Persistent memory, or pmem, is an exciting new storage technology that combines the durability of storage with the low access latencies and high bandwidth of DRAM. In this article, we'll discuss the types of pmem hardware, a new programming model for pmem, and how to get access to pmem through the OS. Persistent memory, sometimes called storage class memory, can be thought of as a cross between memory and storage. It shares a couple of properties with memory. First, it is byte addressable, meaning it can be accessed using CPU load and store instructions, as opposed to read() or write() system calls that are required for accessing traditional block-based storage. Second, pmem has the same order of magnitude performance as DRAM, meaning it has very low access latencies (measured in the tens to hundreds of nanoseconds). In addition to these beneficial memory-like properties, contents of persistent memory are preserved when the power is off, just as with storage. Taken together, these characteristics make persistent memory unique in the storage world. [caption id="" align="alignright" width="389"]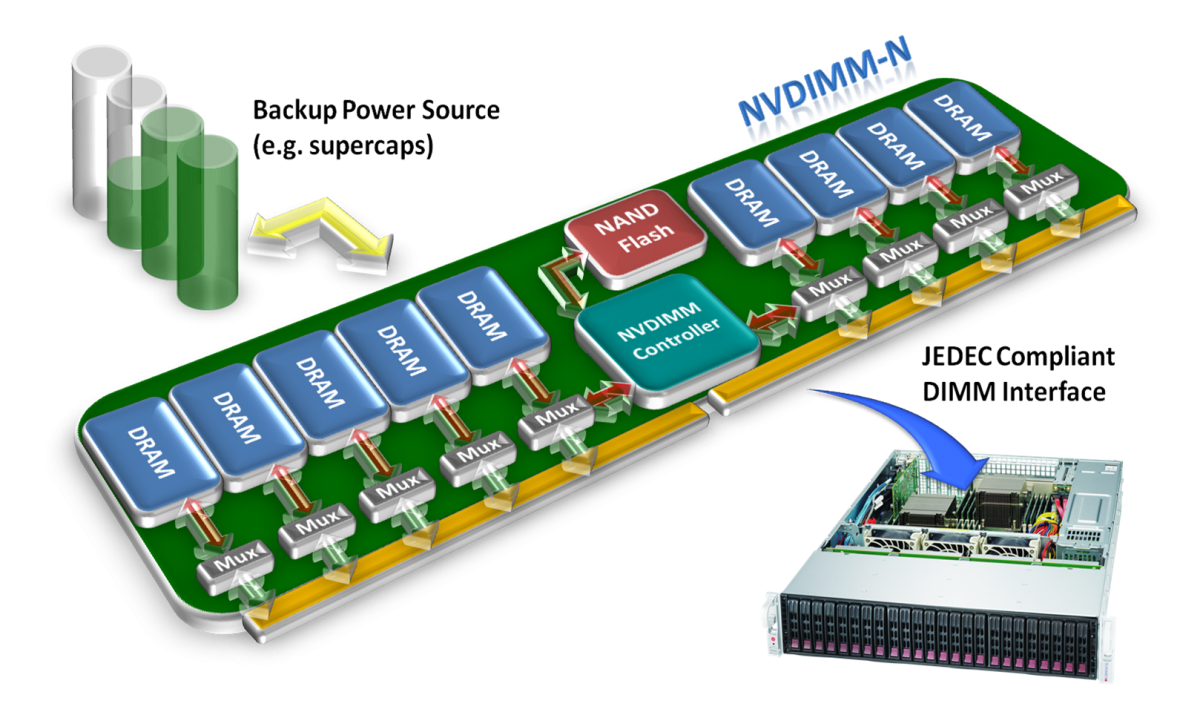 NVDIMM-N
NVDIMM-N
Source: SNIA SSSI[/caption] Persistent memory hardware is available today in the form of Non-Volatile Dual Inline Memory Module - N (NVDIMM-N). This type of persistent memory is composed of traditional DRAM, a power source such as a battery or one or more supercapacitors, and NAND flash. The DRAM portion is exposed to the operating system as persistent memory. On a power-loss event, the DRAM is put into self refresh mode using the power source, and the contents of the DRAM are copied into the NAND flash. When power is restored, the contents of flash are copied back to DRAM before the operating system gets access to it. In this way, the DRAM appears to retain its contents over power loss. NVDIMM-Ns, therefore, provide capacities and performance that are on-par with existing DRAM modules today, at prices that are higher than that of DRAM. This puts them at a very high price point in terms of $/GB (a common ratio used when discussing the cost of storage). Future NVDIMMs will use newer memory technologies that do not require power to retain their contents. These new types of memory also promise larger capacities at a lower price point than DRAM. However, access latencies are expected to be higher. Moving storage to the memory bus has wide ranging implications. For decades, applications have been architected to avoid making trips out to secondary storage because it is so slow. To get an idea of how slow, consider the following table, which contains timings that should be familiar to any application developer.
