Welcome to the part 2 of Red Hat JBoss Data Virtualization (JDV) running on OpenShift.
JDV is a lean, virtual data integration solution that unlocks trapped data and delivers it as easily consumable, unified, and actionable information. JDV makes data spread across physically diverse systems such as multiple databases, XML files, and Hadoop systems appear as a set of tables in a local database.
When deployed on OpenShift, JDV enables:
- Service enabling your data
- Bringing data from outside to inside the PaaS
- Breaking up monolithic data sources virtually for a microservices architecture
Together with the JDV for OpenShift image, we have made available OpenShift templates that allow you to test and bootstrap JDV.
Introduction
In part 1 we described how to get started with JDV running on OpenShift. During the build phase of the pod several artifacts were downloaded from the provided GitHub URL in the JDV OpenShift template. We deployed two virtual databases (VDBs) called country-ws (external web service-based datasource) and marketdata-file (file-based datasource).
![]() A VDB is a container for components that integrate data from multiple disparate data sources, allowing applications to access and query the data as if it is in a single database and, therefore, using a single uniform API.
A VDB is a container for components that integrate data from multiple disparate data sources, allowing applications to access and query the data as if it is in a single database and, therefore, using a single uniform API.
A VDB is composed of various data models and configuration information that describes which data sources are to be integrated and how. In particular, source models are used to represent the structure and characteristics of the physical data sources, and view models represent the structure and characteristics of the integrated data exposed to applications.
This article will show the out-of-the-box user-experience to query the data from the JDV instance running inside the OpenShift pod through OData REST services. REST is commonly used by companies that have implemented service-oriented architectures. However, it does not provide unified calling semantics nor does it provide a data model, meaning that each company has needed to define its own. OData is a solution to this problem because it provides a specification that defines standard ways to define data source operations and also standardizes the way in which you define your data schema.
OData
