Overview: Model serving in RHODS
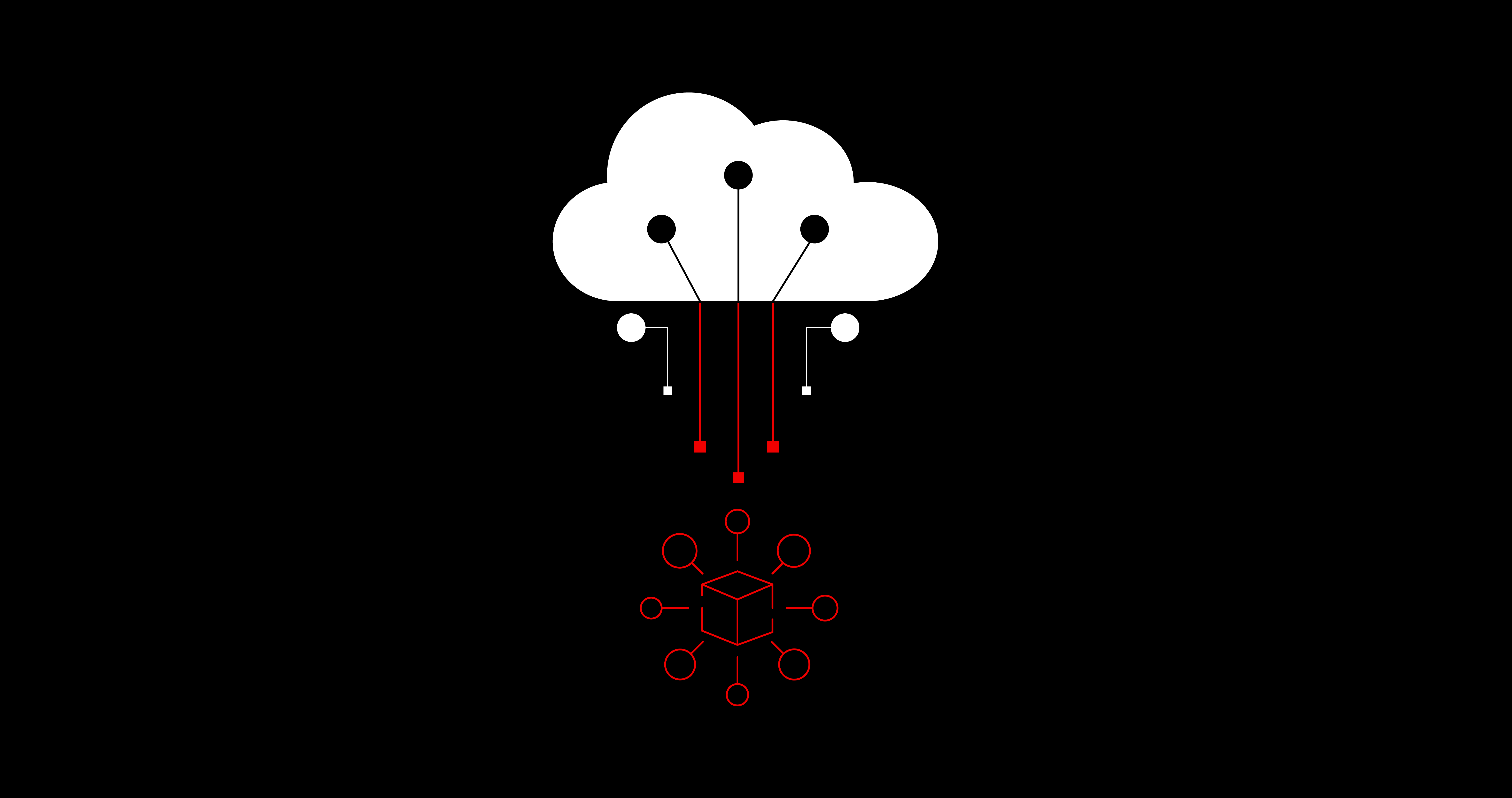
Prerequisites
You must have already created a Data Science Project inside your OpenShift Data Science environment. If you can’t remember how to create this project, go back to the Using projects in Red Hat OpenShift Data Science learning path.
You must have a machine learning model saved in one of these two supported formats:
- ONNX: An open standard for machine learning interoperability.
- OpenVino IR: The proprietary model format of OpenVINO, the model serving runtime used in OpenShift Data Science.
The model file(s) should have been saved into an S3-compatible object storage bucket (OpenShift Data Foundation, AWS S3) for which you must have the connection information, such as location and credentials.
