Overview: How to set up and reproduce data science experiments
Red Hat OpenShift Data Science is a managed cloud service for data scientists and developers of artificial intelligence (AI) applications. It provides a fully supported environment in which to rapidly develop, train, and test machine learning models in the public cloud before deploying them in production. When you use OpenShift Data Science, you are running in Red Hat OpenShift Dedicated or Red Hat OpenShift Service on AWS, which simplifies cloud operations.
In this learning path, you will set up options for your Jupyter notebook server. If you cannot remember how to launch JupyterHub, go back to the Launch JupyterHub learning path.
Select options for your notebook server
When you first gain access to JupyterHub, a configuration screen (Figure 1) gives you the opportunity to select a notebook image and configure the deployment size and environment variables for your data science project.
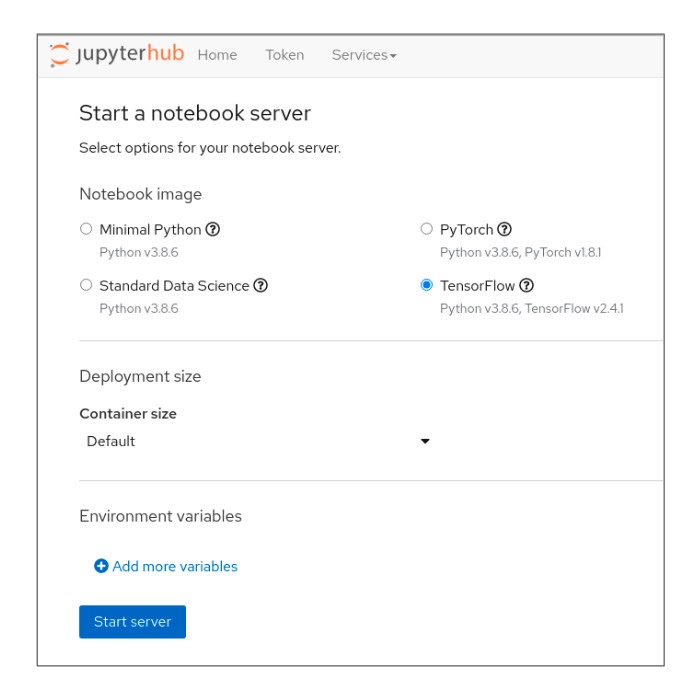
You can customize the following options:
- Notebook image
- Deployment size
- Environment variables
The following subsections walk through the prerequisites you need to choose for this activity.
Notebook image
There are a number of predefined images that you can choose from. When you choose a predefined image, your JupyterLab instance has the associated libraries and packages that you need to do your work.
Available notebook images include:
- Minimal Python
- PyTorch
- Standard Data Science
- Tensorflow
For this learning path, choose the Tensorflow notebook image.
Deployment size
You can choose different deployment sizes (resource settings) based on the type of data analysis and machine learning code you are working on. Each deployment size is pre-configured with specific CPU and memory resources.
For this learning path, select the Small deployment size.
Environment variables
The environment variables section is useful for injecting dynamic information that you don't want to save in your notebook.
This learning path does not use any environment variables.
Once you are satisfied with your notebook server selections, click the Start Server button to start the notebook server. A dialog box saying “Starting Server” will appear (see Figure 2). After you see the “Success” message (Figure 3), you will be transferred to your JupyterLab instance shortly.

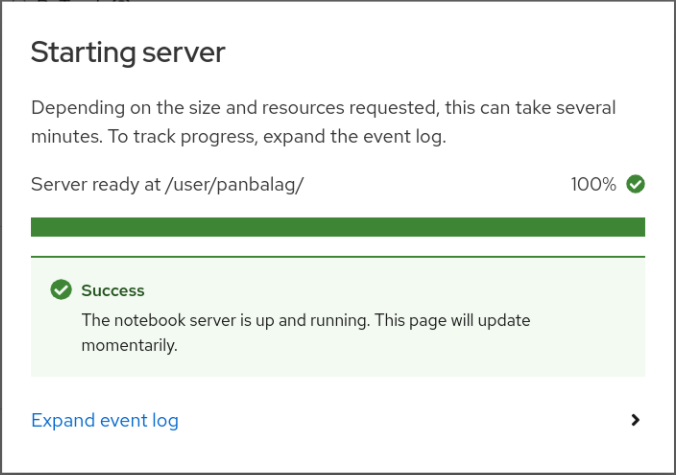
If this procedure is successful, you have started your Jupyter notebook server.