 The Open Data Protocol (OData) is a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today. OData does this by applying and building upon Web technologies such as HTTP, Atom Publishing Protocol (AtomPub) and JSON to provide access to information from a variety of applications, services, and stores. OData is used to expose and access information from a variety of sources including, but not limited to, relational databases, file systems, content management systems and traditional Web sites. OData is consistent with the way the Web works, it makes a deep commitment to URIs for resource identification and commits to an HTTP-based, uniform interface for interacting with those resources (just like the Web). This allows OData to enable a new level of data integration and interoperability across a broad range of clients, servers, services, and tools. JDV 6.3 supports OData v2 and v4.
The Open Data Protocol (OData) is a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today. OData does this by applying and building upon Web technologies such as HTTP, Atom Publishing Protocol (AtomPub) and JSON to provide access to information from a variety of applications, services, and stores. OData is used to expose and access information from a variety of sources including, but not limited to, relational databases, file systems, content management systems and traditional Web sites. OData is consistent with the way the Web works, it makes a deep commitment to URIs for resource identification and commits to an HTTP-based, uniform interface for interacting with those resources (just like the Web). This allows OData to enable a new level of data integration and interoperability across a broad range of clients, servers, services, and tools. JDV 6.3 supports OData v2 and v4.
For more information on
- OData v2 see http://www.odata.org/documentation/odata-version-2-0/
- OData v4 see http://www.odata.org/documentation/
Accessing data via OData
JDV can expose any data source as an OData-based service out-of-the-box. During the deployment phase as explained in part 1 the following routes are created as depicted in the image below.
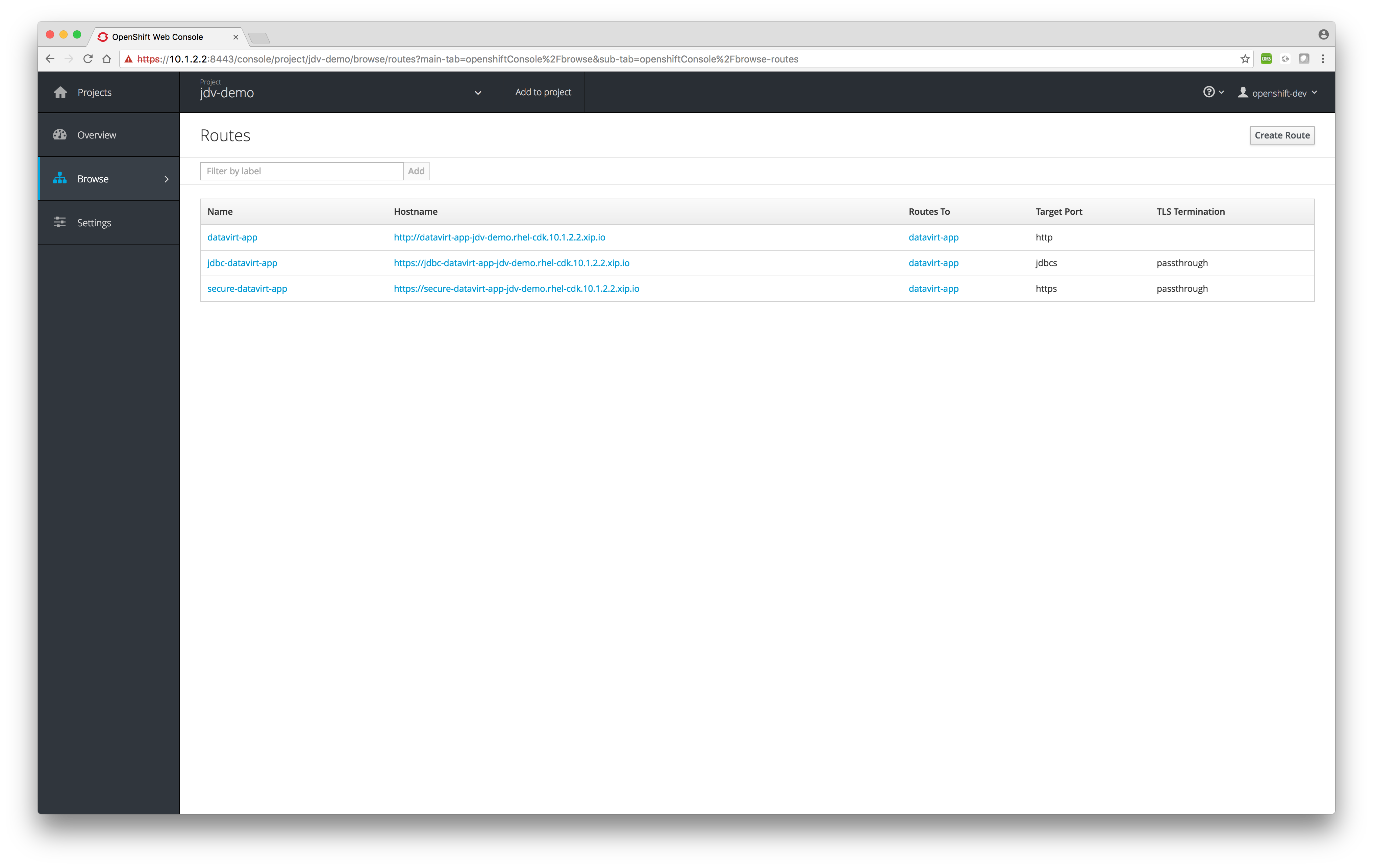
An OpenShift route exposes a service as a host name, like datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io, so that external clients can reach it by name.
OData-based services in JDV can be accessed either through http or https. When the pod including the JDV artifacts (i.e. VDB) has been successfully deployed and is running, the OData protocol support is implicitly provided by JDV without any further configuration/development.
