
For the past three years, I have spent half of my work time on the MIR project. The goal is to create a universal lightweight Just-in-Time (JIT) compiler, and the project's cornerstone is a machine-independent medium-level intermediate representation (MIR). For more about the project, see my previous articles on Red Hat Developer:
So far, my work on the MIR project has focused on making a fast JIT compiler that generates decent machine code for a few major targets: x86-64 Linux and macOS, aarch64, s390x, riscv64 Linux, and ppc64 big- and little-endian Linux.
The project in its current state is a method JIT compiler that can be effectively used for statically typed programming languages such as C, which is the most widely used statically typed language. We've developed a C-language JIT based on the C-to-MIR compiler.
The original goal for the MIR project was to implement a better Ruby JIT compiler. (Specifically, I'm focusing on CRuby, the default Ruby interpreter, which is written in C.) Ruby is a very dynamic programming language—it is so flexible that you can even redefine the plus method for integer numbers.
To achieve better performance for dynamic programming languages, you need to follow program execution, make various assumptions from the execution, and generate code based on those assumptions. For example, you might find that a given plus operation in a given method has only integer operands. You can assume that this will always be the case and generate specialized plus operation code working only for integer operands.
You need to use different techniques to guarantee that your assumptions hold, such as implementing assumption checks or guards, or proving that on a given execution path the assumption is always true. If the guards find that the assumption is wrong, you need to switch to code that can work for any case. The process of switching from specialized code to general case code is frequently called deoptimization in the JIT context.
In this article, I'll discuss how I plan to support the generation of specialized and deoptimized code in MIR, and what support has already been implemented in the MIR project.
Note: Most JITs are specialized for specific languages: There's V8 for JavaScript, for instance, or luajit for Lua and PHP JIT for PHP. I am more interested in language agnostic support to facilitate the implementation of specialization and deoptimization in JITs for different dynamic programming languages. (See How the JIT compiler boosts Java performance in OpenJDK for more about deoptimization in a JIT compiler.)
Specialization and deoptimization in MIR
So that we can look specifically at specialization and deoptimization in the MIR compiler, I will use the following simplified code for the virtual machine (VM) instruction plus in the CRuby implementation:
if (FIXNUM_2_P(recv, obj) &&
BASIC_OP_UNREDEFINED_P(BOP_PLUS, INTEGER_REDEFINED_OP_FLAG)) {
res = rb_fix_plus_fix(recv, obj);
} else if (FLONUM_2_P(recv, obj) &&
BASIC_OP_UNREDEFINED_P(BOP_PLUS, FLOAT_REDEFINED_OP_FLAG)) {
res = DBL2NUM(RFLOAT_VALUE(recv) + RFLOAT_VALUE(obj));
} else if (SPECIAL_CONST_P(recv) || SPECIAL_CONST_P(obj)) {
...
} else if (RBASIC_CLASS(recv) == rb_cFloat && RBASIC_CLASS(obj) == rb_cFloat &&
BASIC_OP_UNREDEFINED_P(BOP_PLUS, FLOAT_REDEFINED_OP_FLAG)) {
...
} else if (RBASIC_CLASS(recv) == rb_cString && RBASIC_CLASS(obj) == rb_cString &&
BASIC_OP_UNREDEFINED_P(BOP_PLUS, STRING_REDEFINED_OP_FLAG)) {
...
} else if (RBASIC_CLASS(recv) == rb_cArray && RBASIC_CLASS(obj) == rb_cArray &&
BASIC_OP_UNREDEFINED_P(BOP_PLUS, ARRAY_REDEFINED_OP_FLAG)) {
...
} else {
.. // call of method implementing + for object recv
}
So, what's happening here? First, the code checks that operands are fixed numbers and that the plus method for integers is not redefined. If that is the case, the code implements the plus operation for fixed numbers. Otherwise, it makes analogous checks for floating point numbers, strings, and arrays. At the end, it calls the Ruby method implementing + for the object recv.
Fixed numbers (or fixnums) in CRuby are a subset of integers that can be efficiently supported by the target machine. Bigger numbers are represented as multi-precision numbers implemented by the GMP library.