| fetch from main memory | 60 ns* |
| 4KB random read from an enterprise SSD | 75,000 ns |
| fetch from new disk location (seek, 15k rpm) | 2,000,000 ns |
* Source: Performance Analysis Guide for Intel Core i7 Processors and Intel Xeon 5500 processors As you can see, the penalty for going out to disk is 3 to 5 orders of magnitude higher than memory for small accesses! With persistent memory, the access penalty for storage is all but eliminated. So, now that storage resides directly on the memory bus, how would you change your application? The SNIA NVMP-TWG set out to answer that question and came up with the NVM Programming Model Specification (NVM PM spec.). [caption id="attachment_429496" align="aligncenter" width="492"]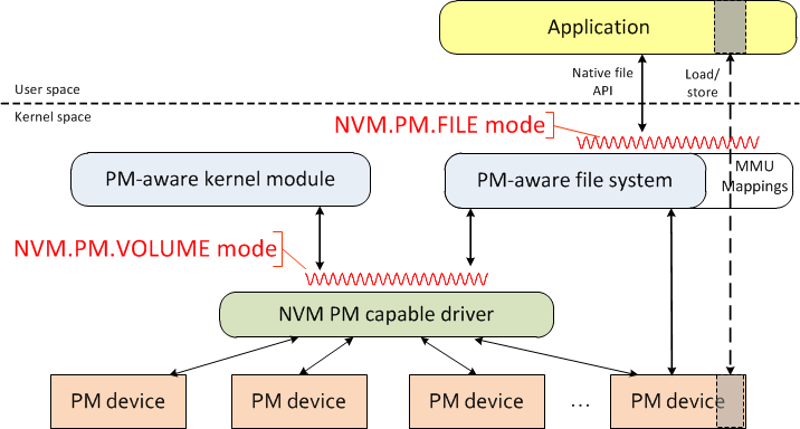 NVM.PM Access Modes[/caption] In this diagram, taken from the NVM PM spec., the red squiggly lines represents the interfaces defined by the programming model. For our purposes, we will focus on the NVM.PM.File mode, as that is what is available to applications. Notice how the programming model builds upon existing file system interfaces. File systems provide useful functionality, such as a namespace, permissions, block allocation, quota, and so on. Removing the file system would require reinventing much of the same infrastructure. Instead, all of the existing file system interfaces are expected to work on persistent memory. The main difference is that the mmap system call is defined to return a direct mapping to the underlying storage. This is depicted by the right-most dotted line in the diagram. Once that mapping is established, an application may perform loads and stores directly from and to the media--the kernel is not involved at all. In Linux, this functionality is provided by the direct access, or dax, mount option, currently available on the ext4 and xfs file systems. As you can see, applications must be modified to take full advantage of the byte-addressability of persistent memory. However, there is also a way for unmodified applications to make use of persistent memory: the btt driver (discussed later) presents pmem as a regular block device. For many applications, this legacy access method will be fast enough. There are pros and cons to both the legacy storage path and the dax path. The direct access method affords lower access latencies and a load/store programming model for application data. However, because such accesses bypass the kernel, it means that applications using the direct access method will not be able to take advantage of interposition drivers. Those drivers provide useful functionality, such as software RAID, encryption, compression and remote mirroring. A pmem-aware application wishing to use such functionality would have to reimplement it, or use a library. This adds administrative overhead, as there are now multiple places that storage configuration must be performed. Conversely, applications using the block device will get higher latency access, but will be able to take advantage of the full block layer. The decision of whether it makes sense to add pmem support will be specific to each application. With that background information out of the way, we can now focus on what persistent memory looks like from the system administrator's perspective. In this post, we only consider NVDIMM-N devices, because they are available today. NVDIMMs can be grouped into interleave sets just like normal DRAM. An interleave set is like a RAID 1 (stripe) across multiple DIMMs. For DRAM, memory is often configured this way to increase performance. NVDIMMs also benefit from increased performance when configured into interleave sets. However, there is another advantage: interleaving combines multiple smaller NVDIMMs into one larger logical device. (Note that configuration of interleave sets is done via the system BIOS or UEFI firmware.) When a system with NVDIMMs boots, the operating system will create pmem device nodes for each interleave set. For example, if there are 2 8GiB NVDIMMs as part of an interleave set, the system will create a single device node of size 16GiB. You can list the NVDIMMs in your system using the ndctl utility:
NVM.PM Access Modes[/caption] In this diagram, taken from the NVM PM spec., the red squiggly lines represents the interfaces defined by the programming model. For our purposes, we will focus on the NVM.PM.File mode, as that is what is available to applications. Notice how the programming model builds upon existing file system interfaces. File systems provide useful functionality, such as a namespace, permissions, block allocation, quota, and so on. Removing the file system would require reinventing much of the same infrastructure. Instead, all of the existing file system interfaces are expected to work on persistent memory. The main difference is that the mmap system call is defined to return a direct mapping to the underlying storage. This is depicted by the right-most dotted line in the diagram. Once that mapping is established, an application may perform loads and stores directly from and to the media--the kernel is not involved at all. In Linux, this functionality is provided by the direct access, or dax, mount option, currently available on the ext4 and xfs file systems. As you can see, applications must be modified to take full advantage of the