Now, open up a browser and point it to the following OData URLs which are out-of-the-box available for your convenience.
Note: If you are requested to type in a username/password enter teiidUser/redhat1! or the combination you have used during the configuration of the JDV template of project jdv-demo in part 1.
OData v2
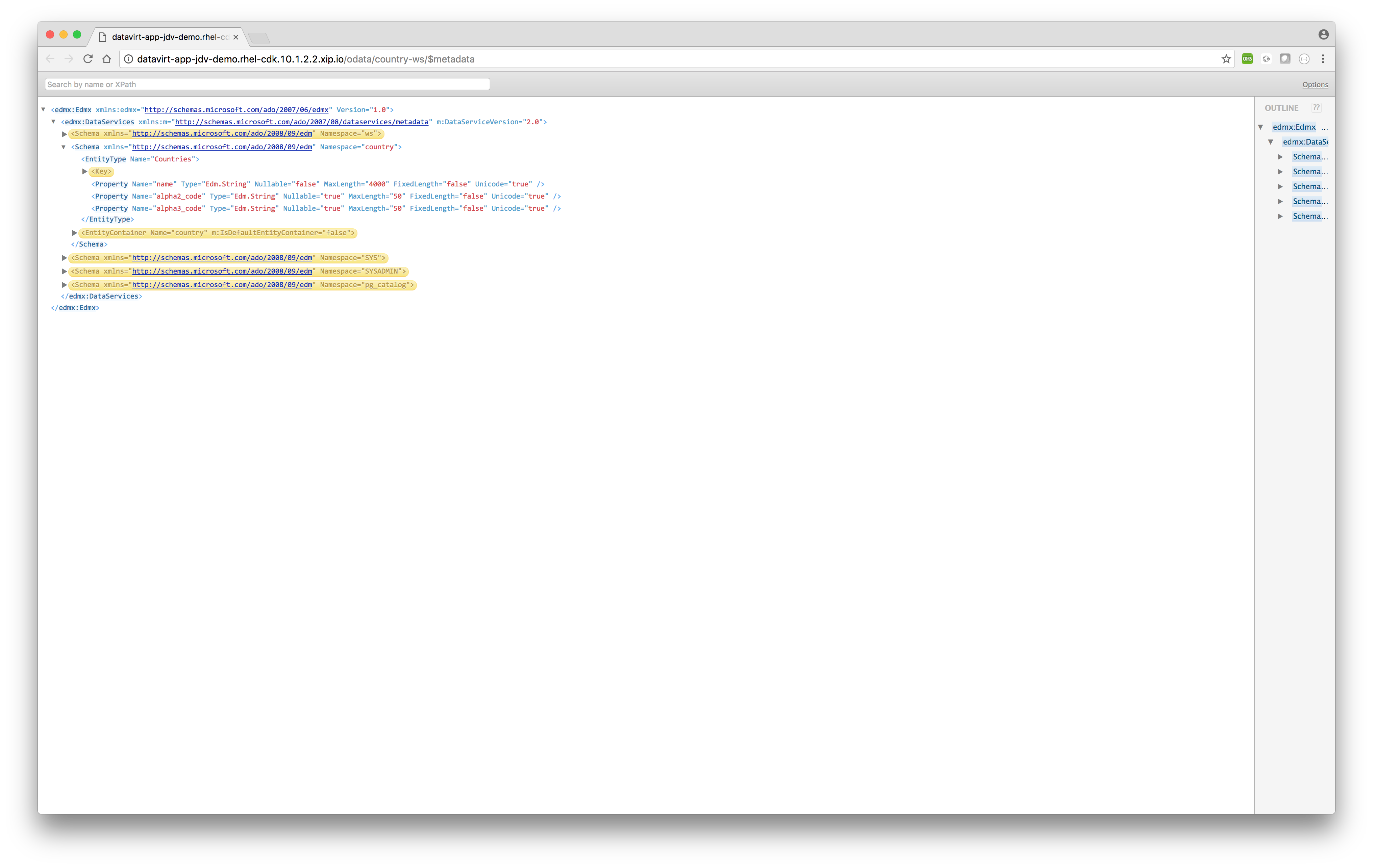
- Metadata
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata/country-ws/$metadataSQL equivalent> SQL varies per database vendor
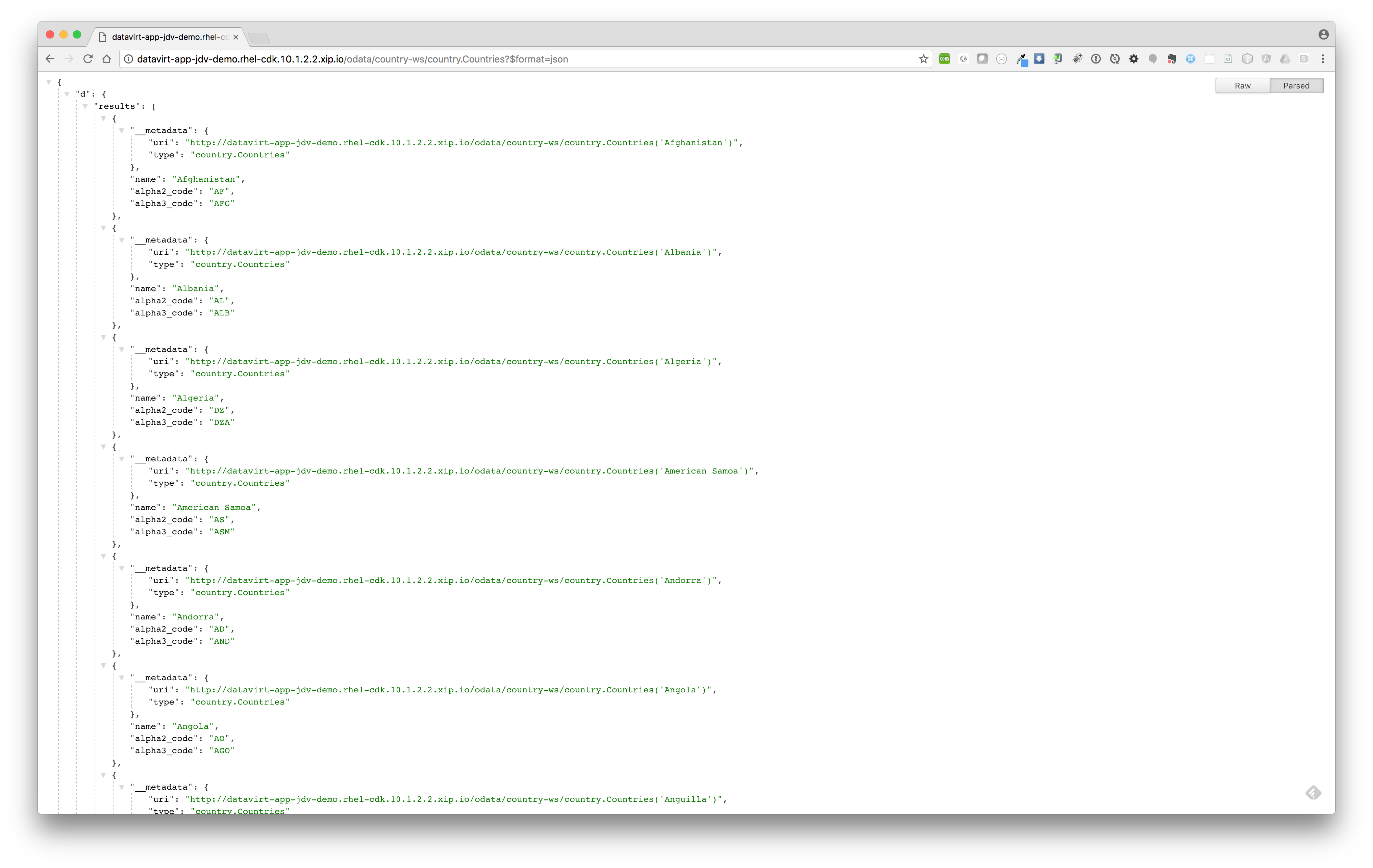
- Querying data
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata/country-ws/country.Countries?$format=jsonSQL equivalent> select * from country.Countries;
- Querying data on primary key
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata/country-ws/country.Countries('Zimbabwe')?$format=jsonSQL equivalent> select * from country.Countries where name='Zimbabwe';

- Querying data and returning specific fields
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata/country-ws/country.Countries?$select=name&$format=jsonSQL equivalent> select name from country.Countries;

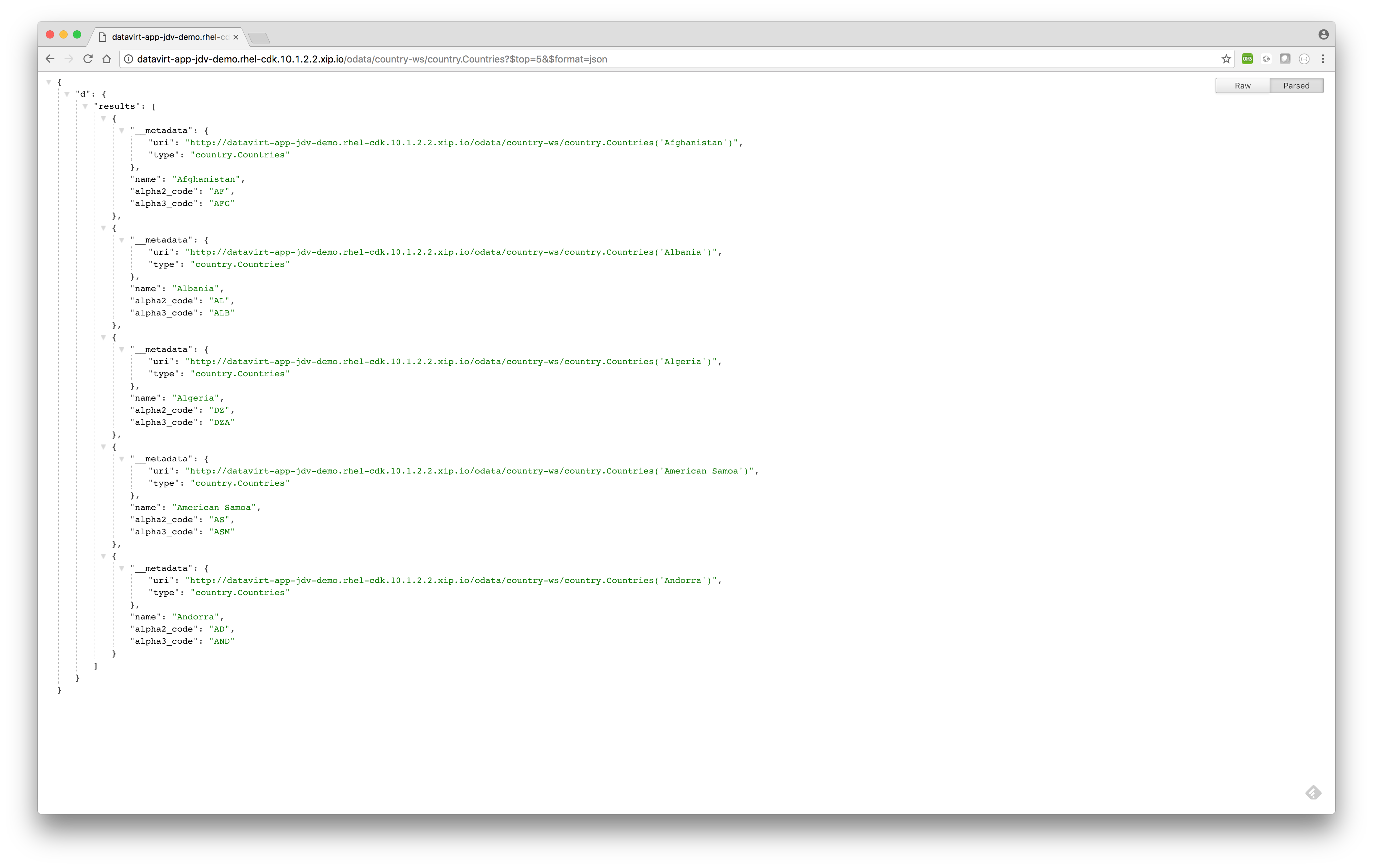
- Querying data and show top 5 results
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata/country-ws/country.Countries?$top=5&$format=jsonSQL equivalent> select * from country.Countries top 5;