All values in CRuby are represented by a machine word and tagged. For example, a fixnum always has 1 as the least significant bit of the word and a pointer to an object always has three (or two, on 32-bit targets) zero-least significant bits. So the macro FIXNUM_2_P is implemented as the following code:
(recv & obj & 1) == 1
And the fixnum plus operation looks like this, if we omit the code for checking overflow:
(long) recv + (long) obj - 1
Note: For further simplicity, in the next sections I will ignore checks for redefinition of the plus operation, such as the invocations of the macro BASIC_OP_UNREDEFINED_P in the above example.
Specialization based on profiling
Assume that we've checked the operand types of a particular plus operation and found so far that they have always been fixed numbers. In that case, we could generate the following:
if (!FIXNUM_2_P(v1, v2)) goto general_case;
res = rb_fix_plus_fix(v1, v2)
At first glance, it seems we didn't improve the code because the check (FIXNUM_2_P) is still present. But if we look at a sequence of several plus operations, v1 + v2 + v3 + v4, we'll have:
if (!FIXNUM_2_P(v1, v2)) goto general_case;
res = rb_fix_plus_fix(v1, v2)
if (!FIXNUM_2_P(res, v3)) goto general_case;
res = rb_fix_plus_fix(res, v3)
if (!FIXNUM_2_P(res, v4)) goto general_case;
res = rb_fix_plus_fix(res, v4)
A smart compiler could remove the last two FIXNUM_2_P checks. Unfortunately, neither GCC nor Clang can figure out that res always has 1 as the least significant bit. Therefore, these compilers do not know the last two FIXNUM_2_P checks should be removed. GCC's situation might change in the future with the full implementation of Project Ranger. (By the way, if the values were represented by a structure with two members, type and value, GCC/LLVM even now could figure out their types and remove the last two checks.)
Optimization with extended basic blocks
Even without removing the redundant checks, executing such specialized code is beneficial because compilers can successfully do other optimizations, such as removing redundant loads and stores. That's because such code forms specific regions called extended basic blocks (EBBs), and optimizing compilers work particularly well on such regions. Code like this also has much better code locality and branch prediction.
General case code
How might we implement the code labeled by general_case in the fixed number example? There are three possibilities:
- A transition of execution to the interpreter.
- A JIT compiler call to remove the specialized code generated for the Ruby method, then generate and use general code for the method VM instructions.
- A
gototo a particular location containing all code for all type cases of the method VM instructions.
As switching to the interpreter in CRuby is very expensive, it might be better to generate general case code at the same time as specialized code, along with gotos to the general code from the specialized code when the guards fail. After several executions of the gotos to the general case code, we could rebuild the entire method with the current profile info.
Properties for program variables
The MIR JIT compiler is not smarter than GCC or Clang, and it encounters the same problem of removing redundant checks for tagged values. To solve the problem, I am planning to introduce properties for program variables and MIR instructions, along with built-in C functions working with properties:
__builtin_prop_cond (cond, var1, property_const1, var2, property_const2, ...)
__builtin_prop_set (var, property_const)
Note: For brevity, I'll skip over a description of property support on the MIR level.
Properties are integer constants. We can use __builtin_prop_set to assign properties to program variables at a given execution point. Properties are propagated to other program variables through variable assignments.
When we cannot calculate the property of a program variable at a given execution point, the variable gets the zero property at that point. A zero property is an unknown property.
