A leap second is an adjustment that is once in a while applied to the Coordinated Universal Time (UTC) to keep it close to the mean solar time. The concept is similar to that of leap day, but instead of adding a 29th day to February to keep the calendar synchronized with Earth's orbit around the Sun, an extra second 23:59:60 is added to the last day of June or December to keep the time of the day synchronized with the Earth's rotation relative to the Sun. The mean solar day is about 2 milliseconds longer than 24 hours and in long term it's getting longer as the Moon is constantly slowing down the Earth's rotation.
UTC is based on the International Atomic Time (TAI) and it is currently 35 seconds behind TAI. The first leap second was inserted in 1972 and 25 seconds were inserted so far. The next one is scheduled for 30 June 2015, when the offset from TAI will increase to 36 seconds. Leap seconds are scheduled only about 6 months in advance.
There is a possibility that leap seconds will be abolished in the future. A discussion about this topic has been going on for a long time, but so far no agreement has been reached. The current plan is that the International Telecommunication Union (ITU) will decide at the World Radiocommunication Conference in November 2015.
The trouble with leap seconds on computers is that there is no room for them in the standard Unix time. That is the time which is kept by the CLOCK_REALTIME system clock and used by almost every application which needs to know the current time. It's defined as number of seconds since 00:00:00 UTC on 1 January 1970, but without leap seconds. The system clock cannot have time 23:59:60, every minute has 60 seconds and every day has 86400 seconds by definition.
Ordinary computer clocks are not stable enough to keep time on their own so accurate than an extra second added every year or two would matter, but when a clock is synchronized with NTP servers with millisecond accuracy, the inability of the clock to go through an inserted leap second is a real issue.
While technically it wouldn't be very difficult to modify an NTP implementation to keep the system time in a representation which does include leap seconds and use for instance special time zones (e.g. from the right directory in the tzdata package) to break the current time in applications to the correct date and the time of the day using only standard libc functions, there are too many applications that rely on the current definition, expecting that every day has 86400 seconds. Also, the applications would need to use a different representation to store future dates with a given time of day as leap seconds are scheduled only few months ahead. Otherwise with every inserted leap second any future dates after the leap second with a fixed time of the day would have to be shifted by one second ahead.
When a leap second is inserted to UTC, the system clock skips that second as it can't be represented and is suddenly ahead of UTC by one second. There are several ways how the clock can be corrected.
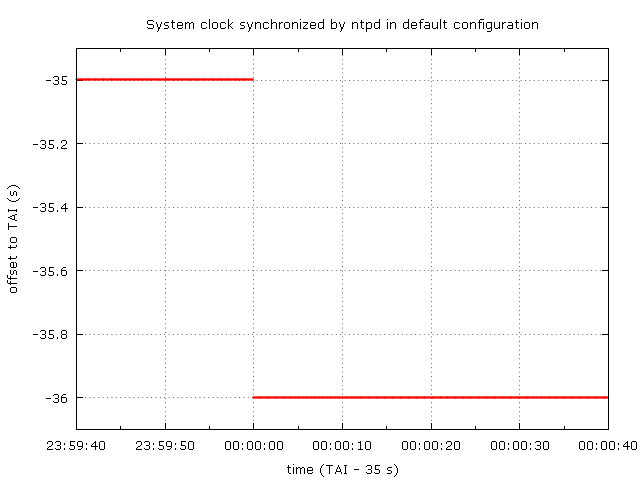
The most common approach is to simply step the clock back by one second when the clock gets to 00:00:00 UTC. This is implemented in the Linux kernel and it is enabled by default when the clock is synchronized with NTP servers by the ntpd or chronyd daemon from the reference or chrony NTP implementations respectively.
The backward jump doesn't happen exactly at 00:00:00, but rather on the first system clock update in that second. The clock repeats most of the 23:59:59 second and also a small part from the beginning of the 00:00:00 second. The outcome is that the clock is off by one second for one second.
The following graph shows how will the offset to TAI of a system clock keeping time in UTC and synchronized by ntpd or chronyd in default configuration change on 30 June 2015.
