
Figure 13: The configuration reflects the custom data in my_input.csv under data/input.
Page

Replicating the experiments with custom data is super easy. Upload your new data and update the configuration to point to your data. For example, assume that you have data in a comma-separated values (CSV) file named my_input.csv. Upload that file to the my_input.csv folder, then update the value for input in the [Data] section of the configuration value. Remember also to increment the version for the current run. The resulting configuration looks like Figure 13.
Then rerun all the notebooks. Results are stored in the experiments/experiment_2 folder (Figure 14).

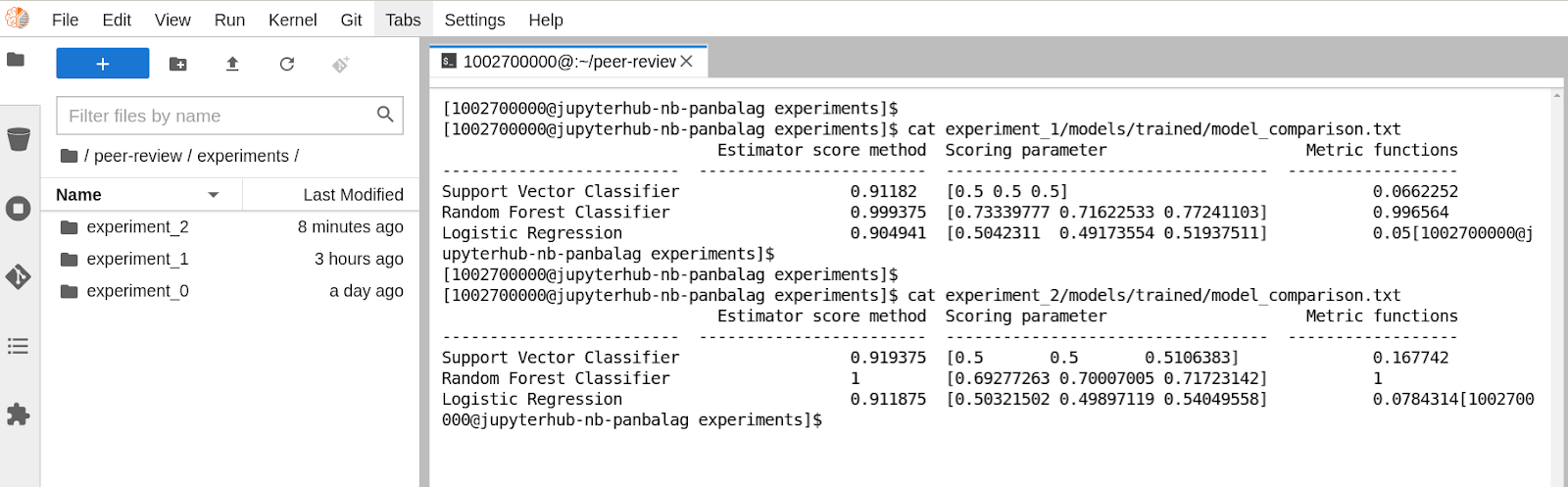
Now you can compare your results against the published version. Figure 15 compares the results of the trained models from both runs.

Build here. Go anywhere.
We serve the builders. The problem solvers who create careers with code.
Join us if you’re a developer, software engineer, web designer, front-end designer, UX designer, computer scientist, architect, tester, product manager, project manager or team lead.