We can annotate plus code with the new built-in calls for properties describing program variable types as follows:
enum prop { unknown = 0, inttype, flotype, ... };
if (__builtin_prop_cond (FIXNUM_2_P(recv, obj), recv, intype, obj, intype)) {
res = rb_fix_plus_fix(recv, obj);
__builtin_prop_set (res, inttype)
} else if (__builtin_prop_cond (FLONUM_2_P(recv, obj), recv, flotype, obj, flotype))
res = DBL2NUM(RFLOAT_VALUE(recv) + RFLOAT_VALUE(obj));
__builtin_prop_set (res, flotype);
} else {
... // call of method implemented + for object recv
}
The following translated pseudocode illustrates the semantics of __builtin_prop_cond and __builtin_prop_set:
if (recv.prop == intype && obj.prop == inttype
|| (recv.prop == unknown && obj.prop == unknown) && FIXNUM_2_P(recv, obj)) {
res = rb_fix_plus_fix(recv, obj);
res.prop = intype;
} else if (__builtin_prop_cond (FLONUM_2_P(recv, obj), recv, flotype, obj, flotype))
res = DBL2NUM(RFLOAT_VALUE(recv) + RFLOAT_VALUE(obj));
__builtin_prop_set (res, flotype);
} else {
... // call of method implemented + for object recv
}
Because we always know properties during code generation, all assignments and comparisons of properties will go away in the final code. For example, if we figure out that recv and obj both have the property inttype, the final code will be:
res = rb_fix_plus_fix(recv, obj);
If we figure out during analysis that recv and obj both have the property flotype, the final code will be:
res = DBL2NUM(RFLOAT_VALUE(recv) + RFLOAT_VALUE(obj));
If the properties of values of recv and obj are zero, we will have the original code as before the annotation. If only one property of recv or obj is zero, we will have only the code in the final else part.
Consider the code after the profiling discussed above. The analogous code annotated with properties after profiling will look like this:
if (!__builtin_prop_cond (FIXNUM_2_P(v1, v2), v1, intype, v2, intype)) goto general_case;
res = rb_fix_plus_fix(v1, v2);
__builtin_prop_set (res, inttype);
if (!__builtin_prop_cond (FIXNUM_2_P(res, v3), res, intype, v3, intype)) goto general_case;
res = rb_fix_plus_fix(res, v3);
__builtin_prop_set (res, inttype);
if (!__builtin_prop_cond (FIXNUM_2_P(res, v4), res, intype, v4, intype)) goto general_case;
res = rb_fix_plus_fix(res, v4);
__builtin_prop_set (res, inttype);
...
It is now pretty easy to find and propagate properties of program variables for the extended basic block above. Property analysis is trivial for variables in MIR registers, while for variables represented by MIR memory operands it requires a more complex point-to analysis.
So the final code will be:
if (FIXNUM_2_P(v1, v2)) goto general_case;
res = rb_fix_plus_fix(v1, v2);
res = rb_fix_plus_fix(res, v3);
res = rb_fix_plus_fix(res, v4);
...
Note: For brevity, I am omitting a description of how to do the profiling, especially when code is executed in more than one thread.
Basic block versioning
What would happen for specialization based on profiling if, in the Ruby code v1 + v2 + v3 + v4 that we looked at earlier, all variables in half of all cases had fixnum values and in the other half had floating point number values? This is a common situation for a polymorphic function in dynamic programming languages.
We could generate specialized code only for one half of the cases and do the deoptimization when a case from the other half occurred. Or we might generate and use only general case code. If a particular call to some small function had specific type values in the majority of cases, we could improve the generated code by using code inlining. That's a complicated solution, however. A simpler approach to solve the problem is basic block versioning (BBV).
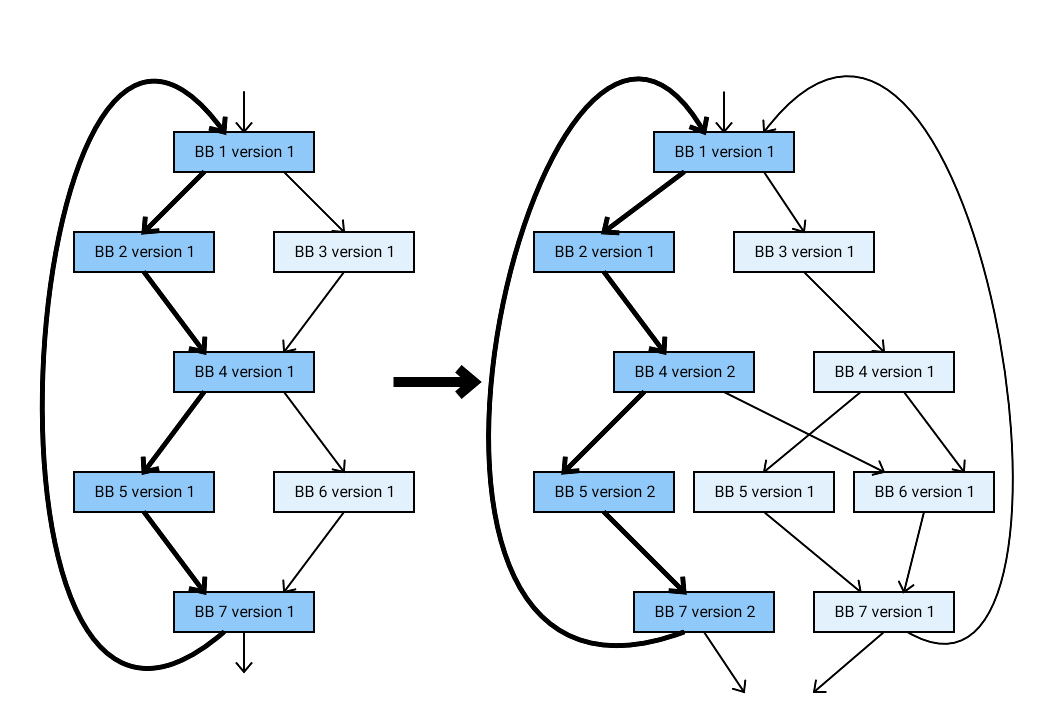