OData v4
- Metadata
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata4/country-ws/country/$metadataSQL equivalent> SQL varies per database vendor
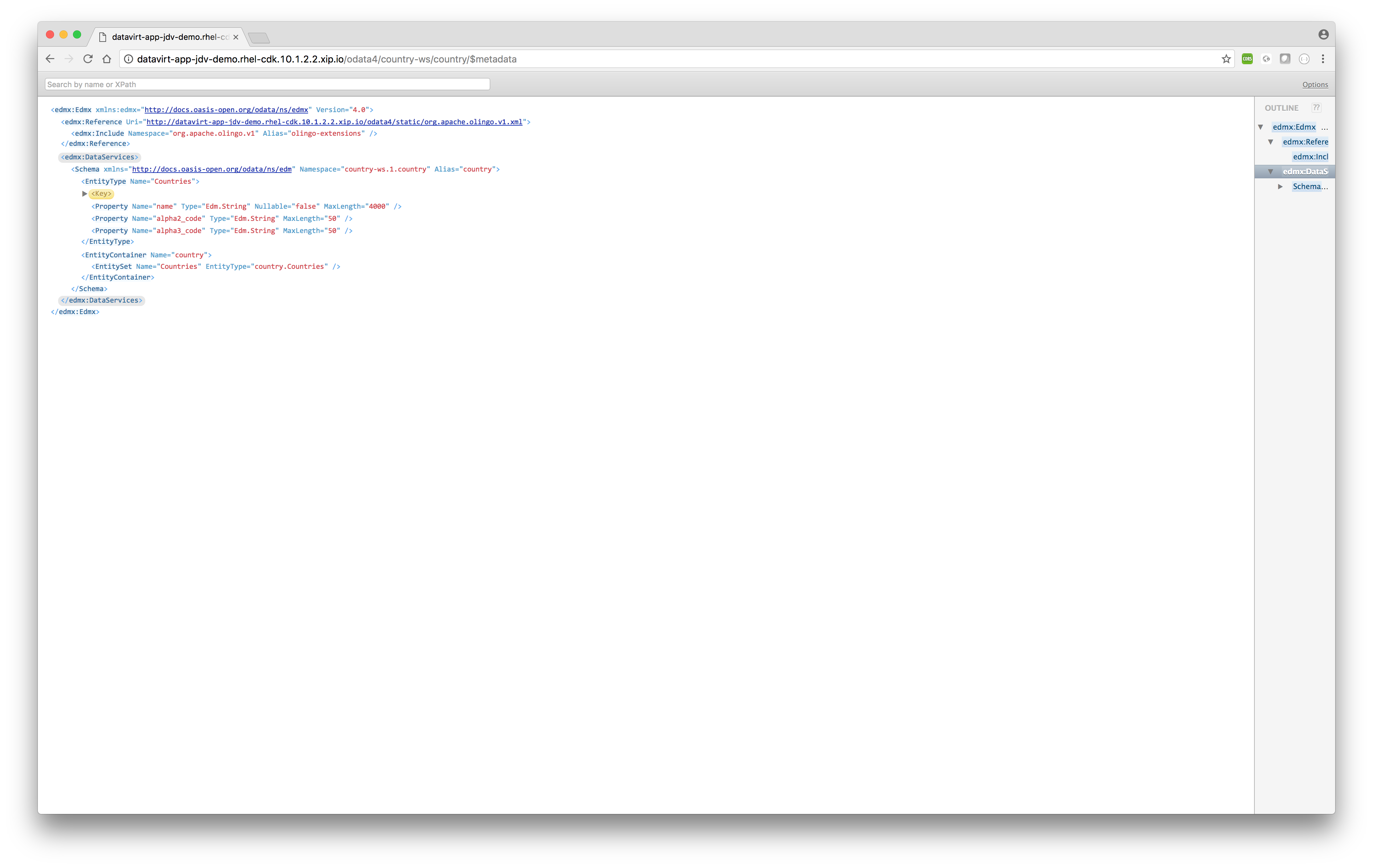
- Querying data
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata4/country-ws/country/Countries?$format=jsonSQL equivalent> select * from country.Countries;
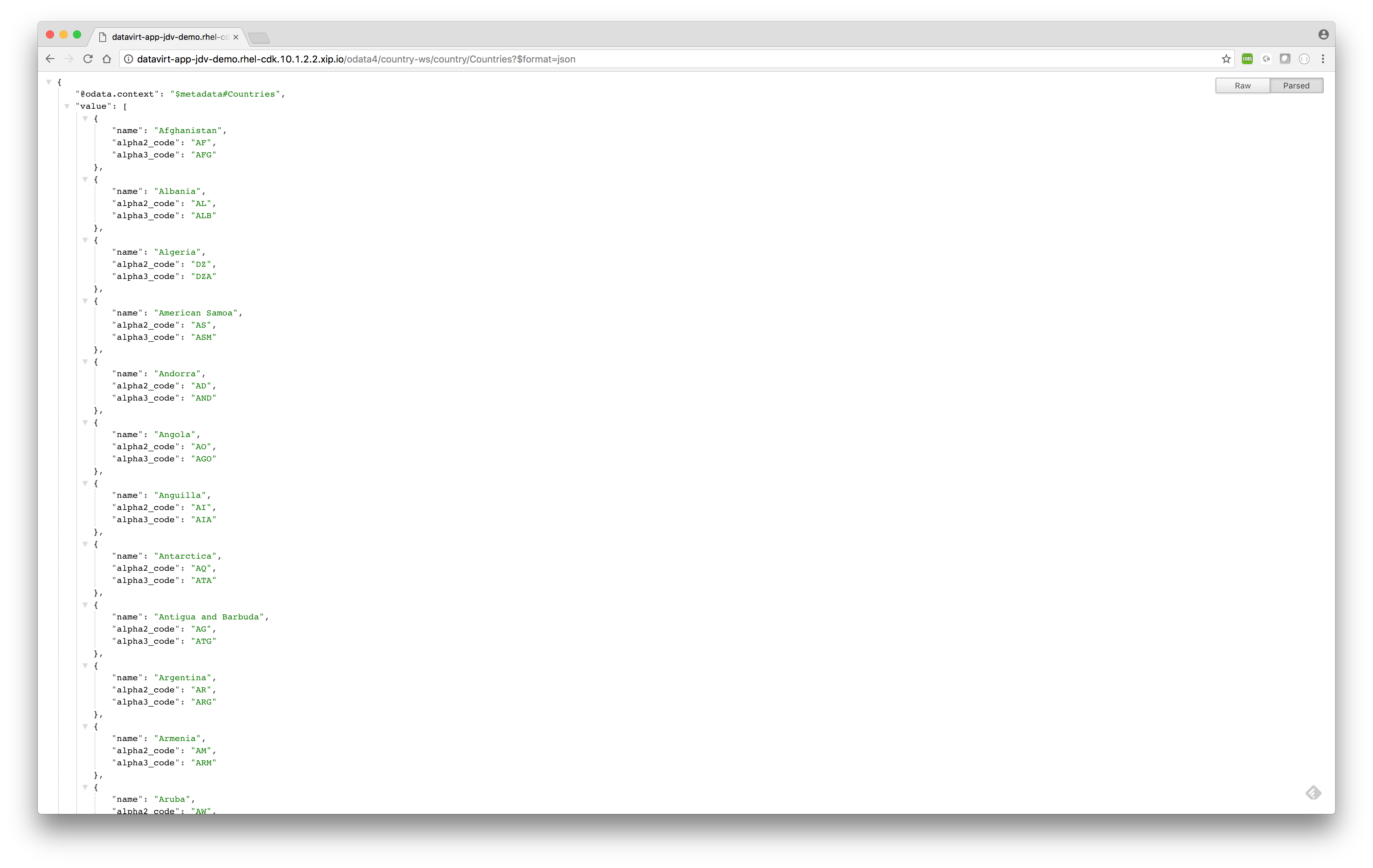
- Querying data on primary key
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata4/country-ws/country/Countries('Zimbabwe')?$format=jsonSQL equivalent> select * from country.Countries where name='Zimbabwe';
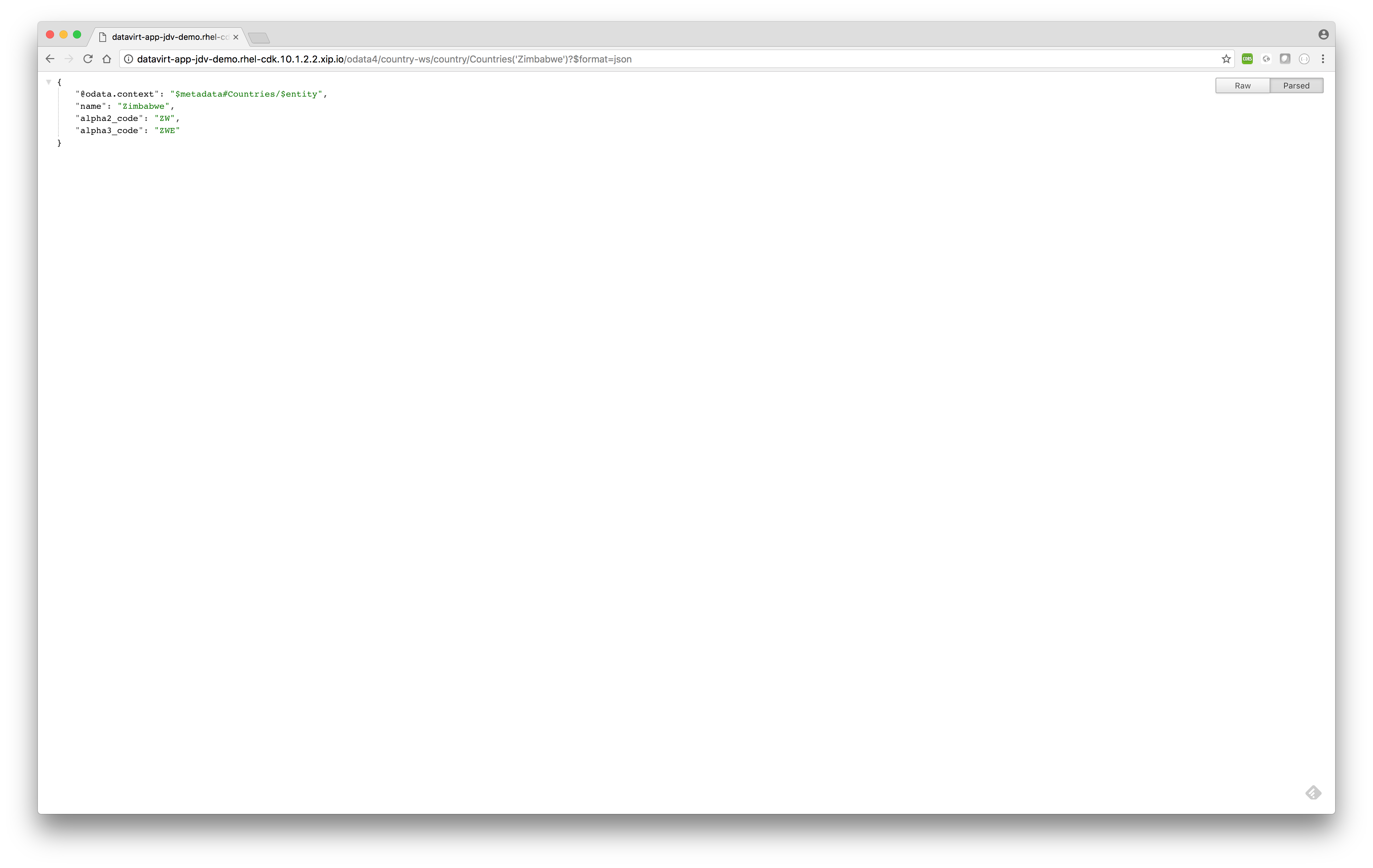
- Querying data and returning specific fields
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata4/country-ws/country/Countries?$select=name&$format=jsonSQL equivalent> select name from country.Countries;
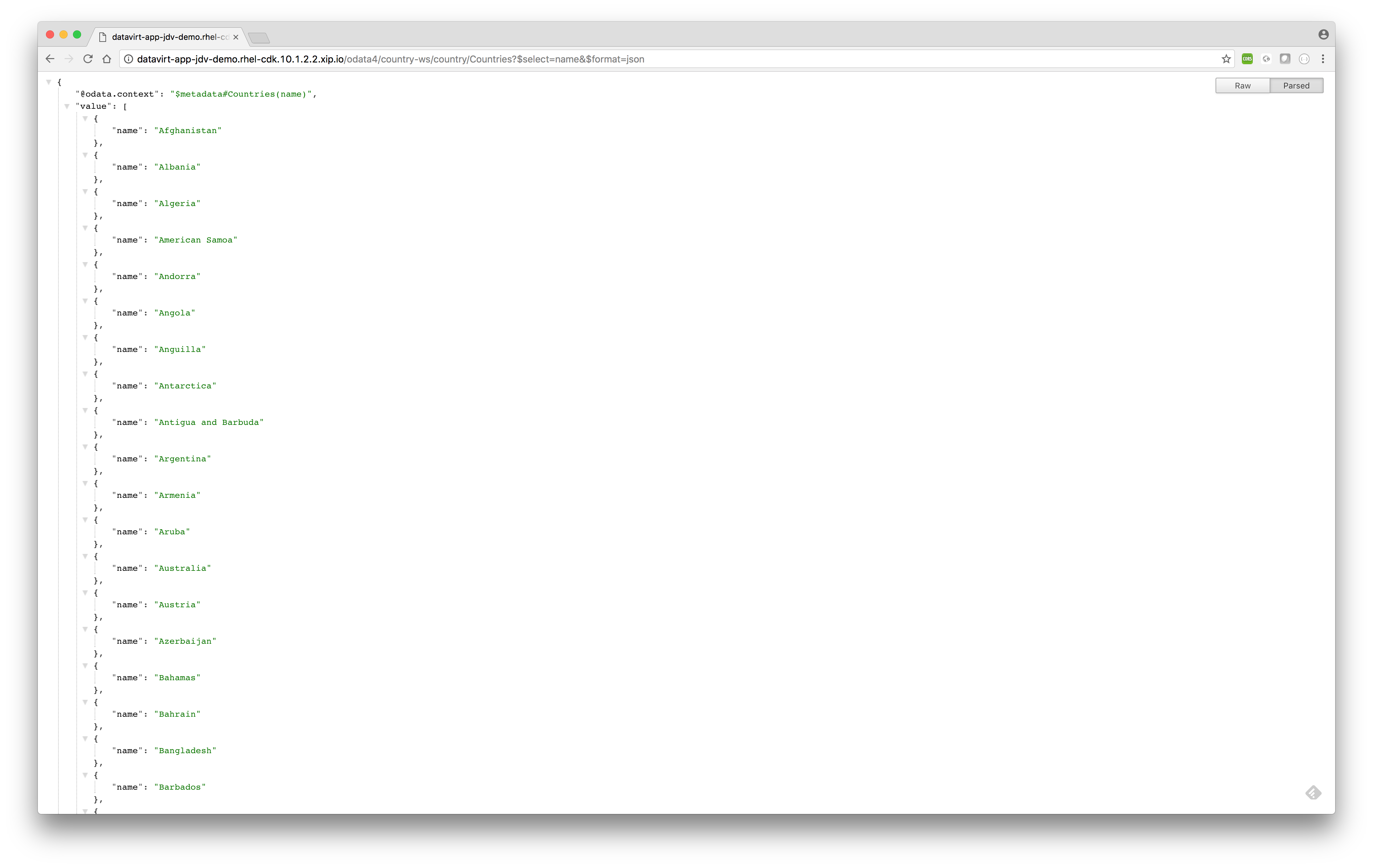
- Querying data and show top 5 results
http://datavirt-app-jdv-demo.rhel-cdk.10.1.2.2.xip.io/odata4/country-ws/country/Countries?$top=5&$format=jsonSQL equivalent> select * from country.Countries top 5;