byte-addressability of persistent memory. However, there is also a way for unmodified applications to make use of persistent memory: the btt driver (discussed later) presents pmem as a regular block device. For many applications, this legacy access method will be fast enough. There are pros and cons to both the legacy storage path and the dax path. The direct access method affords lower access latencies and a load/store programming model for application data. However, because such accesses bypass the kernel, it means that applications using the direct access method will not be able to take advantage of interposition drivers. Those drivers provide useful functionality, such as software RAID, encryption, compression and remote mirroring. A pmem-aware application wishing to use such functionality would have to reimplement it, or use a library. This adds administrative overhead, as there are now multiple places that storage configuration must be performed. Conversely, applications using the block device will get higher latency access, but will be able to take advantage of the full block layer. The decision of whether it makes sense to add pmem support will be specific to each application. With that background information out of the way, we can now focus on what persistent memory looks like from the system administrator's perspective. In this post, we only consider NVDIMM-N devices, because they are available today. NVDIMMs can be grouped into interleave sets just like normal DRAM. An interleave set is like a RAID 1 (stripe) across multiple DIMMs. For DRAM, memory is often configured this way to increase performance. NVDIMMs also benefit from increased performance when configured into interleave sets. However, there is another advantage: interleaving combines multiple smaller NVDIMMs into one larger logical device. (Note that configuration of interleave sets is done via the system BIOS or UEFI firmware.) When a system with NVDIMMs boots, the operating system will create pmem device nodes for each interleave set. For example, if there are 2 8GiB NVDIMMs as part of an interleave set, the system will create a single device node of size 16GiB. You can list the NVDIMMs in your system using the ndctl utility:
# ndctl list
[
{
"dev":"namespace1.0",
"mode":"raw",
"size":17179869184,
"blockdev":"pmem1"
},
{
"dev":"namespace0.0",
"mode":"raw",
"size":17179869184,
"blockdev":"pmem0"
}
]
Here we have two interleave sets, of 16GiB each. Note that each device has a namespace associated with it. A namespace is simply persistent memory capacity that is accessed through a pmem device (see the Linux kernel's Documentation/nvdimm/nvdimm.txt for more information). A pmem device can be in one of three modes: raw, sector or memory. The size field should be self-explanatory. Finally, the blockdev is the name of the device node. For the example above, /dev/pmem0 and /dev/pmem1 will be created. Note that all of the namespaces are in raw mode, which is the default. Unfortunately, it is also almost never the right choice. Raw mode supports direct access (DAX), but it does not support using the persistent memory for DMA operations. If you want to use the device for DAX, then memory mode would be more appropriate. If you want to use pmem as a block device, then the sector mode is strongly recommended. This last statement warrants more explanation. Block devices are so-named because they present storage as a linear address space of "blocks." Those blocks are the smallest addressable unit. Typically, this is 512 bytes, though more recently 4 KiB block size devices have appeared. An application that wishes to do journalling, therefore, may choose to write a commit record to a single logical block. The idea is that a single block write will either succeed or fail, but will never result in some mix of old and new data. The ability for storage to atomically update the contents of a single block is referred to as power-fail write atomicity. Strangely enough, no storage standard actually requires this behavior of the device (except for NVM express, which came out relatively recently). However, most disk drives today sort of provide these semantics (at least most of the time) -- on power loss, for a write in progress you will often get one of: the new data, the old data, or an I/O error. As a result, application programmers have gotten lucky. Because many applications already require power-fail write atomicity, it is incumbent on any implementation of a persistent memory block device to provide that guarantee (we're very conservative in the storage world). This is where the sector mode comes in. Sector mode is implemented using the Block Translation Table (btt) driver in the kernel. That driver provides power-fail write atomicity of a single sector at the expense of some performance. You may be wondering whether the file systems themselves depend on power-fail write atomicity of a single sector. Fear not, ext4 and xfs can both tolerate torn sectors in RHEL 7.3. Now that we've covered the basic modes of operation, let's look at some examples on how to configure persistent memory for a particular use case.
Configuring PMEM for Use as a Block Device
Recall that block devices should be configured with a btt, which means setting the namespace to sector mode. That task is accomplished with the ndctl utility.
