Overview: Using projects in Red Hat OpenShift Data Science

Red Hat OpenShift Data Science is a platform for data scientists and developers of artificial intelligence (AI) applications. It provides a fully supported environment that lets you rapidly develop, train, test, and deploy machine learning models on-premises and/or in the public cloud. OpenShift Data Science is provided as a managed cloud service add-on to the OpenShift cloud services or as self-managed software that you can install on-premise or in the public cloud on OpenShift.
In this learning path, you will create and set up options for your data science project from the Red Hat OpenShift Data Science dashboard. If you can’t remember how to launch OpenShift Data Science, go back to the Launch Red Hat OpenShift Data Science learning path.
Create and configure your data science project
Navigate to the Red Hat OpenShift Data Science dashboard (Figure 1) to create a data science project and configure its options. Select the Data Science Projects menu item highlighted in Figure 1.
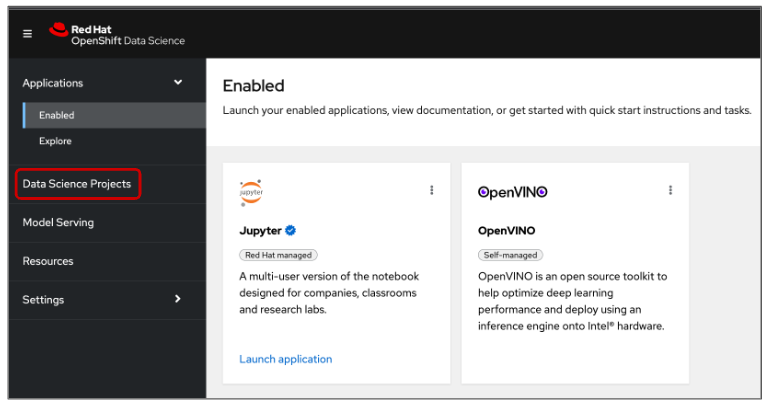
If you have any existing projects, they will be displayed. In the example shown in Figure 2, we have two projects: edge-robotics and stretchy. If you click on the three dots to the far right of the project name, you will see the option to either edit or delete the project. (Figure 2)
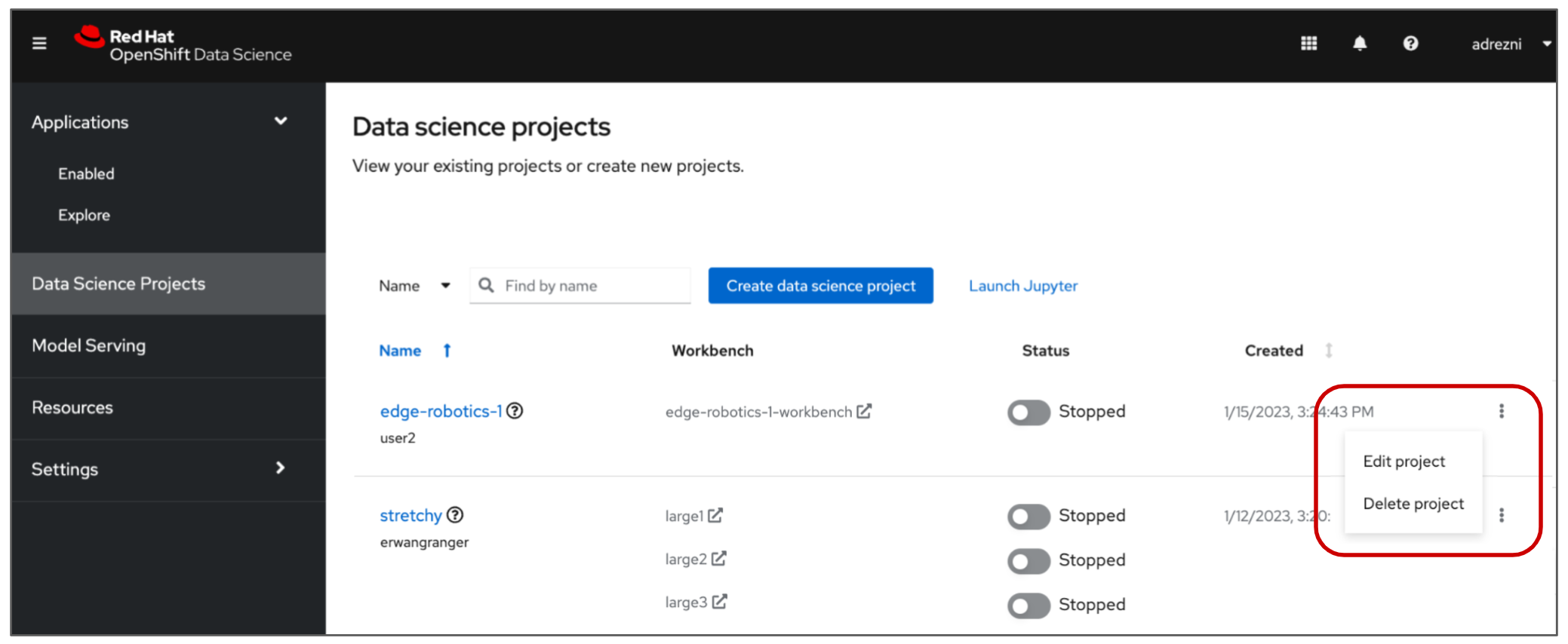
Create a new project by clicking the Create data science project button. (Figure 3)

In the Create data science project pop-up window, as shown in Figure 4, enter a name for your project.
Resource names are how your resources are labeled in OpenShift. The resource name field populates automatically based on the project name you just entered. You can modify this if desired.
Note: It is not possible to edit a resource name after a project is created.
Although not required, adding a description for your project is a good idea, especially if you work with multiple projects and team members.

