Developing Operators

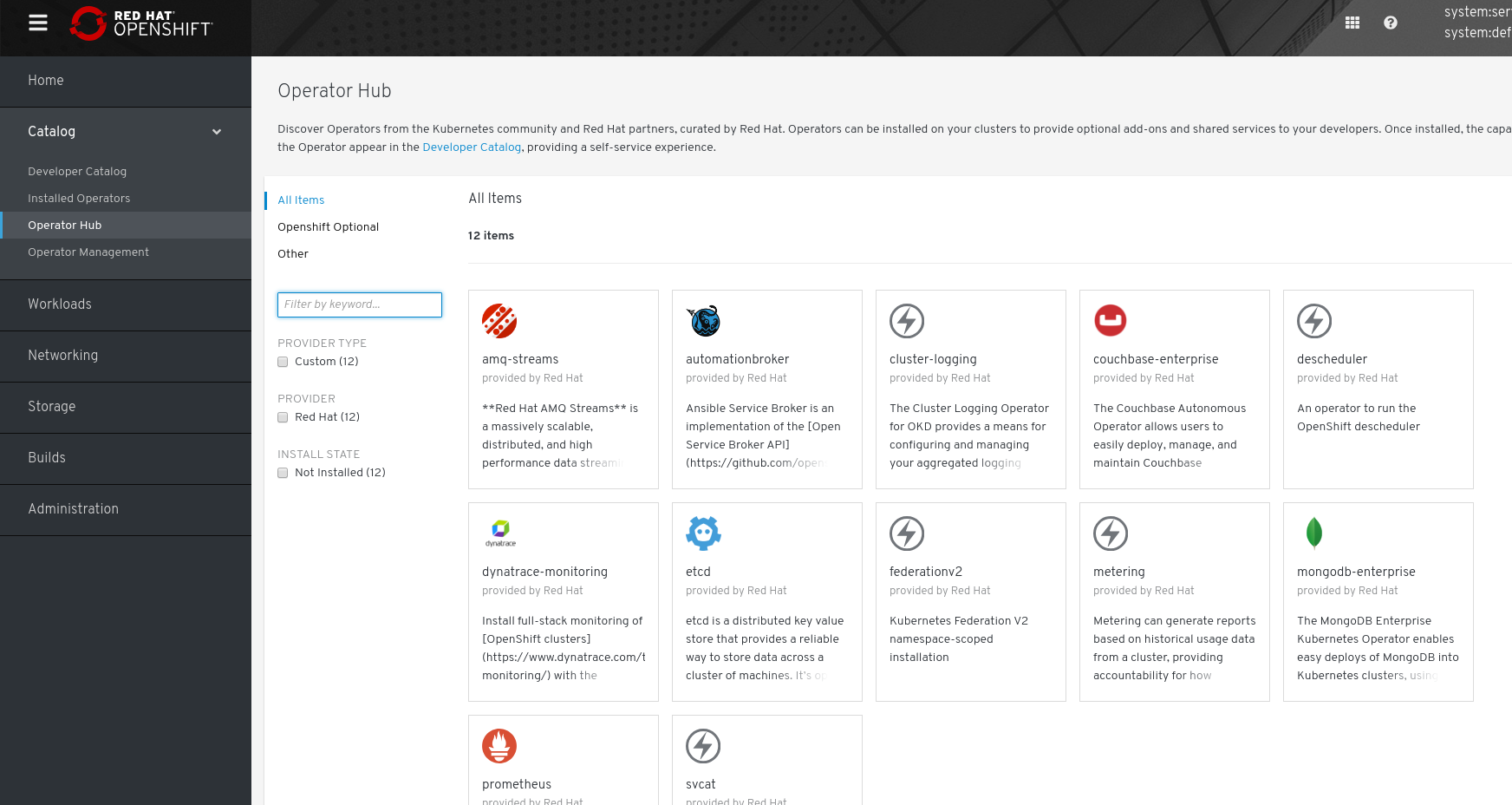
Operators give you a convenient way to package, deploy, manage and distribute applications for Kubernetes. The method allows you to package configuration so that users can deploy operators from a simple catalog without having to engage administrators. You can distribute operators beyond your organization using OperatorHub.io which is open to all contributions or the Red Hat OpenShift OperatorHub using Red Hat's certification process.