How does basic block versioning work? Suppose we have different paths to reach a basic block of our code (by different calls to a function, say), and on these different paths we have specific types (properties) of variables. We can clone the basic block and generate different versions of specialized code for different types of variables, as illustrated in Figure 1 (note that basic blocks are denoted as BB).

Creating a specialized basic block version can deduce types of outgoing variable values, like the value of res in our example. This in turn can result in the generation of different versions of successor basic blocks.
You can probably guess that if we don't constrain the number of basic block versions, a combinatorial explosion of different versions might arise. In practice, only a few versions of one basic block are generated, where one basic block version is always used for unknown types (zero properties).
Eager versus lazy basic block versioning
There are two ways to generate basic block versions. It can be done in an eager way or in a lazy way. In the eager strategy, when we generate code for a basic block version, we also create versions of successor basic blocks and generate code for them, and so on. In other words, we generate code for the whole method at once.
In the lazy strategy, we generate code for a basic block version only when we start execution of that version. This means that we generate code for method basic blocks that are actually executed in the program. Obviously, lazy basic block versioning results in less generated code and, usually, less compilation time. (If we need to generate code for the same number of basic block versions with both strategies, lazy code compilation would probably require more time because of more time spent for data initialization and finalization for each separate basic block code generation.)
Advantages of lazy basic block versioning
When compared to specialized code generation based on profiling, as described in the previous section, lazy basic block versioning has several advantages:
-
We don't need to do preliminary profiling to start generating specialized code.
-
We don't need to inline function calls to generate better specialized code.
-
We don't need to generate machine code for all BBs, which can be attractive when only a small part of the JIT'ed program is executed.
-
We don't need to do special implementation of deoptimization. It is automatically done through BB versioning.
-
Many method JITs generate code only for methods that were executed a number of times greater than some threshold. The execution is switched only at function calls. Such an approach does not work well if a method is called rarely but has a very long-running loop. Switching to new method code during method execution is called on-stack replacement (OSR). Lazy basic block versioning does not require a special implementation of OSR; it is done automatically.
One might think that basic block versioning results in an explosion in code size. In practice, the average number of versions is quite small. About 95 percent of basic blocks had only one version on a set of JavaScript benchmarks, according to a paper by Maxime Chevalier-Boisvert and Marc Feely (see Simple and Effective Type Check Removal through Lazy Basic Block Versioning).
When bootstrapping the x86-64 C-to-MIR compiler, which is about 30,000 lines of C code, the number of generated basic block versions is only 51 percent of all basic blocks of the compiler functions executed at least once (14,737 out of 29,131) and only 18 percent (14,737 out of 81,799) of all basic blocks of the compiler, as you can see in Figure 2.

It should come as no surprise that I started to implement lazy basic block versioning first for the MIR project.
