APIs are critical to automation, integration and developing cloud-native applications, and it's vital they can be scaled to meet the demands of your user-base. In this article, we'll create a database-backed REST API based on the Python Falcon framework using Red Hat Software Collections (RHSCL), test how it performs, and scale-out in response to a growing user-base.
We're going to use the following components to build and test our API:
Why Falcon?
Falcon is a minimalist framework for building web APIs, and according to the Falcon website, it can achieve a 10x speedup over Flask. Falcon is fast!
Getting started
For this article, I'm assuming you have access to a Red Hat Enterprise Linux subscription. If you don't have a subscription already, you can get a No-Cost Developer Subscription.
Firstly, let's setup the database with RHSCL. Install the 'rh-postgresql95' and 'scl-utils' packages and initialize the database:
# yum install rh-postgresql95 scl-utils # scl enable rh-postgresql95 bash # postgresql-setup --initdb # systemctl start rh-postgresql95-postgresql
Let's create a database and a user:
# su - postgres -c 'scl enable rh-postgresql95 -- createdb orgdb' # su - postgres -c 'scl enable rh-postgresql95 -- createuser --interactive orguser --pwprompt'
Edit the pg_hba.conf file to allow the user access to the db:
# cat /var/opt/rh/rh-postgresql95/lib/pgsql/data/pg_hba.conf ... # TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all peer host orgdb orguser 127.0.0.1/32 md5 host all all 127.0.0.1/32 ident
Restart the postgresql service
# systemctl restart rh-postgresql95-postgresql
Grant the user access to the new db:
# su - postgres $ scl enable rh-postgresql95 bash $ psql psql (9.5.4) Type "help" for help. postgres=# grant all privileges on database orgdb to orguser; GRANT
Now that we have a database configured, let's build our Falcon application.
Create the API
We're going to use Python3.5 for our application. While Python 2 is still generally faster, it doesn't outweigh the significant improvements we get in Python 3. You can see detailed benchmark comparisons between Python versions at https://speed.python.org/
Start by enabling the RHSCL repository and installing rh-python35
$ sudo subscription-manager repos --enable rhel-server-rhscl-7-rpms $ sudo yum install rh-python35
You can now enable the RHSCL rh-python35 module and verify the Python version installed:
$ scl enable rh-python35 bash $ python --version python 3.5.1
Now that Python 3.5 is configured, create a file 'app.py' to hold the API:
import falcon
from models import *
from playhouse.shortcuts import model_to_dict
import json
class UserIdResource():
def on_get(self, req, resp, user_id):
try:
user = OrgUser.get(OrgUser.id == user_id)
resp.body = json.dumps(model_to_dict(user))
except OrgUser.DoesNotExist:
resp.status = falcon.HTTP_404
class UserResource():
def on_get(self, req, resp):
users = OrgUser.select().order_by(OrgUser.id)
resp.body = json.dumps([model_to_dict(u) for u in users])
api = falcon.API(middleware=[PeeweeConnectionMiddleware()])
users = UserResource()
users_id = UserIdResource()
api.add_route('/users/', users)
api.add_route('/users/{user_id}', users_id)
Create another file alongside this called 'models.py', and add the following content:
from peewee import * import uuid psql_db = PostgresqlDatabase( 'orgdb', user='orguser', password='orguser', host='127.0.0.1') def init_tables(): psql_db.create_tables([OrgUser], safe=True) def generate_users(num_users): for i in range(num_users): user_name = str(uuid.uuid4())[0:8] OrgUser(username=user_name).save() class PeeweeConnectionMiddleware(object): def process_request(self, req, resp): psql_db.get_conn() class BaseModel(Model): class Meta: database = psql_db class OrgUser(BaseModel): username = CharField(unique=True)
Create a virtualenv and install some requirements for the API:
$ virtualenv ~/falconenv $ source ~/falconenv/bin/activate $ pip install peewee falcon
We've created two helper methods here to setup the application, 'init_tables' and 'generate_users'. Let's run both to initialize the application:
$ python Python 3.5.1 (default, Sep 15 2016, 08:30:32) [GCC 4.8.3 20140911 (Red Hat 4.8.3-9)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from app import * >>> init_tables() >>> generate_users(20)
If you login to the database you will now be able to see the users created:
# su - postgres $ scl enable rh-postgresql95 bash $ psql -d orgdb -U orguser -h 127.0.0.1 psql (9.5.4) Type "help" for help. orgdb=> select * from orguser; id | username ----+---------- 1 | e60202a4 2 | e780bdd4 3 | cb29132d 4 | 4016c71b 5 | e0d5deba 6 | e835ae28 7 | 952ba94f 8 | 8b03499e 9 | b72a0e55 10 | ad782bb8 11 | ec832c5f 12 | f59f2dec 13 | 82d7149d 14 | 870f486d 15 | 6cdb6651 16 | 45a09079 17 | 612397f6 18 | 901c2ab6 19 | 59d86f87 20 | 1bbbae00 (20 rows)
You can now test out the API:
$ gunicorn app:api -b 0.0.0.0:8000
[2017-12-11 23:19:40 +1100] [23493] [INFO] Starting gunicorn 19.7.1
[2017-12-11 23:19:40 +1100] [23493] [INFO] Listening at: http://0.0.0.0:8000 (23493)
[2017-12-11 23:19:40 +1100] [23493] [INFO] Using worker: sync
[2017-12-11 23:19:40 +1100] [23496] [INFO] Booting worker with pid: 23496
$ curl http://localhost:8000/users
[{"username": "e60202a4", "id": 1}, {"username": "e780bdd4", "id": 2}, {"username": "cb29132d", "id": 3}, {"username": "4016c71b", "id": 4}, {"username": "e0d5deba", "id": 5}, {"username": "e835ae28", "id": 6}, {"username": "952ba94f", "id": 7}, {"username": "8b03499e", "id": 8}, {"username": "b72a0e55", "id": 9}, {"username": "ad782bb8", "id": 10}, {"username": "ec832c5f", "id": 11}, {"username": "f59f2dec", "id": 12}, {"username": "82d7149d", "id": 13}, {"username": "870f486d", "id": 14}, {"username": "6cdb6651", "id": 15}, {"username": "45a09079", "id": 16}, {"username": "612397f6", "id": 17}, {"username": "901c2ab6", "id": 18}, {"username": "59d86f87", "id": 19}, {"username": "1bbbae00", "id": 20}]
So how did we do?
Let's test how our API performs with Taurus. If possible, deploy Taurus to another server separate to your Falcon API (I'm running Taurus on an Intel NUC).
Let's get some dependencies for Taurus first:
$ sudo yum install java-1.8.0-openjdk-headless python-devel libxml2-devel libxslt-devel zlib gcc
Install Taurus in our virtualenv. If you're running Taurus on a separate server, create a new virtualenv for Taurus first:
$ pip install bzt
Now we can create a scenario for our tests. Create a file 'bzt-config.yml' and add the following contents (substitute ip-addr for your server IP address):
execution: concurrency: 100 hold-for: 2m30s ramp-up: 1m scenario: requests: - url: http://ip-addr:8000/users/ method: GET label: api timeout: 3s
This test will simulate web traffic ramping up to 100 users over the course of a minute, and hold at 100 users for 2m30s.
