Efficient static application security testing (SAST) is essential, but all the data from the process often creates a significant operational bottleneck. More than 80% of these results can be false positives, but manual triage is often too slow and inconsistent to keep up with development speed. To address this, the SastAI initiative was launched at Red Hat, in a collaboration with NVIDIA, to automate false positive (FP) identification using generative AI.
Unlike traditional models, the SastAI solution employs an agentic, multi-stage research workflow to autonomously investigate SAST findings by analyzing source code, CWE data, and existing security reports in context. By leveraging RAG and semantic code search, SastAI reduces noise and improves triage efficiency.
Triage funnel
Until recently, a major limitation persisted in the current SastAI methodology: The system often treats each new finding as a first-seen event. While we implement an embedding filtering step to clear out points similar to those already processed, it cannot yet learn from unique, non-similar data points over time.
This limitation is resolved by the specialized pattern harvesting mechanism, developed in strategic collaboration with IBM Research using a pattern mining approach. By extracting recurring logic and turning years of human expertise into automated, scalable intelligence, pattern harvesting greatly enhances the SastAI solution, now offering a tighter solution with better knowledge and reasoning. The application of these learned patterns achieved success with approx +10% uplift average in common metrics over the baseline SastAI model (see figure 1).
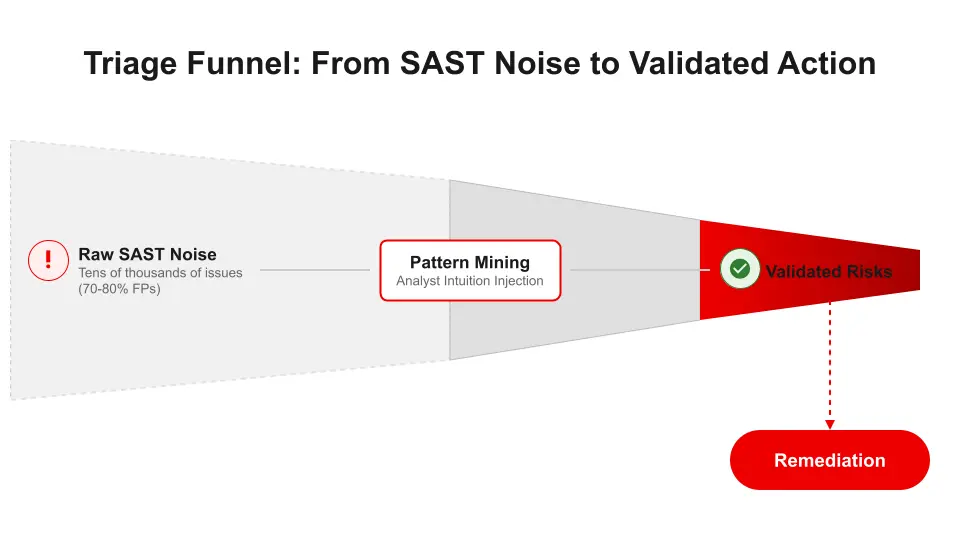
The pattern harvesting methodology
The backbone of this project is a sophisticated pattern mining workflow designed to ensure the AI learns the right lessons without taking "shortcuts". The process is detailed across the sast-pattern-learning and sast-ai-workflow repositories.