Click Create. This brings you to your new data science project’s details page, as shown in Figure 5.
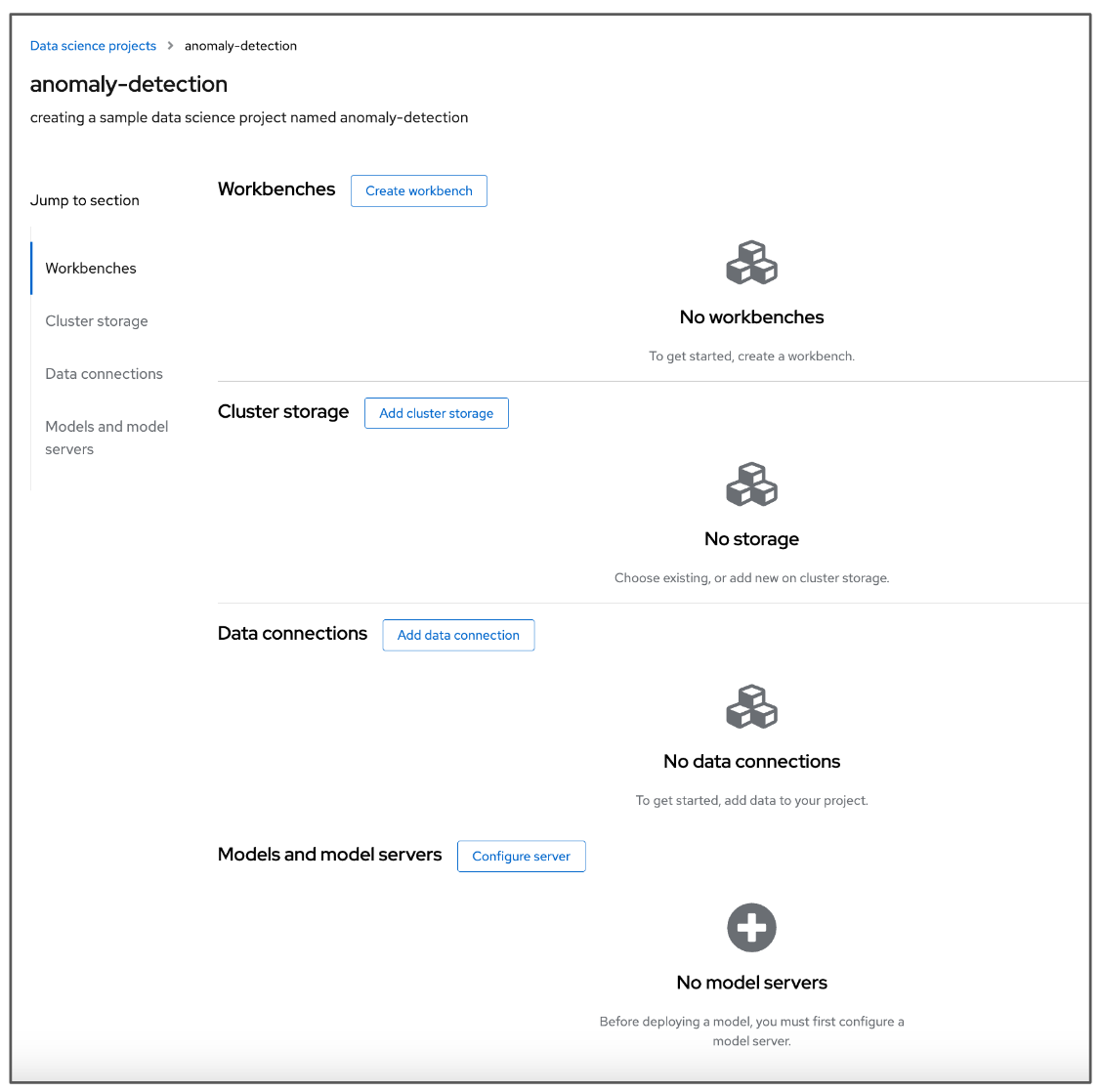
Within the data science project, you can add the following configuration options:
- Workbenches: Development environments within your project where you can access notebooks and generate models.
- Cluster storage: Storage for your project in your OpenShift cluster.
- Data connections: A list of data sources that your project uses.
- Models and model servers: A list of models and model servers that your project uses.
As you can see in Figure 5, our example data science project currently has no workbenches, storage, data connections, or model servers. Let’s add these items next.