Let's start our API with a single worker:
$ gunicorn --workers 1 app:api -b 0.0.0.0:8000
We can now run Taurus. The first time that you run Taurus it will download required dependencies, which can take some time:
$ bzt bzt-config.yml -report 20:02:18 INFO: Taurus CLI Tool v1.10.3 20:02:18 INFO: Starting with configs: ['bzt-config.yml'] 20:02:18 INFO: No personal config found, creating one at /home/user/.bzt-rc 20:02:18 INFO: Configuring... 20:02:18 INFO: Artifacts dir: /home/user/Documents/python-ws/coffee-api/2017-12-11_20-02-18.732736 20:02:18 INFO: Preparing... 20:02:18 INFO: Will install JMeter into /home/user/.bzt/jmeter-taurus/3.3 20:02:21 INFO: Downloading: https://archive.apache.org/dist/jmeter/binaries/apache-jmeter-3.3.zip
Once all dependencies are installed, you will be represented with a console showing your current testing run:
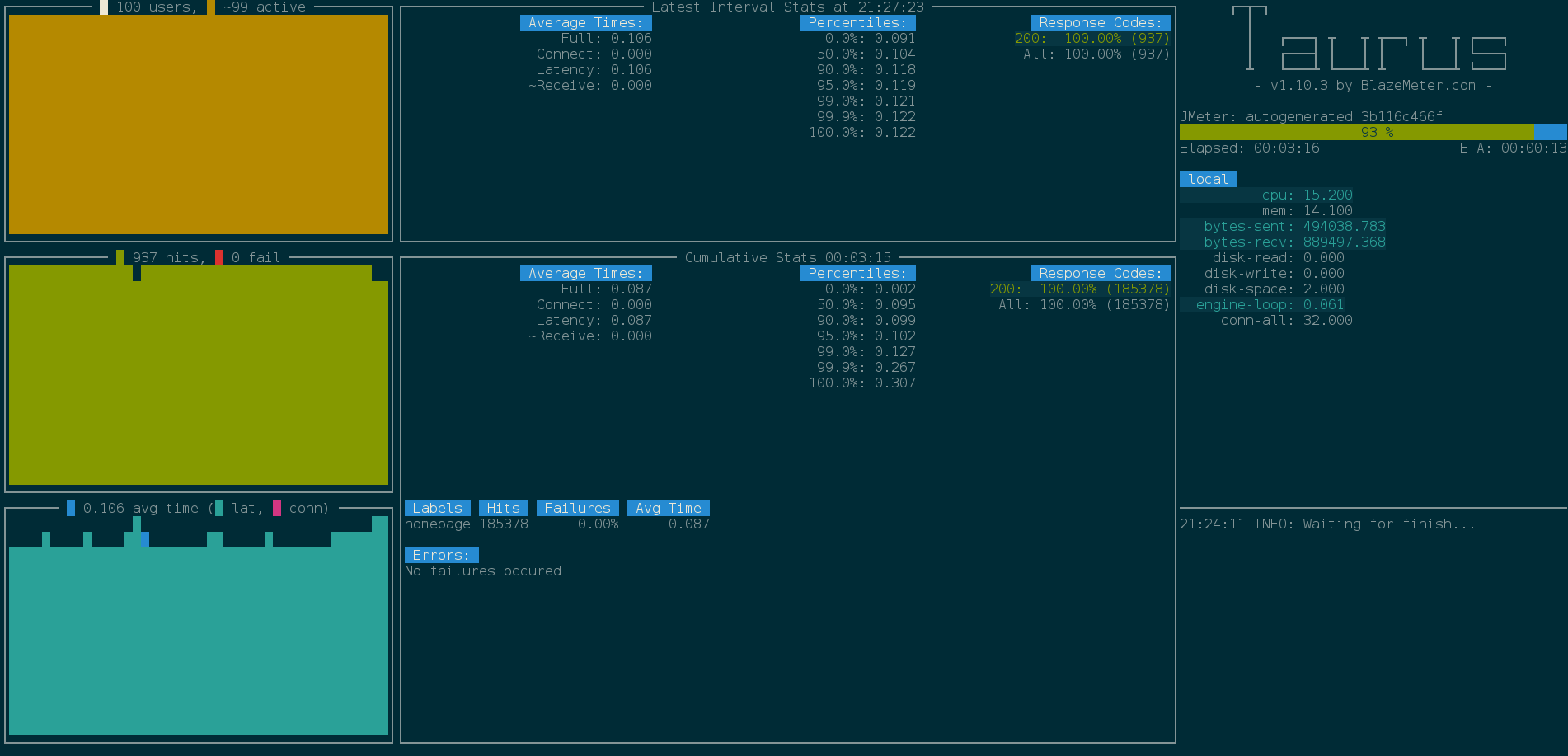
We're using using the '-report' option to upload the results to BlazeMeter and generate a web report. You are presented with the web-link at the end of the test run:
21:55:28 INFO: Ending data feeding... 21:55:29 INFO: Online report link: https://a.blazemeter.com/app/?public-token=iJlTHW5tceTBMwo7AZBR7A13Xe5dWXUPf2gRQN9OTz8mDvKNcR#reports/r-ext-5a2e63444b019/summary 21:55:29 INFO: Artifacts dir: /home/user/bzt/2017-12-11_21-51-43.083367 21:55:29 INFO: Done performing with code: 0
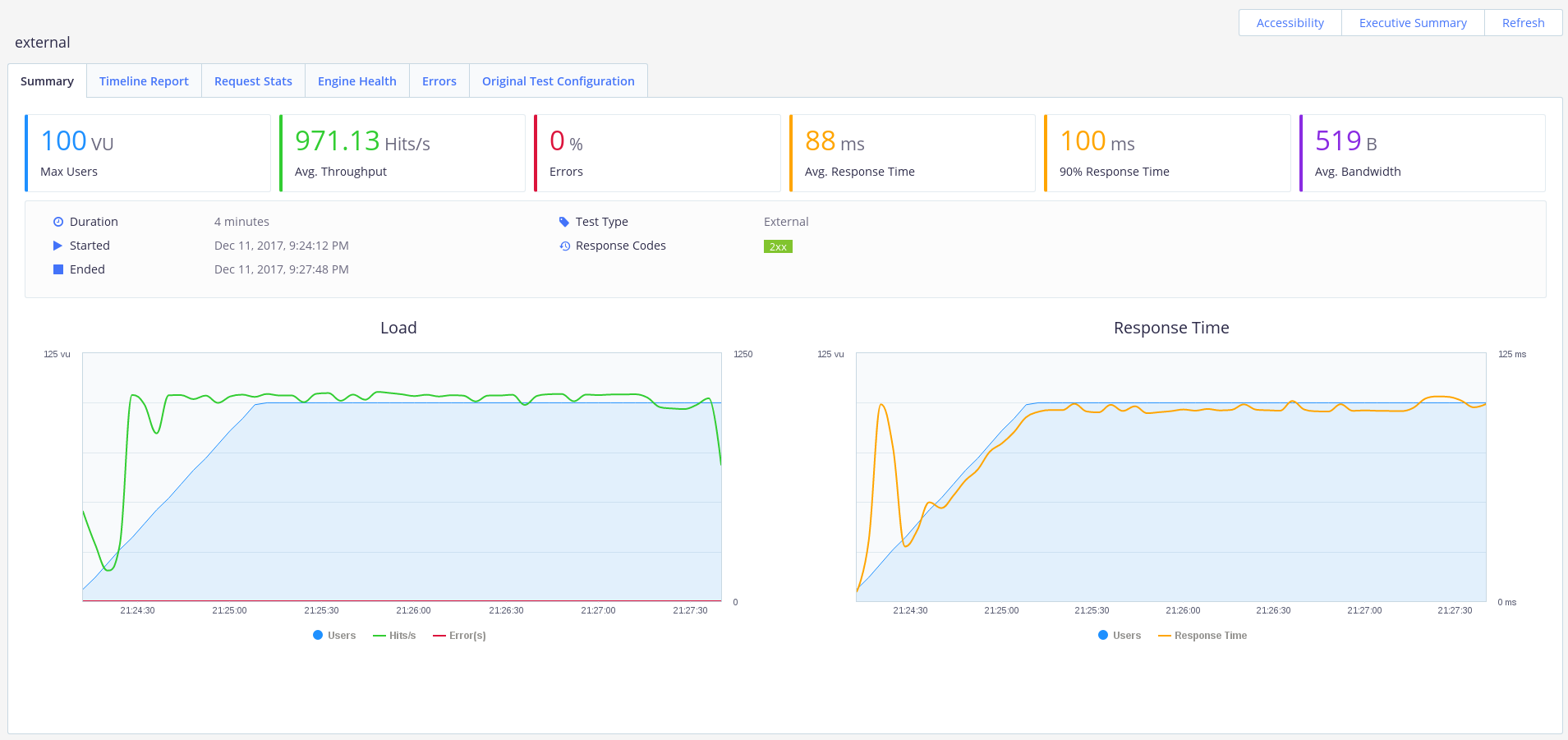
Our API performed pretty well with 100 users. We achieved a throughput of ~1000 requests/second, with no errors and an average response time of 0.1s.
