To the best of my knowledge the Gnu Compiler Collection (GCC) never enforced a formal organization for header files. They were created as desired to export elements of a source file, and over time became convenient places to put lots of miscellaneous things. No one seemed to think we needed to dictate what they should contain, nor how they should be included. For the most part it never really mattered... A source file included whatever list of headers it required to compile, and reorganization was rare.
So why does it matter now? The header file “tree.h” defines the most ubiquitous data structure in GCC... the tree_node. Most core objects are a tree_node of some sort... identifiers, expressions, types, variables, lists... you name it, it's rooted in a tree_node. As part of a project to help modernize the code base, I wanted to split this tree_node so that types became a new type_node. Then I wanted to create a type_node for the compiler's optimizers that did not share the implementation used by the language parsers. I needed to be able to pull a few of these data structures apart.
I also knew the header files were quite unorganized, and when I went to prototype my changes I discovered the terrible truth... There were so many unrelated header files intertwined with tree.h that it was virtually impossible to separate anything, let alone the significant parts I wanted. I could feel the header-ache beginning...
Where to start.
And so began a project to fix the header file situation so I could proceed with the project I actually wanted to work on. After quite some time dealing with this, I have become a firm believer that a project really should enforce some sort of rules regarding header files. They don't have to be these specific rules, but there ought to be some basic rules. The methodology I used to fix GCC's header structure should be applicable to any other legacy code base that has similar issues.
I started by analyzing the included file structure... I struggle here to find a file whose graph of included header files was simple enough to reasonably fit on a page:
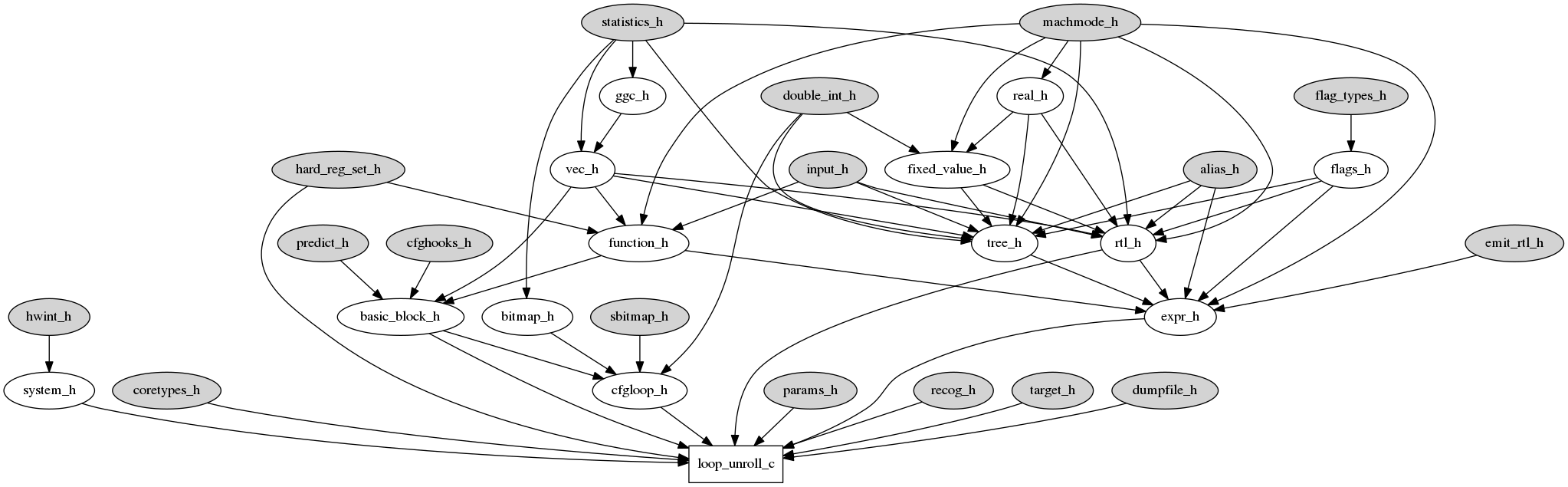
That is a single source file at the bottom, and each arrow tail represents a header that is included at the head of the arrow. This is a very simple sample of what it looked like in the beginning. There were also header file cycles and other terrors, and most of the other 600 or so source files looked far worse than this. The overall graph of the project was so dense it appeared as a solid black ball and was quite useless.