Create a data connection
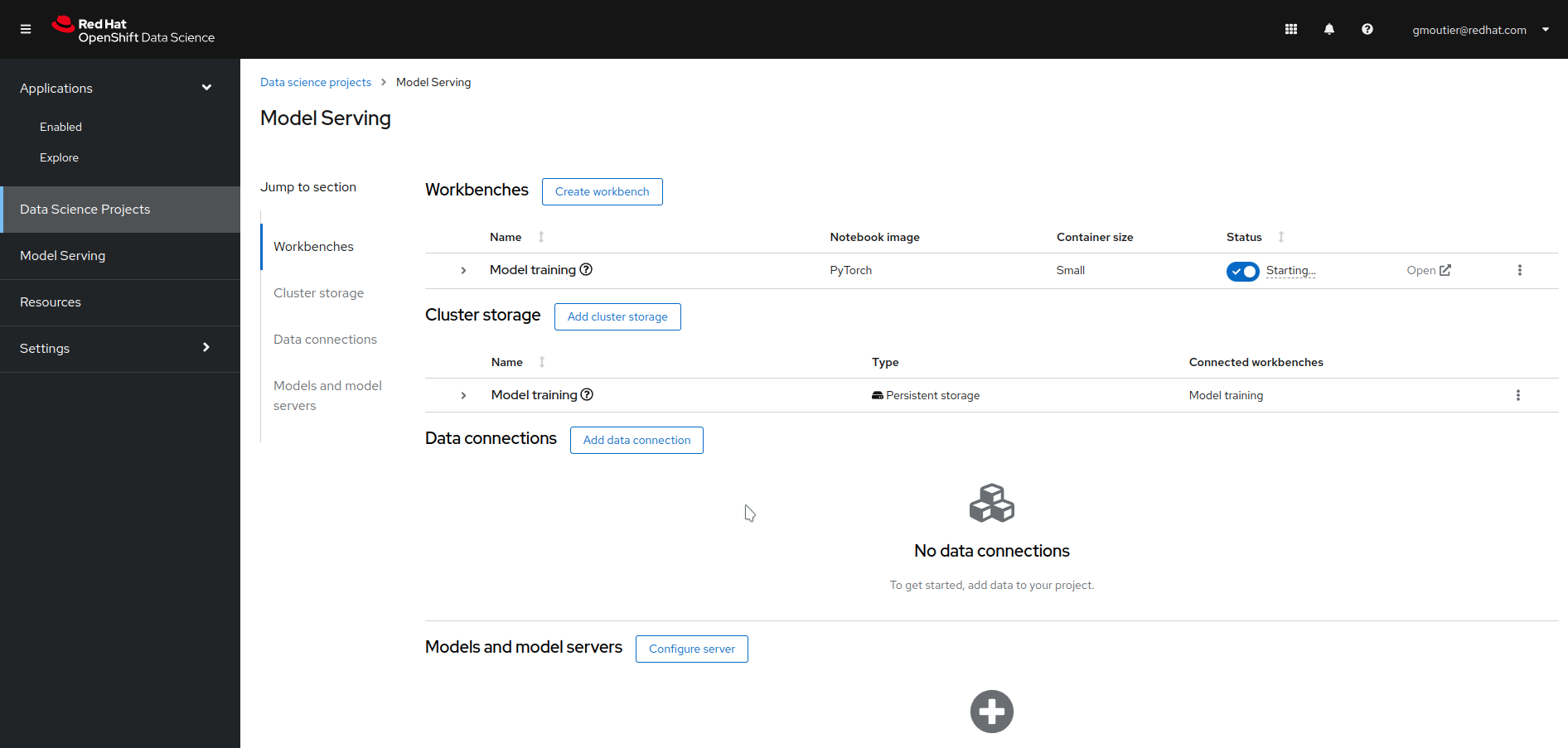
Navigate to the Red Hat OpenShift Data Science dashboard and select your Data Science Projects (Figure 1).