# ndctl create-namespace -f -e namespace1.0 -m sector
{
"dev":"namespace1.0",
"mode":"sector",
"size":17162027008,
"uuid":"029caa76-7be3-4439-8890-9c2e374bcc76",
"sector_size":4096,
"blockdev":"pmem1s"
}
NOTE: Changing the namespace mode is a destructive operation. Notice how the block device now has an 's' appended to its name. The 's', as you might have guessed, stands for sectored. This device can be used just like any other block device. For example, to create a file system on it, you can do the following:
# mkfs -t xfs /dev/pmem1s # mount /dev/pmem1s /mnt/fast
Note that you can also partition the device, use it as part of a volume group, use it as a caching tier in dm-cache, etc. It really is just a normal block device, and using persistent memory as a block device is fully supported in RHEL 7.3.
Configuring PMEM for Direct Access (DAX)
For DAX, we'll need to configure a namespace for memory mode. To do that, we again use the ndctl utility:
# ndctl create-namespace -f -e namespace0.0 -m memory -M mem
{
"dev":"namespace0.0",
"mode":"memory",
"size":17177772032,
"uuid":"e6944638-46aa-4e06-a722-0b3f16a5acbf",
"blockdev":"pmem0"
}
Here, we've converted namespace0.0 to a memory mode namespace, but you may be wondering what that "-M mem" is all about. As mentioned above, memory mode namespaces support DMA operations. In order for the kernel to perform DMA, it requires a data structure for each page in the memory region. The overhead of this data structure is 64 bytes per 4KiB page. For small devices, the amount of overhead is small enough to easily fit in DRAM (for example, this 16GiB namespace only requires 256MiB for page structures). Given that the NVDIMM is small (and expensive), it makes sense to store the kernel's page tracking data structures in DRAM. That's what "-M mem" indicates. Future NVDIMM devices could be TiBs in size. For those devices, the amount of memory required to store the page tracking data structures may exceed the amount of DRAM in the system (1TiB of pmem requires 16GiB just for page structures). As a result, it makes more sense to specify "-M dev" to store the data structures in the persistent memory itself in such cases. After configuring the namespace in memory mode, it is now ready for a file system. In RHEL 7.3, both ext4 and xfs have been modified to support persistent memory as a Technology Preview. File system creation requires no special arguments. However, in order to get DAX functionality, the file system must be mounted with the "dax" mount option.
# mkfs -t xfs /dev/pmem0 # mount -o dax /dev/pmem0 /mnt/pmem/
And that's it! Now applications wishing to make use of pmem can create files in /mnt/pmem, open them, and mmap them for direct access.
Experimenting without NVDIMMs
There are a couple of ways you can get started with persistent memory programming without any real hardware. First, you can run your application using a file system on a regular hard disk or SSD. This can be useful to ensure your application performs cache flushes in the right locations. However, it may also be too slow for any reasonable test, especially if the application performs a lot of msync calls. The other way to get started without real hardware is to set aside some RAM for use as "persistent memory." That will provide approximately the same access latency and bandwidth as real pmem, but of course will not provide persistence. To do this, you will have to boot your system using the "memmap=XG!YG" kernel boot parameter. Specifically, you'll have to tell the kernel at what address to reserve persistent memory, and how much of it you want. For example, adding this to your kernel boot line:
memmap=192G!1024G
will reserve 192GiB of DRAM, starting at offset 1024GiB. The kernel will configure the specified range of memory as an NVDIMM and will create the relevant pmem devices on boot. Note that you can specify multiple memmap= arguments, and each one will get its own pmem device node. The device can then be configured to block or memory mode as shown earlier. More information on choosing correct values to plug into the memmap= parameter can be found on the nvdimm kernel wiki.
Next Steps
Now that you have configured your real or emulated persistent memory, it's time to get started writing code! For that, I highly recommend using NVML, which is a suite of libraries that aid in persistent memory programming. The two most useful libraries, in my opinion, are libpmem and libpmemobj. The former simply abstracts hardware and operating system implementation details from the programmer, providing some basic intrinsic functions for mapping and flushing data. The second library provides full transactional support. I expect most developers will make use of the latter. To get started with nvml, have a look at the nvml blog, which contains code examples and tutorials. In summary, the first wave of persistent memory devices is available today in the form of NVDIMM-N, and future NVDIMM devices promise much larger capacities at a lower cost. Operating system support is in place to use these devices as fast disks in sector mode with btt, and this usecase is fully supported in RHEL 7.3. Pmem-aware applications can be written and tested using the ext4 and xfs file systems, which support memory mode and DAX as a Technology Preview in RHEL 7.3. Now is the time to evaluate how your application can best take advantage of persistent memory.
Last updated: March 20, 2023