For some applications the backward jump can be a major problem. In some cases it's a bug that could be fixed by using the CLOCK_MONOTONIC clock instead of CLOCK_REALTIME. But when real time is really needed, there are problems that are difficult to fix, e.g. timestamps collected in the ambiguous second cannot be sorted correctly without additional information.
For applications where it would be possible to work with TAI time instead of UTC, the kernel provides a special CLOCK_TAI clock which does include leap seconds and doesn't need to be corrected after leap second, avoiding the problem with backward jump in the time entirely. It's implemented as a clock running at a fixed integral offset to CLOCK_REALTIME, which is atomically incremented by 1 when the CLOCK_REALTIME clock is stepped back on leap second. It was introduced in the Linux kernel version 3.10 and is available with the kernels shipped in RHEL7. Please note that the offset from CLOCK_REALTIME is initialized on boot to zero and neither ntpd nor chronyd set it by default to the correct value (currently 35). Switching to CLOCK_TAI in applications would of course require modifications to the code and possibly also all protocols that use the Unix representation of time.
A different approach to correct the system clock for leap second uses slewing instead of stepping. The clock is slowed down until UTC catches up with it. The time stays monotonic, but it is inaccurate for a longer time than with the step approach and it's also running slower. This may be or may be not acceptable depending on the application. Another issue is that the CLOCK_TAI clock in this case cannot be kept accurate and corrected without a (forward) step as the offset between CLOCK_REALTIME and CLOCK_TAI is an integral number.
Options with ntpd
With ntpd, the kernel backward step is used by default. With ntpd versions before 4.2.6, or 4.2.6 and later patched for this bug, the -x option (added to /etc/sysconfig/ntpd) can be used to disable the kernel leap second correction and ignore the leap second as far as the local clock is concerned. The one-second error gained after the leap second will be measured and corrected later by slewing in normal operation using NTP servers which already corrected their local clocks.
This graph shows the offset to TAI of a system clock synchronized by ntpd with the -x option and the default maximum polling interval of 1024 seconds.
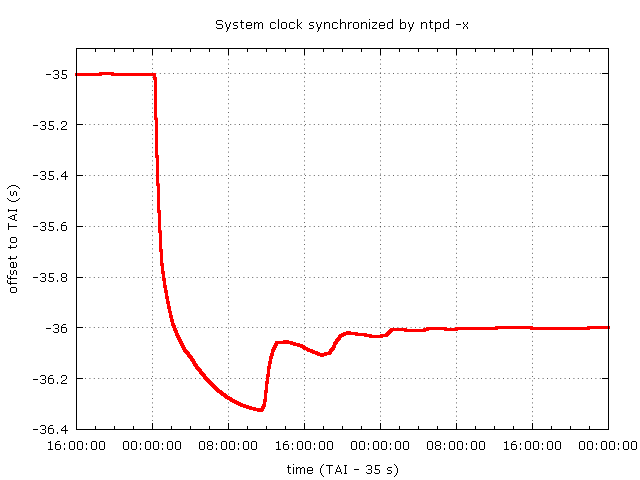
There is a significant overshoot and it takes about 2 days for the clock to get back to millisecond accuracy. This can be improved with a shorter polling interval. However, the time of the start of the correction and its course is random to some extent, so clocks on multiple systems using ntpd -x will drift apart from each other and will not get close together again until the correction is near its end. Again, that may or may not be acceptable.
Options with chronyd
When the system clock is synchronized by chronyd, which is the default NTP client since Fedora 16 and RHEL7, the leap second correction is by default made by the kernel. That is the same as with ntpd.
With version 2.0, which is now included in Fedora 22, the correction method can be configured in /etc/chrony.conf with the leapsecmode option. It can be set to four different values:
systemselects the default mode using the kernel stepstepselects a mode where the clock is stepped bychronydinstead of the kernel, this is similar tontpd(version 4.2.6 and later) configured with thedisable kernelcommand and it can be useful to avoid bugs in the kernel codeignoreselects a mode where no correction is made for the leap second itself and the clock is corrected later in normal NTP operation, similarly tontpdwith the-xoptionslewselects a slewing mode
This graph shows a system clock's offset to TAI when synchronized by chronyd with the leapsecmode option set to slew.