I proceeded to get a consensus from the major stakeholders that we would apply a few simple rules to get to our desired state:
- Each source file (file.c) should have a header file (file.h) which defines what the source file exports... data structures, prototypes, etc. It will contain only information for this specific source file.
- Each file will include only what it needs. I've also seen this referred to as “Include What You Use”.
- Module headers can be created to include groups of related headers for convenience, but there will be no associated source file.
Of course, the real trick is getting from here to there isn't it. I decided the only reasonable way to proceed was to tear the current situation apart completely, and rebuild it from the ground up. This becomes a 3 phase process:
Phase 1 - Flattening
The goal in phase 1 is to eventually reach the point where no header file includes any other header file. It is a harsh thing to enforce, but it means each source file includes every header it uses directly. This way nothing gets hidden or brought in indirectly. In a later phase this can be rebuilt into something more sane.
This phase is involves “flattening” each header. The list of includes are moved from the header to immediately before every location the header is included from. Ie: if c-common.h starts with:
#include "splay-tree.h" #include "cpplib.h" #include "alias.h" #include "tree.h" #include "fold-const.h" <...> rest of file
Those are removed from c-common.h, and every place which includes c-common.h has that list pre-pended just before it is included:
#include "splay-tree.h" #include "cpplib.h" #include "alias.h" #include "tree.h" #include "fold-const.h" #include “c-common.h”
This maintains the integrity of prerequisites and ensures the source files and the header will still see the same sequence of declarations. This is done everywhere, even into other header files. Those headers will eventually get this same treatment.
Once this change is confirmed to build, the header file is modified to obey the first rule. The list of exported prototypes and data-structures are updated to reflect what is in the corresponding source file. Any exports which are currently found in other header files are moved here, and any that are appear here but which do not originate in the source file are moved to a more appropriate header. This can also involve shuffling of routines and data that really belong elsewhere, but that becomes even more involved.
This is carried out on every source/header file combination until there are no remaining headers included by non-source files.
Phase 2 - Minimize inclusions
Now that the header files are fully flattened and representative of their source file, its possible to figure out what each source file now requires. At this point, every source file has a substantial list of included header files which needs to be reduced. I developed a set of tools (which can be found in gcc's “contrib/header-tools” directory) to help automate this process. There is a basic README for the tools there.
The tools process each individual source file. Header files are removed one at a time (working from last to first) and an attempt is made to build and integrate the object. If this is successful, then the header is deemed unnecessary and removed. If the build fails, the header file is left in the source file.
This results in a set of source files which include only the header files they need to compile. This is not a state you want to leave things in however.
Phase 3 - Rebuild and Restructure
The final phase is to rebuild a sensible header structure, starting with recognizing that some header files have firm prerequisites. For instance, “tree.h” uses the hash_table structure, and simply won't compile without “hash-table.h” somewhere earlier in the include chain. To assist, I had the tool which removed header files generate logs. The output from failed builds was analyzed to determine prerequisites such as this (dependency graphs between headers were generated for visualization).
The way forward becomes less well defined at this point, and personal preferences can take over. The straightforward approach is to include “hash-table.h” in “tree.h” since it is a hard requirement. The only drawback to this approach is if there are 25 header files which have this same requirement, "hash-table.h" could be included 25 times. That's not really a huge deal in this day and age, but it is also where creating module (or aggregating) headers can come in handy.
Examining usage patterns indicated that there were groups of files that were commonly needed everywhere. Some files, such as “hash-table.h”, were so prevalent I moved them to a common header that every gcc file includes. This eliminated the need to include it in the other 25 files, as it can be expected to be present already. In fact, there were 11 header files which fell into this category and are now included in “coretypes.h”.
A second category of headers were observed that were needed by the vast majority of the source files which make up the optimizer and code generating backend component. A new file “backend.h” was created which does nothing but include those header files, and all backend files now include this component header.