Lazy basic block versioning in the MIR project
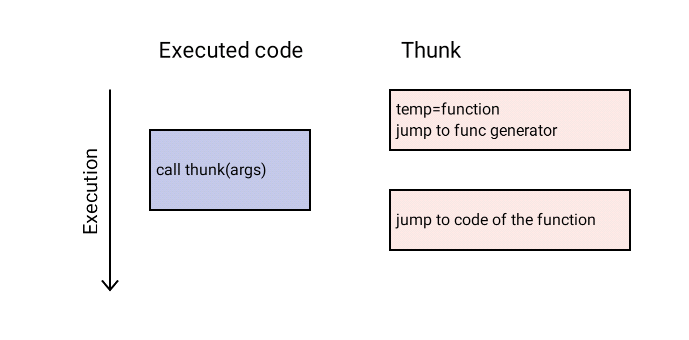
How is lazy basic block versioning implemented for the MIR project? All calls of MIR functions are indirect and implemented through small runtime-generated code snippets called thunks, which usually consist of one or two machine instructions. Thunks are used to easily change machine code for any MIR function; for instance, we need this for switching specialized machine code to deoptimized code.
MIR already has a lazy function code generation mechanism, which is also implemented through thunks. At the start of program execution, all function thunks redirect to the machine code generator. When a function is called for the first time, the MIR code generator optimizes the function and generates machine code for it; the function thunk is then redirected to the generated machine code and execution continues from the generated code, as shown in Figure 3.
When we use lazy block versioning, the function thunk implements a switch to a specific address that depends on the properties of program variables at the beginning of the basic block. The switch can be implemented in various ways—as a table-based switch, for instance. Any switch is less efficient than just the one jump instruction used previously. Still, we cannot use several simple jump thunks for one function instead of the switch, as we need to support a one-to-one relation between a function and its thunk. That is because a function in MIR is represented by its thunk address, and functions are first-class values that can be assigned and compared.
The function thunk for lazy basic block versioning redirects to a machine code generator of a basic block version or to already-generated machine code of that version. A function call also passes an identifier of the properties of call arguments through some register that is not saved by a called function according to the application binary interface (ABI) used.
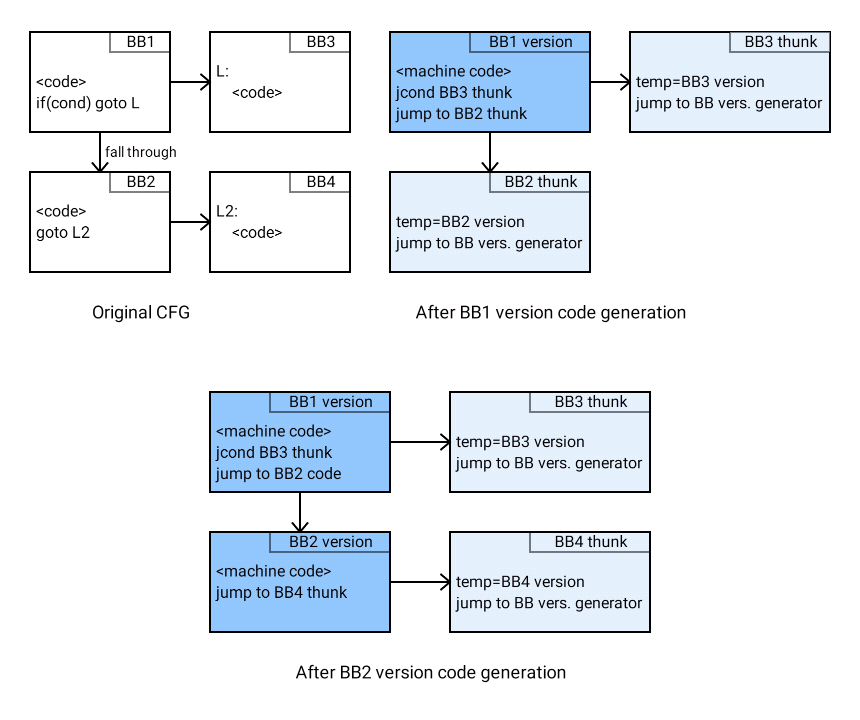
Initially, a function thunk redirects to a machine code generator, which works in a special mode. It only optimizes the function but does not generate machine code. Instead, it creates a version of the function's first basic block, redirects the function thunk to the basic block version generator, and calls it. The next calls modify the function thunk whenever a new basic block version is necessary. Figure 4 illustrates how the function thunk changes when the limit for the number of basic block versions is three.