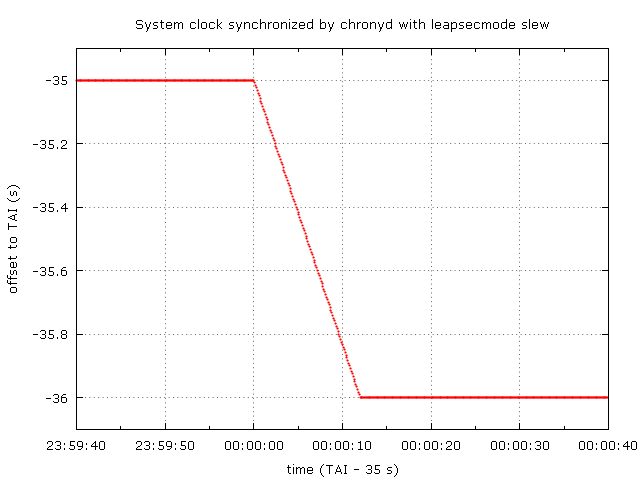
The correction starts as close to 00:00:00 UTC as the kernel can schedule the chronyd process to run and update the frequency of the clock. It takes 12 seconds to complete. The correction is quick, but the large frequency error of 8.3% makes any interval measured by the clock in that time longer by 8.3%. That may or may be not acceptable.
The slewing rate can be configured with the maxslewrate option. When the rate is set to 1000 parts per million (ppm), the graph will look similar, except the correction will be stretched over a longer time.
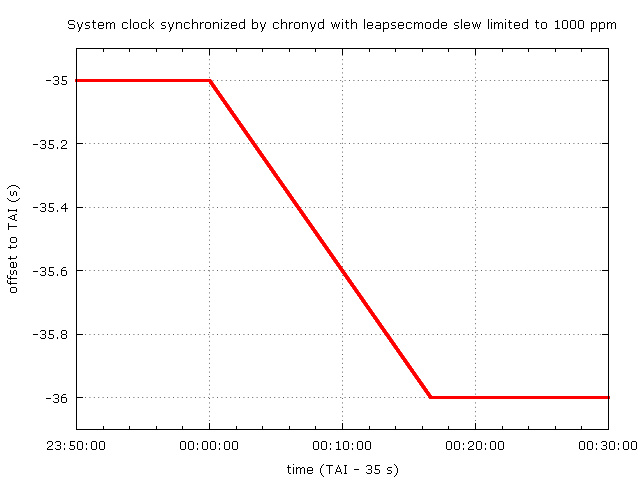
The correction now takes 1000 seconds and the frequency error during that correction is only 1000 ppm. Clocks on multiple systems using the same maxslewrate stay very close together the whole time. This might be a recommended configuration when the system or step modes are not acceptable.
Please note that unlike ntpd with the -x option, chronyd configured with leapsecmode slew can still be used as a good NTP server. The local clock is corrected by slew, but the time served to NTP clients is stepped on leap second. The slow local correction is not visible to the clients.
Leap smear with chronyd
A completely different approach to correct clocks for leap second on multiple systems in a controlled manner is to suppress the information about upcoming leap second on the NTP server and slowly slew the served NTP time instead. The clients don't know a leap second will be inserted, they don't make any corrections for it themselves and simply follow the server time which eventually brings them back to UTC. This idea was described by Google in 2011 as a leap smear.
On the client side no special configuration is needed. But care must be taken to ensure the clients use for synchronization only NTP servers that smear leap second in the exactly same way and not normal servers which announce leap second and also make the backward step when leap second is inserted. If a client used one smearing server and two or more normal servers, the smearing server would be outvoted by the others and marked as a falseticker, effectively disabling the leap smear. If it used one smearing server and one normal server, it wouldn't know which server to trust and would fail to synchronize until the servers agree with each other again.
As for the server side, chronyd since version 2.0 can be configured to perform a leap smear. It's implemented as a special case of a time smoothing feature, which was designed for servers that are most of the time isolated from Internet without any reference clocks and serve time in a network where clients are not required to keep very accurate time, but their clocks must stay close together. Normally, when an NTP server resynchronizes its clock after being offline for a long time, there is an abrupt change in the served time which the clients follow later at random times and it takes a while until their clocks are close to each other again. Leap second is handled as a one-second offset accumulated at 00:00:00 UTC that is smoothed out.