Strategic data preparation
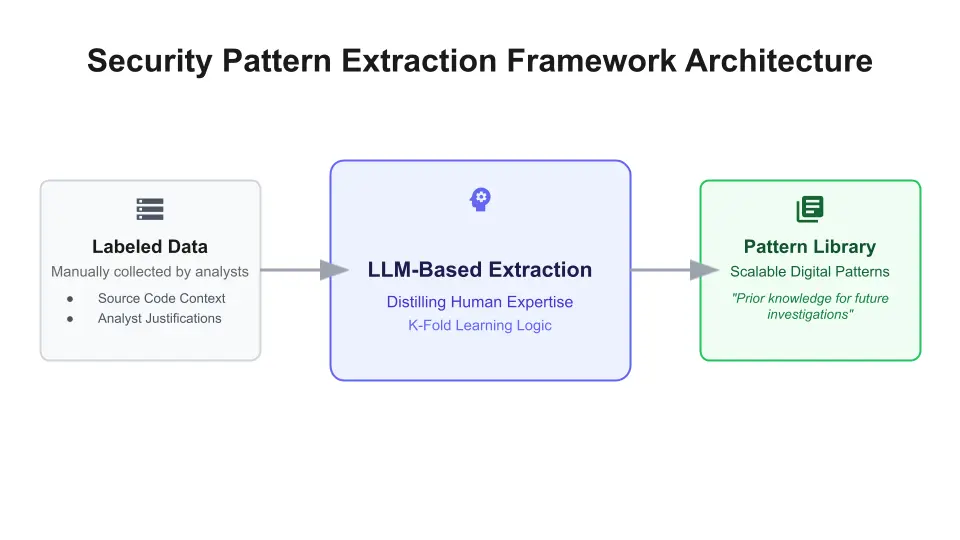
Learning requires high-quality data. The team utilized a robust dataset of approximately 8,000 human-annotated findings spanning over more than 200 packages. However, raw data is severely imbalanced and features an approximately 80/20 FP-to-TP ratio. Figure 2 illustrates the process of an LLM distilling human expertise from labeled data (source code and analyst justifications) to create a scalable pattern library.
To handle this, we implemented a three-way stratified sampling mechanism alongside traditional train-validation-tests split (60/20/20), a logic found in the process-mining-preprocessing branch (Figure 3).
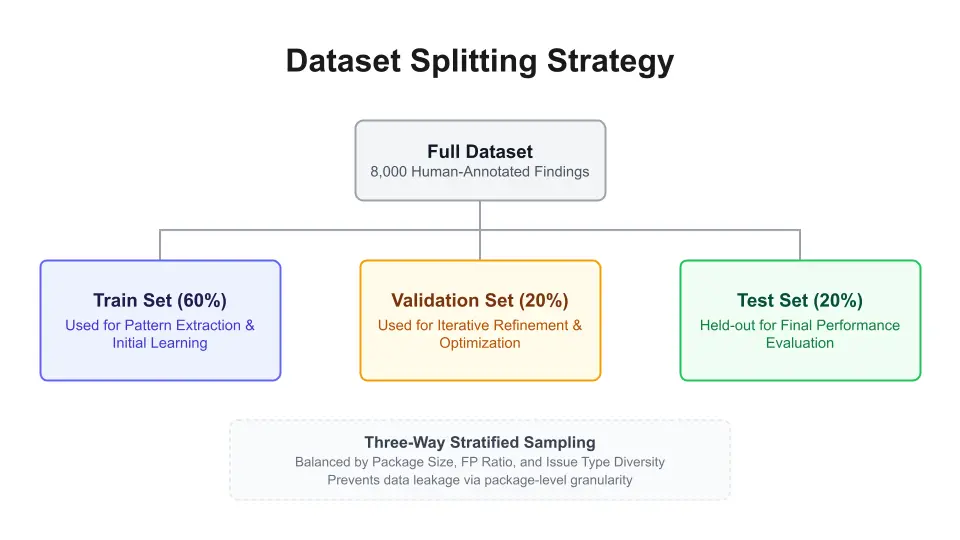
The sampling mechanism components are:
- Package granularity: Entire packages are assigned to a single set (train/validation/test) to prevent "data leakage" and model memorization.
- Package size and FP ratio: Packages are balanced by volume (small/medium/large) and noise levels (low/medium/high FP density).
- Issue type diversity: The top nine vulnerability classes are represented across all sets to ensure cross-category generalization.
This mechanism creates a solid representation of real world data.
The learning cycle: Extraction and refinement
The learning process happens in three distinct phases:
- Stratified K-fold learning (cross-extraction): To ensure learned patterns are generalizable and not overfit to specific codebases, we utilize a stratified k-fold approach. The dataset is split into k folds: For each iteration, the LLM extracts patterns and justifications from k-1 folds, which are then evaluated against the held-out fold. Once all iterations are complete, we utilize a targeted LLM deduplication task to synthesize the findings into a single, high-fidelity library. This cross-learning cycle ensures that the final patterns represent recurring logical structures rather than anomalies unique to a single subset of data.
- Iterative refinement: We evaluate the patterns on the training and validation sets to find misclassifications. Patterns are refined iteratively to maximize "cleaning power" (recall) without sacrificing "safety" (specificity). To ensure efficiency, the process implements early stop logic based on the convergence of the F1 score (or other configurable metrics), halting the refinement loop once improvements plateau.