The basic block version generator processes MIR property instructions optimizing code for the given properties, and generates machine code for the basic block. It finds successor basic blocks with properties at the end of the current basic block and adds jumps at the end of that basic block to the machine code of its successors.
If the basic block version generator can't find basic block versions of a basic block's successors, it creates them, along with their thunks. The generator adds jumps to the new thunks at the end of the machine code of the current basic block version and continues execution from the machine code of the current version. In rare cases, jumps through basic block versions can still be done through basic block thunks. This happens when, in the original basic block version, there's an indirect jump or MIR switch instruction with more than one case having the same target label.
Lazy basic block generation in YJIT and MIR
Lazy basic block generation in the MIR project was inspired by the recent Shopify YJIT for CRuby. But there are important differences between the two:
-
YJIT is a specialized CRuby JIT, whereas MIR is a universal JIT and can be used for JIT implementations of different languages.
-
A YJIT basic block is a CRuby VM instruction basic block, whereas a MIR basic block is a machine-instruction-level basic block.
-
YJIT does not do any optimization of basic block versions. The MIR generator optimizes the whole function first and individual basic block versions later.
-
YJIT only supports x86-64 code generation. MIR supports x86-64, aarch64, ppc64, s390, and 64-bit RISCV.
As you've seen, code generated with basic block versions contains more jumps than generated code for the entire function. But I did not find any performance difference on x86-64 machines (just some noise) with the benchmarks I use for the MIR and the C-to-MIR compilers. My guess is that direct jump instructions are probably low cost on modern processors, with their sophisticated branch prediction units, and any additional cost is compensated by better code locality produced by using basic block versions.
Tracing and meta-tracing in a JIT compiler
So far, I've described approaches to support the implementation of method JITs for dynamic programming languages. Lazy basic block code generation could be one step towards implementing a tracing JIT.
A tracing JIT records VM instructions that are usually executed in a hot loop, optimizes them, and generates machine code for them. The block diagram on the left side of Figure 6 shows an example of a loop execution, with the most frequently executed blocks filled with a darker color.
As shown in Figure 6, we cannot optimize BB4 in the context of the previously executed BB1 and BB2, as there is an entrance from BB3 too. When we modify the loop by duplicating basic blocks on the hot path, as shown on the right side of the figure, we can optimize the duplicated blocks BB4, BB5, and BB7, which might result in code that performs much better.
Basic block versioning can be used as a mechanism for basic block duplication on a hot path. To implement a tracing JIT for MIR, we could generate code for counting the number of executions of each basic block. When the counter exceeds some threshold on a loop header, we could find the hottest path, duplicate basic blocks on the path to make an extended basic block (EBB) if necessary, and generate optimized code for that.
What about a meta-tracing JIT?
We can go further than tracing JIT support and create a meta-tracing JIT. A meta-tracing JIT generates machine code by tracing an interpreter of a programming language. It is a very attractive approach for JIT implementation because you only need to implement the interpreter.
The most famous example of a meta-tracing JIT is PyPY. PyPY is written in RPython, a restricted form of Python where the types of variables are inferred at compile time.
We don't actually need to implement a tracing JIT before we can create a meta-tracing JIT. Basic block versioning is enough for this. However, implementing a tracing JIT improves the performance of the meta-tracing JIT. A method JIT can optimize code in method scope; a meta-tracing JIT without tracing can optimize code only for the few basic blocks used to implement one VM instruction in the interpreter.
A meta-tracing JIT for MIR
To implement a meta-tracing JIT for MIR, I would need to use non-constant property and add a new property MIR instruction and a new built-in for the C-to-MIR compiler:
__buitin_bb_indirect_jump(id, addr)
Here, id is an identifier provided by us (known only at execution time) of the version of the basic block where the built-in call occurs. This identifier should be the same for every execution of the same basic block version. And addr should be the same for the same id at any given call of this built-in. This built-in function creates target basic block versions for each unique id.