Ok, now how about 500 users? Update the 'concurrency' value to 500 in your 'bzt-config.yml' file and re-run Taurus.
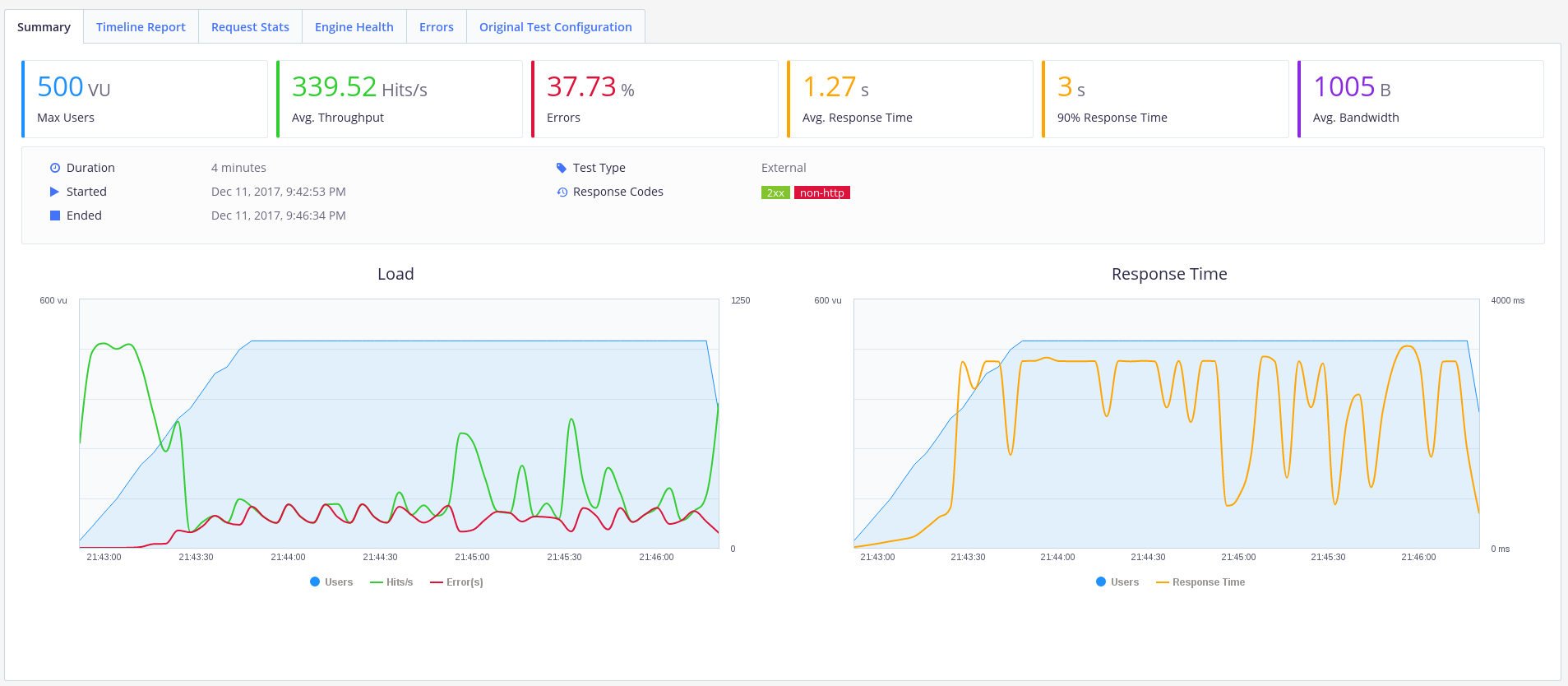
Hmm. Well, unfortunately it looks like our solo-worker API has collapsed into a smoldering heap. We're still processing requests, but with a 40% error-rate I don't think anyone will be using this API for long.