The returned results from OData query can be in Atom/AtomPub XML format or JavaScript Object Notation (JSON) format. Default AtomPub based XML result is returned, by specifying the $format=JSON parameter in the OData URL the results will be returned in JSON output format.
Demonstration
In the following video we will show the above steps on how to connect to VDBs with financial information (file) and country information (web service) in OpenShift using the OData API provided out-of-the-box by JDV. In part 1 we deployed two VDBs called country-ws and marketdata-file. These VDBs were extracted from the github repository (https://github.com/cvanball/jdv-ose-demo/) using the templates variables
- GitHub repository URL: https://github.com/cvanball/jdv-ose-demo)
- Context directory: vdb.
These VDBs were downloaded and deployed during the build and deployment process of the pod.
Red Hat JBoss Data Virtualization on OpenShift: Part 2 - Service enable your data from Cojan van Ballegooijen on Vimeo.
Conclusion
You can leverage these OData-based REST services provided out-of-the-box by JDV running on OpenShift to integrate these data services with your existing applications and infrastructure like:
- API Management
- Enterprise Service Bus
- Mobile applications
- Web applications
- etc.
Resources
- Red Hat JBoss Data Virtualization on OpenShift: Part 1 – Getting started
https://developers.redhat.com/blog/2016/12/06/red-hat-jboss-data-virtualization-on-openshift-part-1-getting-started/ - Red Hat JBoss Data Virtualization on OpenShift: Part 3 – Data federation
https://developers.redhat.com/blog/2016/12/14/red-hat-jboss-data-virtualization-on-openshift-part-3-data-federation/ - Red Hat JBoss Data Virtualization on OpenShift: Part 4 – Bringing data from outside to inside the PaaS
https://developers.redhat.com/blog/2017/01/26/red-hat-jboss-data-virtualization-on-openshift-part-4-bringing-data-from-outside-to-inside-the-paas - OData
http://www.odata.org - JSON
http://www.json.org/ - AtomPub
https://tools.ietf.org/html/rfc5023 - OpenShift Documentation
https://docs.openshift.com/index.html - JDV for OpenShift image
Red Hat JBoss Data Virtualization for OpenShift image - JDV for OpenShift templates
https://github.com/jboss-openshift/application-templates/tree/master/ - JDV for OpenShift runtime artifacts used in this example
https://github.com/cvanball/jdv-ose-demo - Documentation
https://access.redhat.com/products/ - Red Hat Container Catalog
https://access.redhat.com/containers - OpenShift Container Tested Integrations
https://access.redhat.com/articles/2176281 - Red Hat JBoss Data Virtualization
http://developers.redhat.com/products/datavirt - OpenShift
http://www.openshift.com