And so on. The basic guideline is that a header file either directly includes a prerequisite header, or the prerequisite is included via some module header that any source file promises to include earlier in the chain.
The end result is an organized include structure containing source files which only include what they need, and header files that are rarely included more than once. That original dependency graph I showed earlier is more organized and now looks like this:

Trying to work with one of those header files is much easier now. It was also interesting to see the patterns of usage that emerged when the process was complete. One of our header files, "alias.h" had been included in something like 500 source files. After all the reductions, it is now used in just 35 files. That's about a 93% reduction! There were a lot of others that were significantly reduced as well, just not quite to that degree.
Reality is a bear
Of course, the devil is in the details. There were lots of complications along the way. With a project as large as GCC, the first phase was tedious and time consuming. Many source files had no header file at all - their exports had been put in other headers that acted as catch-alls. The effort of creating these new headers, integrating them into the build, and going through the catch-all headers and their source files to straighten this out took far longer than I ever imagined. In the end it actually took place part-time over 3 development/release cycles (2+ years) . There were some contributors that were unhappy with the pain of having to find any prerequisites for headers as things were slowly flattened, but we somehow all survived.
Not all header files are included at the top of a file either. In source files it wasn't such a big deal, but for the most part I had to ignore (or treat specially) headers that were included in the middle of other header files. The flattening process depends on the sequence from the source file exactly replacing the start of a header file. When this changes, there can be subtle changes in meaning within the file, and chaos can ensue. This can also be very difficult to track down. I have the scars to prove it. Fortunately, those were quite rare and usually had very specific reasons not to touch them..
The intent was also to intermingle the first and second phase a bit so it wouldn't inconvenience developers too much. It took an unexpectedly long time to get the tools working correctly for phase 2. GCC makes heavy use of C's conditional compilation to implement optional hardware support.
For instance, if a target processor has a special instruction for predecrement, the compiler defines HAVE_predecrement and during optimization and generation of code there are sequences such as:
#ifdef HAVE_predecrement /* Generate the predecrement instruction. */ #else /* Generate some less efficient sequence to implement predecrement. */ #endif
The problem with this sort of construct is the header file which defines HAVE_predecrement is not actually required to compile this code. In fact, it compiles fine, and worse yet, it executes with no errors!! The result is a less efficient executable is generated and a compiler can't really afford to have that happen. Besides, an important goal of the exercise is to have no effect on generated code.
The build tools for removing headers needed to be modified to analyze the macros that are produced and consumed in each file. If a header file appears to compile, it was analyzed to see if it produced or consumed something which was also used in conditional compilation... and not removed if this were the case.
I also used another tool to produce a recommended ordering for the most common header files. This tool would take a look at all the headers and their dependencies and come up with an optimal ordering of the most common 100 files or so. If header files occur in this order, all prerequisites would be minimally satisfied. There were also a few "optional" header files that would cause different behaviours if they occurred out of order. These were also integrated into the canonical ordering. This tool then imposed this ordering on every source file.
The list of exceptions and special cases that needed to be dealt with is fairly extensive, but none were as difficult as the ones I've mentioned so far. I also expect they would vary from project to project.
Wrap-up
This work was all driven as a per-requisite for a larger project which needed the compiler to be more modular. I have not pushed this throughout the entire compiler (yet), nor did I follow through each phase fully. I got far enough that it is sufficient to proceed with the module separation required for the compiler backend. The remaining bits would be less work to push through now, it just requires someone with the desire (or need) to pursue it. The law of diminishing returns is also at play. I initially focused on the most difficult files, and slowly spread to the easier ones. Many of the remaining files will have little to no effect on most ongoing work.
We are also considering leveraging the existing tools to make sure our header's do not slip back into such a terrible state again. We considered running them at some interval during the development cycle, or during every check-in, or via some other mechanism. No decision has been made as yet - the final bits were completed at the end of the most recent development cycle and it hasn't been an issue yet.
If you have a legacy project whose header files are causing modernization migraines, there is a cure! It takes time and can be tedious, but it is possible to incrementally improve the structure of a code base, even if it operates under a constant development/release schedule.
Last updated: March 16, 2018