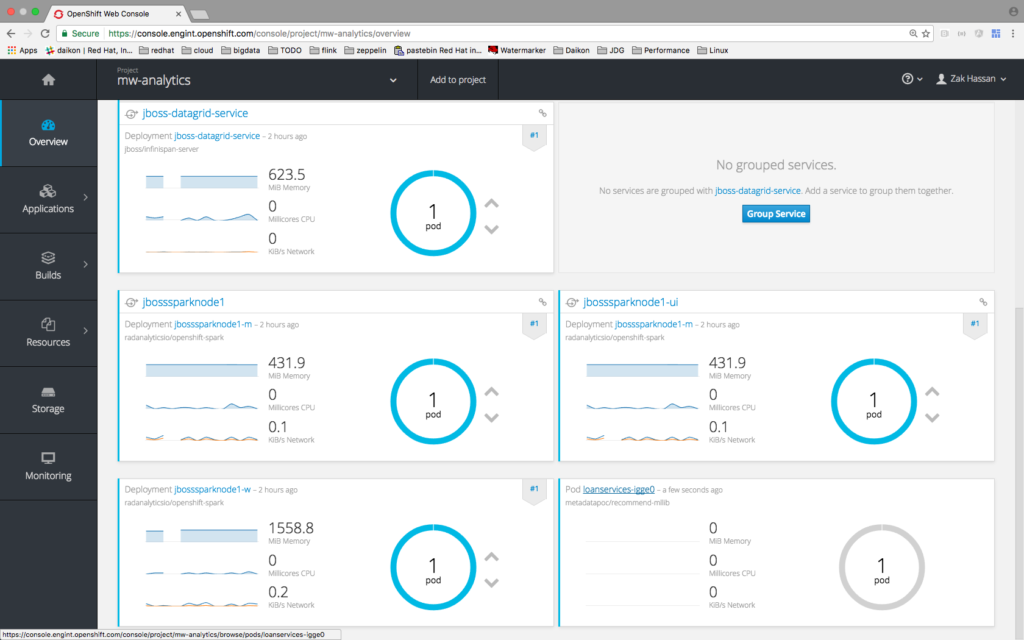
Video Demonstration:
Links to Project and Example Source Code Used in Demo
To download and learn more about Red Hat JBoss Data Grid, an in-memory data grid to accelerate performance that is fast, distributed, scalable, and independent from the data tier.