Since the smoothing process smooths out also frequency adjustments of the local clock, the leap smear is not exactly the same between different NTP servers. It's not recommended to configure an NTP client with more than one time smoothing server. A new option will likely be added to chronyd to smooth out only the leap second and nothing else to make the leap smear constant and allow the clients to use multiple servers safely.
This feature needs to be used carefully, because the server is intentionally not serving its best estimate of the true time. It would probably be a bad idea to do this on a public NTP server, similarly to the -x option with ntpd.
The slewing of the served time is not linear. The frequency has to be adjusted slowly without any steps in order to allow the clients to track it easily. In the Google implementation it was implemented with a cosine function, but it seems this year a simple linear smear will be used on their servers instead.
In chronyd it's implemented with a quadratic spline function with two or three pieces. An advantage over the cosine function is that the rate of the frequency change (2nd derivative of the spline function) at the beginning of the smear, assuming the same interval over which it's performed, is about 20% smaller, which makes it a bit easier to follow for the clients. With a cubic spline the rate of the frequency change would start at zero, which could be useful to give the clients enough time to shorten their polling intervals at the beginning of the smear and then track faster changes in the frequency later more easily.
Another difference to the Google implementation is that chronyd starts the smear when the leap second (or any other offset) is actually inserted, the time is not precompensated beforehand.
The leap smear can be enabled by adding the following directives to /etc/chrony.conf:
leapsecmode slew
maxslewrate 1000
smoothtime 400 0.001
The first directive tells chronyd to correct the local system clock by slewing on leap second. This is necessary to disable the clock step which would reset the smoothing process. The second directive limits the slewing rate of the local clock to 1000 ppm, which improves the stability of the smoothing process when the local correction starts and ends. The third directive enables the server time smoothing. The frequency offset of the served time is limited to 400 ppm and the frequency will be changing by 0.001 ppm per second.
The 400ppm value is a practical limit for clients using ntpd. It's below the maximum offset of 500 ppm which can be set by ntpd, leaving 100 ppm for the intrinsic frequency offset of the system clock. This limit will not be reached when the leap smear is performed, the frequency offset will get only to about 32 ppm in this case, but it could be reached when smoothing out larger offsets. The whole leap smear in this setting will take about 18 hours with average frequency offset of about 16 ppm. In the first half of that the server time will be gradually slowing down and in the second half it will be speeding up to the correct rate again.
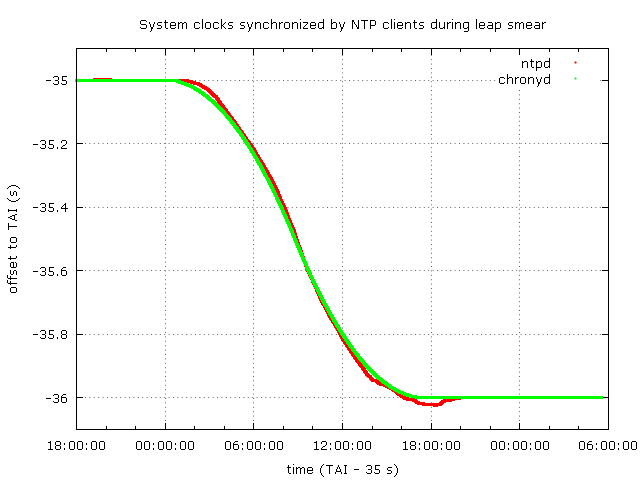
In this graph is shown the offset to TAI of two systems synchronized by ntpd and chronyd in default configurations using a chrony NTP server with leap smear configuration as described previously.
The following two graphs show the frequency offset of the clients' clocks and their offset to the server time as the leap smear is progressing.