- Final test evaluation: The learned patterns are applied to a completely unseen 20% "held-out" set. This validates that the AI has truly learned generalizable patterns that work across different repositories, rather than just memorizing a specific dataset.
Strategic model selection: Model size and type considerations
We evaluated various models to balance reasoning depth with operational cost. Our strategy uses a two-tiered approach:
- Pattern learning (big models): For extraction and refinement, we employ high-capacity frontier models. These models can distill complex analyst justifications into structured patterns.
- Inference (mid-range models): To simulate real-world usage, we focused on models within the 50 to 100 billion parameter range, utilizing both dense and mixture of experts (MoE) architectures.
We found that as a model becomes more capable, the improvement margin provided by patterns decreases. Highly advanced models can reason through the code independently. Conversely, less capable models see a bigger performance boost from these patterns. However, for these top-tier models, the patterns serve the secondary purpose of justification consistency: Injecting structured patterns ensures that reasoning and decisions are anchored in standardized logic.
Using smaller, self-hosted models (a key goal for SastAI, to reduce costs) introduces new complexities. You must inject the patterns without confusing the model or bloating its context window, which causes performance degradation or "forgetting."
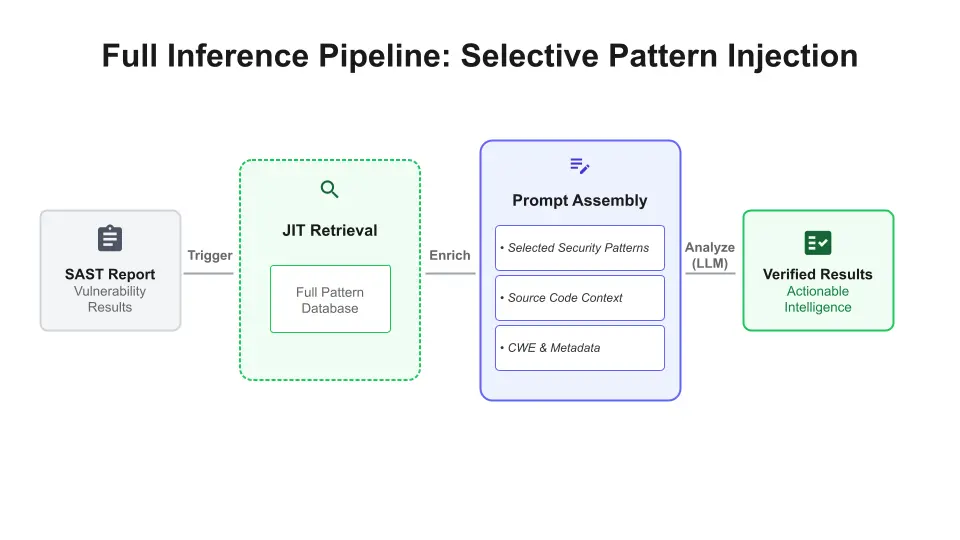
Selective context injection: Just-in-time (JIT) enrichment
To maintain scalability, SastAI avoids "context bloat" by not dumping all learned patterns into every prompt. Instead, we implement just-in-time (JIT) context enrichment.
Before the AI agent begins its review, the system identifies the characteristics of the issue - such as the CWE type and semantic code structure - and injects only the relevant JSON patterns at the moment of analysis. This transforms the operational complexity from O(N) to a stable O(1) or O(LogN) efficiency. This mechanism ensures the model receives hyper-focused, high-signal context without overwhelming its reasoning window.
Productization and the path forward
This project isn't just a research exercise, we are already looking toward the next steps:
- Product implementation: The core logic is being incorporated into the SastAI workflow to provide immediate value to users.
- Continuous learning loops: Establishing systems where the model continues to learn from new analyst decisions, creating a self-improving security ecosystem.
- Community and knowledge sharing: We are scoping the potential for open sourcing these workflows (staffed by the IBM student program) to drive cross-team adoption and awareness across the industry.
By moving from manual triage to automated logic (Figure 4), SastAI simplifies code security so developers can focus on building, rather than just triaging.
Share your feedback
We invite you to explore the foundational work, particularly the SastAI workflow repository and the pattern learning logic repository. Take a look at our project repos and share your thoughts and feedback with us as we continue to drive this work forward.