Typically, a fast interpreter is implemented through direct threading using the C extension Labels as Values. In such implementations, the interpreter code responsible for an instruction's execution looks like this:
plus_insn_label:
<code executing insn>
pc += insn1_length;
goto byte_code[pc];
...
minus_insn_label:
...
Here, pc is a variable pointing to the currently interpreted instruction and byte_code contains instructions represented as the addresses of labels (e.g., minus_insn_label) of interpreter code responsible for executing each instruction (e.g., minus), followed by the instruction operands.
A meta-tracing JIT can be created by using built-in function calls instead of gotos to label values as follows:
plus_insn_label:
<code executing insn>
pc += insn1_length;
__buitin_bb_indirect_jump(pc, byte_code[pc])
...
minus_insn_label:
...
When the interpreter starts, it will create a basic block version for each unique pc—in other words, for each executed instruction in the bytecode. If we also use properties, we might have more than one basic block version for each unique pc value.
Meta-tracing in MIR versus RPython
Meta-tracing in MIR has the potential to be more widely used than the RPython meta-tracing JIT compiler because C is more widely used and known than RPython. People could start to implement an interpreter in C and automatically implement a JIT by using MIR's meta-tracing JIT. You only need to annotate interpreter code in C for this.
Implementing a meta-tracing JIT in the MIR project is a very attractive goal, but it will require a lot of effort to reach it. Still, it is good to have a plan and design for achieving it.
Aliasing in a JIT compiler
For generating better JIT code, it is important to know whether two particular memory accesses refer to the same or different memory locations. This information can be obtained by alias analysis or point-to analysis.
The most widely used alias analysis in C is type-based alias analysis. For example, according to a few recent C standards, pointers of integer and floating point types should always refer to different memory locations.
The CRuby interpreter accesses local variables and temporary values through the pointers ep (the environment pointer) and sp (the stack pointer) respectively. These pointers never refer to the same location during Ruby method execution, as you can see in Figure 7.
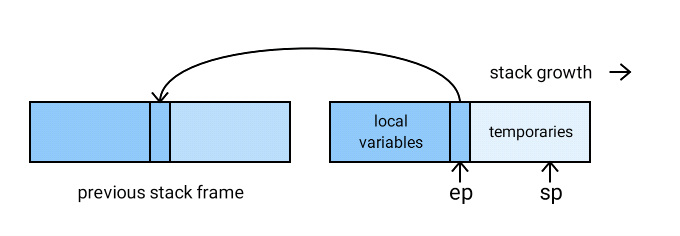
But both pointers have the same type VALUE *:
struct rb_control_frame_struct {
VALUE *sp;
...
VALUE *ep;
...
}
Type-based analysis cannot figure out that both pointers refer to different locations. Even the sophisticated point-to analysis in GCC and Clang can't figure this out.
MIR has alias support, which can describe both existing type-based aliasing and the desirable memory aliasing in the above example. In the C-to-MIR compiler, the distinction between ep and sp can be described by the following C extension:
struct rb_control_frame_struct {
VALUE *sp __attribute__ ((antialias ("var_vs_temp"));
VALUE *ep __attribute__ ((antialias ("var_vs_temp"));
}
Pointers marked with an antialias attribute using the same name must never refer to the same memory. The MIR generator can use this alias information to remove redundant loads and dead stores, and to perform better constant propagation. This is important for better JIT code generation, as a typical method execution contains a sequence of interleaving accesses to local variables and temporaries.
Conclusion
In this article, you learned about different ways to facilitate implementation of better-performing JITs for dynamic programming languages:
- Profiling and specialized code generation
- Lazy basic block versioning
- Tracing and meta-tracing
- Aliasing
You also saw extensions on the C and MIR level to support implementation of better performing JITs based on the MIR project.
Currently, lazy block versioning is only partially implemented in MIR and in the C-to-MIR compiler. Its initial implementation (for x86-64 only) can be found in the project's GitHub repository.
This implementation opens the way for implementing tracing JITs. But the ultimate goal for me would be a meta-tracing JIT whose implementation language is C.
A MIR-based meta-tracing JIT would be particularly attractive, as it would require JIT developers only to write the interpreter in C and annotate the C code for better-performing JIT generation, or even just annotate an existing interpreter written in C.
Last updated: August 26, 2022