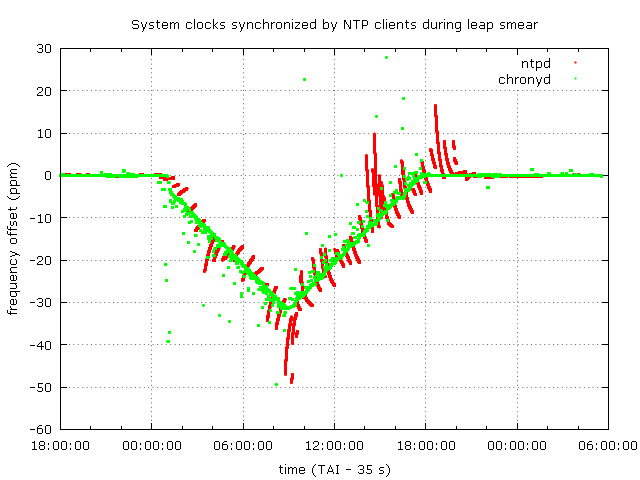
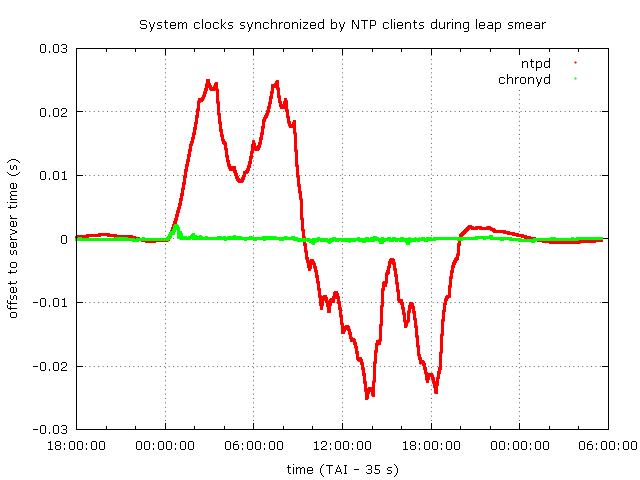
ntpd stays close to the server time within about 25 milliseconds. In the frequency plot it seems to lag significantly behind the server and individual clock updates trying to correct the offset that has accumulated with that frequency error are visible. At the beginning, chronyd is ahead of the server time by about 2 milliseconds before it adapts to the rate of the the frequency change, in the rest of the smear it stays within about 0.5 milliseconds of the server time. The frequency change is tracked very closely and it's easy to see the triangle function in the frequency plot. The offset corrections are quick, visible only as dots in the plot.
The maximum error can be reduced by using a smaller rate of the frequency change on the server, which would make the leap smear longer, or by shortening the client's polling interval. When the maximum polling interval is set to 64 seconds (the maxpoll option is set to 6), ntpd stays below 1.5 milliseconds and chronyd below 0.3 milliseconds.
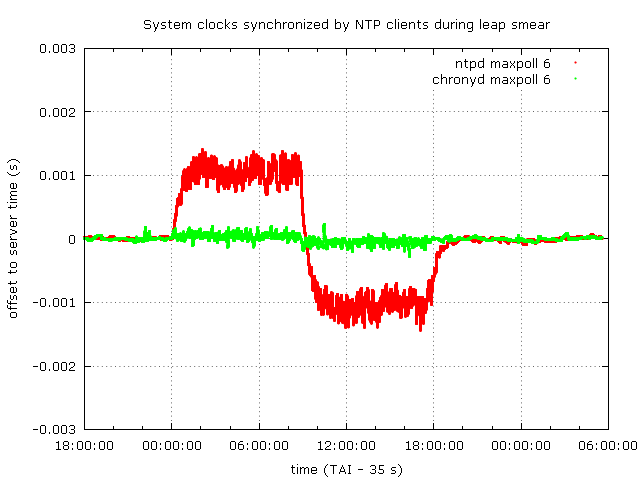
Summary
Which method for correcting the system clock on leap second should you choose? It depends on your applications. It they don't require the system time to be monotonic, use ntpd or chronyd in their default configuration. There will be a backward step, but the clock will be off only for one second. If the time must be monotonic and the requirements on its accuracy are not very strict, you can use ntpd with the -x option to slew the clock instead. With chronyd you can set the leapsecmode option set to slew. If there is also a requirement to keep the clocks on multiple systems close to each other, consider using chronyd configured with a smaller maximum slew rate. If that is not an option, you can run your own leap smearing NTP server with chronyd, but be careful to not mix it with other servers.