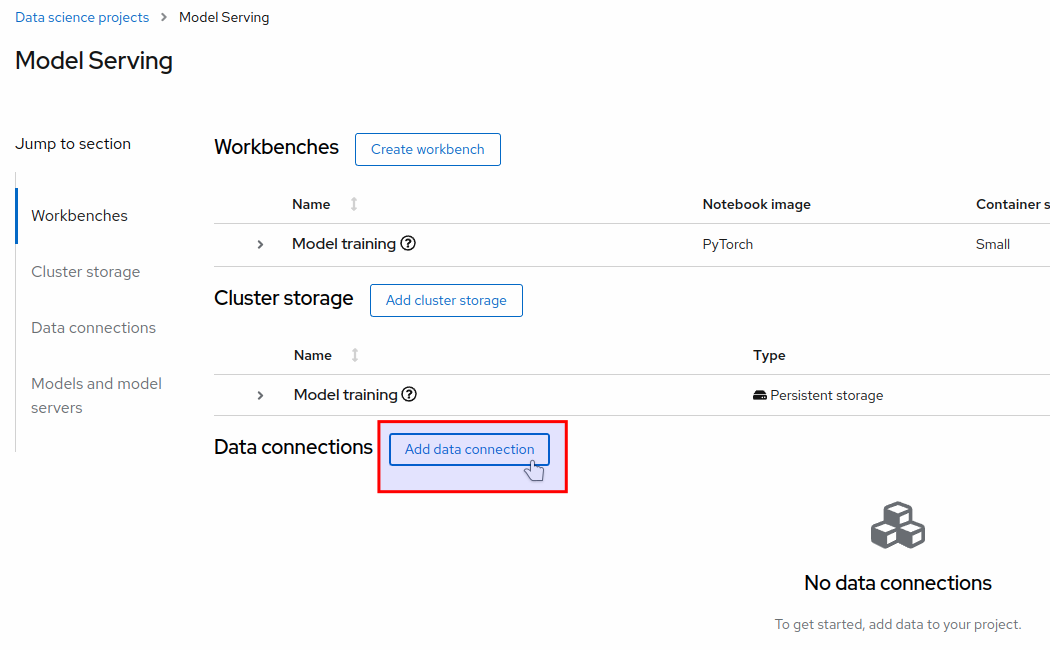
In the Data connections section, click on Add data connection (Figure 2).
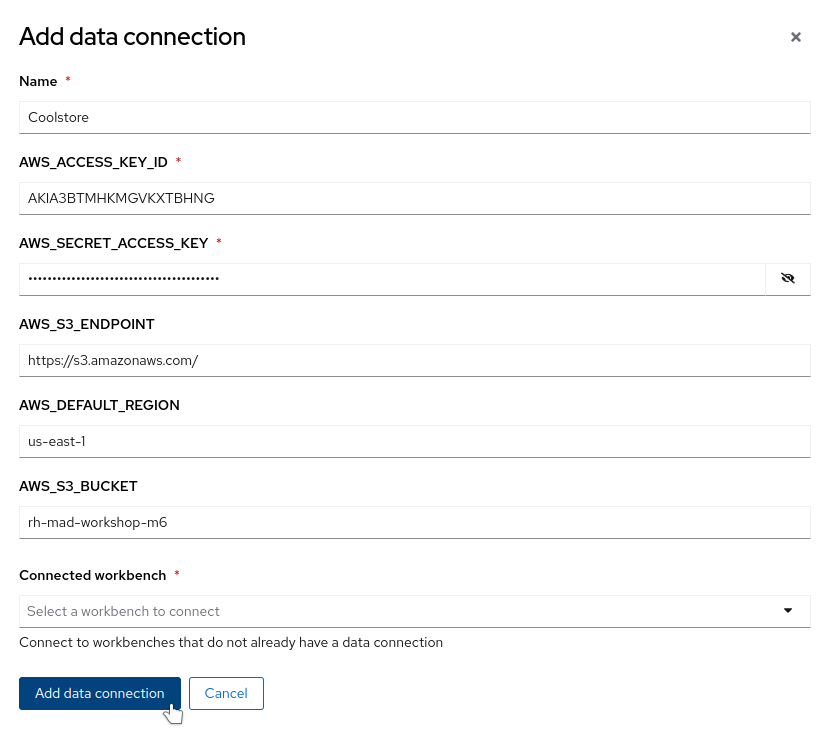
In the Add data connection window, enter the information about the S3-compatible object bucket where the model is stored. Enter the following information:
- The name you want to give to the data connection (in this example, “Coolstore”).
- The access key to the bucket: AWS_ACCESS_KEY_ID.
- The secret for the access key: AWS_SECRET_ACCESS_KEY.
- The endpoint to connect to the storage: AWS_S3_ENDPOINT.
- The region to connect to the storage: AWS_DEFAULT_REGION.
- The name of the bucket: AWS_S3_BUCKET.
When your information is entered, click on Add data connection (Figure 3).
Note: The name of the variables for the access key, the secret, starts with an AWS prefix because this is the standard naming convention for most tools used to interact with S3-Compatible storage. However, you are not required to use the S3 service from Amazon Web Services (AWS). Any S3-compatible storage is supported.
Your data connection is now ready to use (Figure 4).