Let's try scaling up the Falcon workers:
gunicorn --workers 20 app:api -b 0.0.0.0:8000
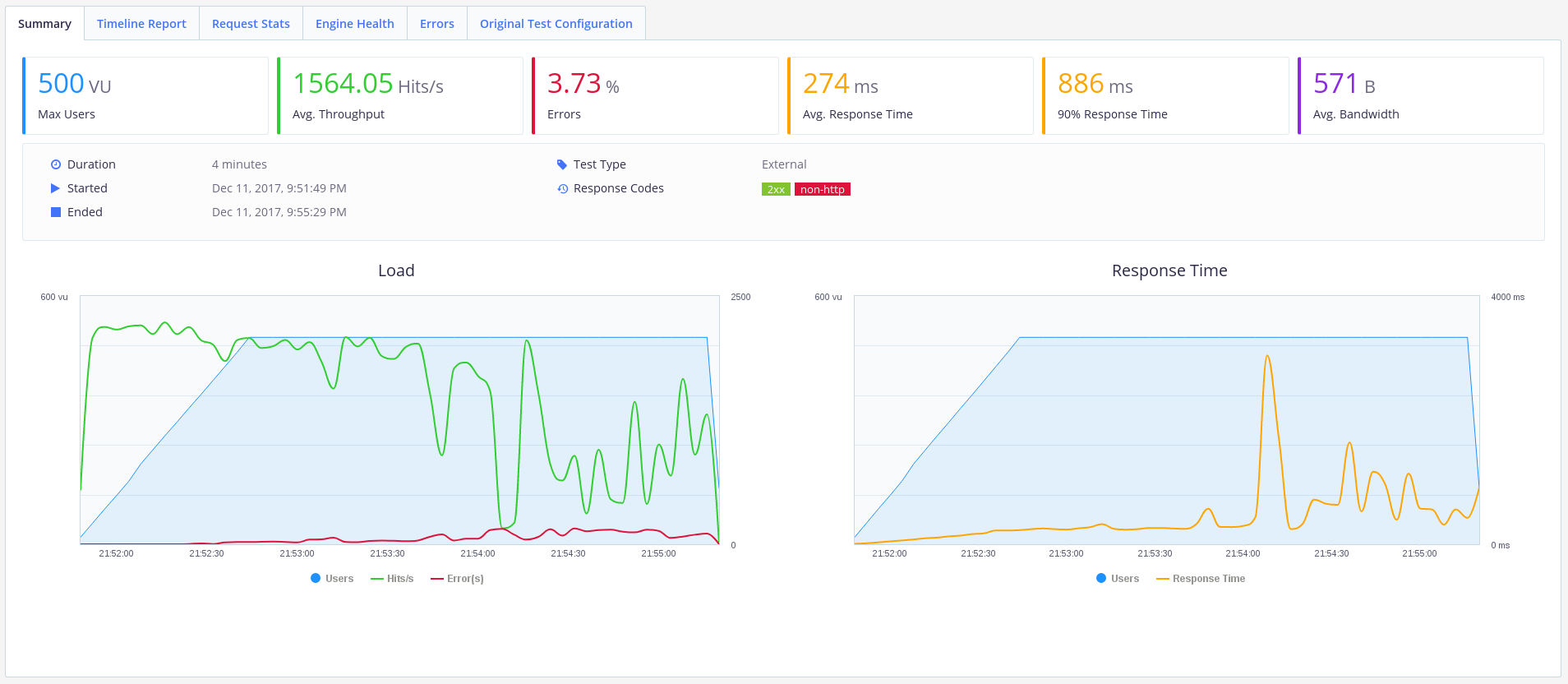
Ok - that looks better. We've still got a pretty-high error rate, but we've upped the throughput to ~1500 requests/second, and kept the average response time down to ~270ms. I'd say this API is now usable, with a little blip when the load-average on my laptop spiked.
Further Performance Tuning
We still have a high error rate, and could certainly bring the average response time down, and there are a few other things we could do to tune our API for performance:
- Use PgTune to configure PostgreSQL settings for our hardware
- Deploy our API to OpenShift and scale-out pods to meet demand
That's it for this API. Thanks for reading!
Take advantage of your Red Hat Developers membership and download RHEL today at no cost.
Last updated: November 1, 2023